안녕하세요. 지난 포스팅의 [IC2D] GhostNetV2: Enhance Cheap Operation with Long-Range Attention (NIPS2022)에서는 기존의 GhostNet을 발전시켜 FC layer 기반의 DFC Attention을 제안한 GhostNetV2를 소개하였습니다. 오늘은 TinyViT, MobileViT, NASViT에 이어 새로운 efficient ViT인 EfficientFormer에 대해 소개하도록 하겠습니다.
Background
최근 CNN에 이어 Transformer는 self-attention을 통해 global dependency 또는 long-range dependency를 추출할 수 있다는 장점을 통해 엄청난 인기를 가지게 되었습니다. 특히, 영상 분류에서의 ViT (ICLR2021), Swin Transformer (ICCV2021), CSWin Transformer (CVPR2022) 그리고 객체 탐지에서의 DETR (ECCV2020), 의미론적 영상 분할에서의 SegFormer (NIPS2021), 마지막으로 비디오 처리 분야에서의 TimeSFormer (ICML2021) 등이 있었죠. 하지만 이러한 모델들은 너무나도 큰 대규모 모델 크기과 높은 사전학습 비용으로 인해 mobile이나 IoT 계열과 같이 컴퓨팅 리소스가 제한되는 경우에 활용하기 어렵다는 문제점이 있었죠.
이러한 문제를 해결하기 위해 CNN과 유사하게 효율적인 모델들이 나오기 시작하였습니다. 대표적으로 TinyViT, MobileViT, NASViT 등이 있었죠. TinyViT는 knowledge distillation, MobileViT는 새로운 DDP 학습 방법과 함께 convolution을 함께 결합, 그리고 NASViT는 LeViT를 기반으로 하는 search space를 이용해서 NAS를 통해 efficient한 모델을 설계하였습니다.
오늘 설계할 EfficientFormer 역시 NAS를 이용해서 efficient한 모델을 설계하였습니다. 다만 NASViT는 supernet 기반의 NAS가 subnetwork 들간의 gradient conflict가 발생하여 CNN (AlphaNet)을 위한 NAS를 바로 적용하는 것으로 인한 성능 감소를 해결하고자 하였습니다. 하지만, EfficientFormer는 Transformer 기반 모델들에서 특정 모바일 디바이스를 기준으로 어떤 연산에서 speed bottleneck이 생기는 지 확인하고 모델을 설계하였습니다.
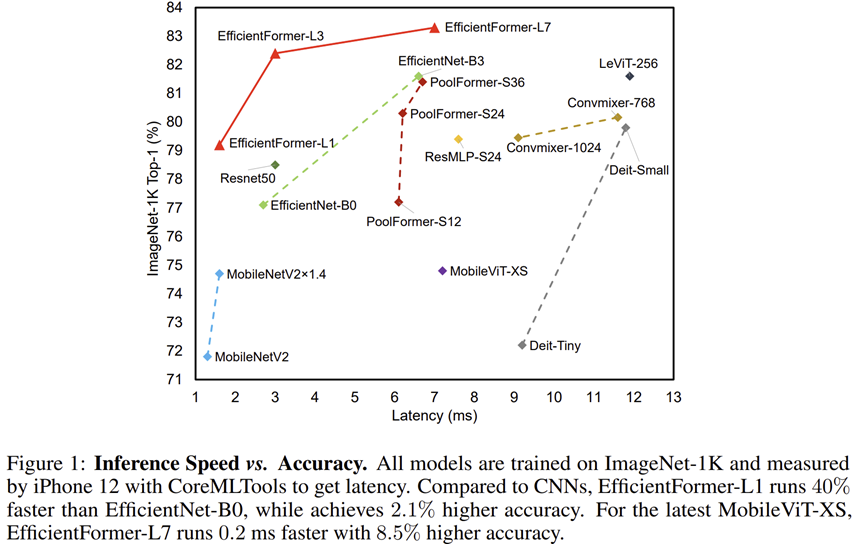
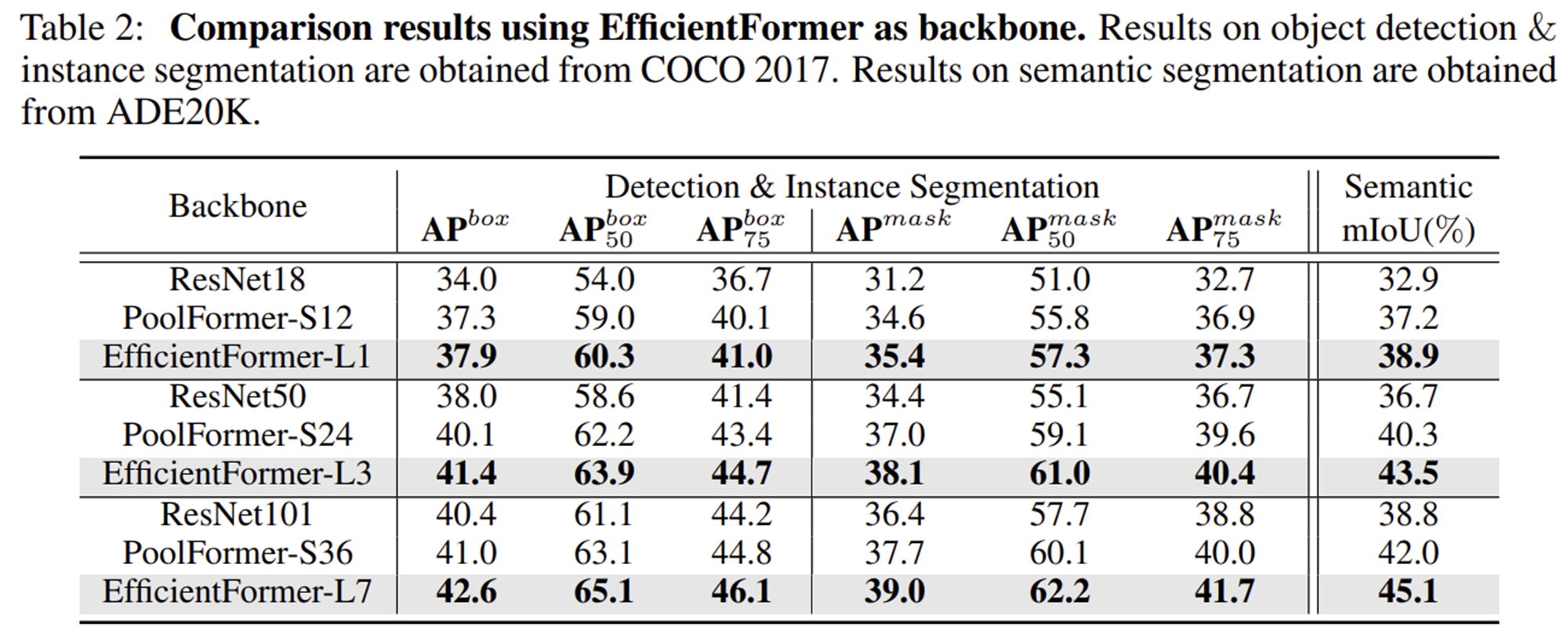
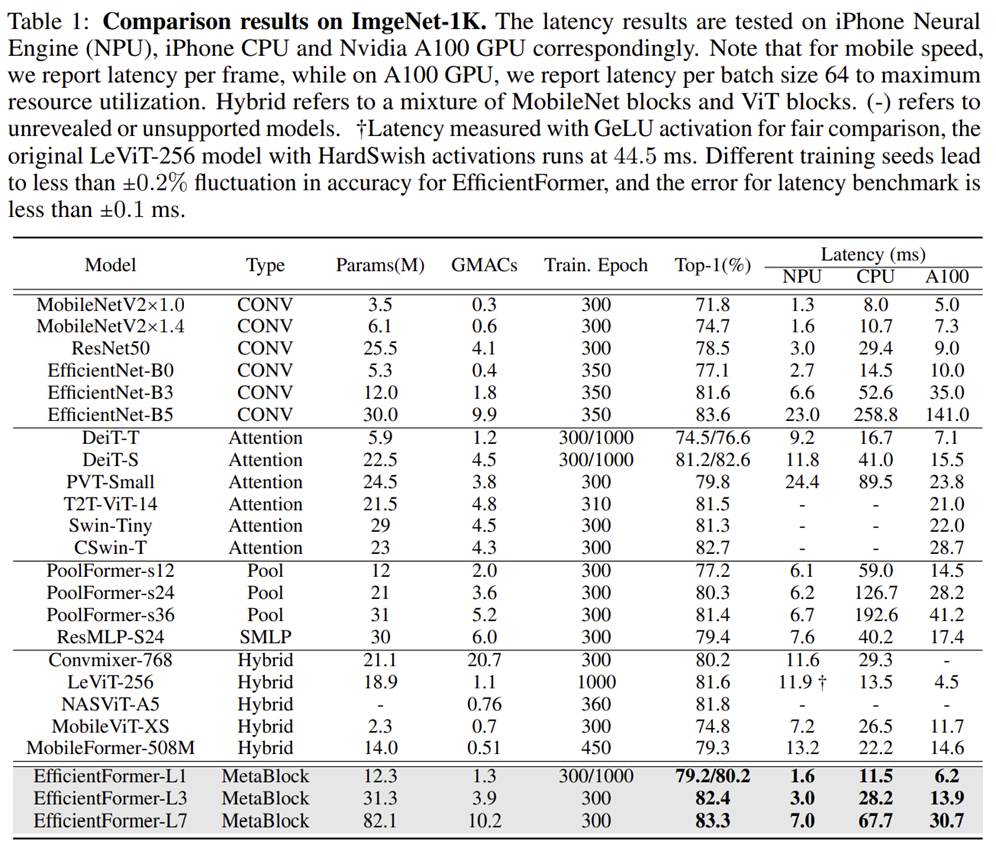
설계된 모델인 EfficientFormer들은 실제로 저희가 지금까지 보았던 모델들과 비교했을 때 훨씬 적은 latency임에도 불구하고 높은 정확도를 가지는 것을 볼 수 있죠. 특히, MobileViT와 비교했을 때 0.2 ms 속도가 더 빨라졌지만 8.5%나 더 높은 성능을 달성하였습니다. 그리고 MobileNetV2과도 비교했을 때 거의 동일한 latency임에도 불구하고 4~5%의 성능 향상을 달성한 것을 볼 수 있습니다.
On-Device Latency Analysis of Vision Transformer
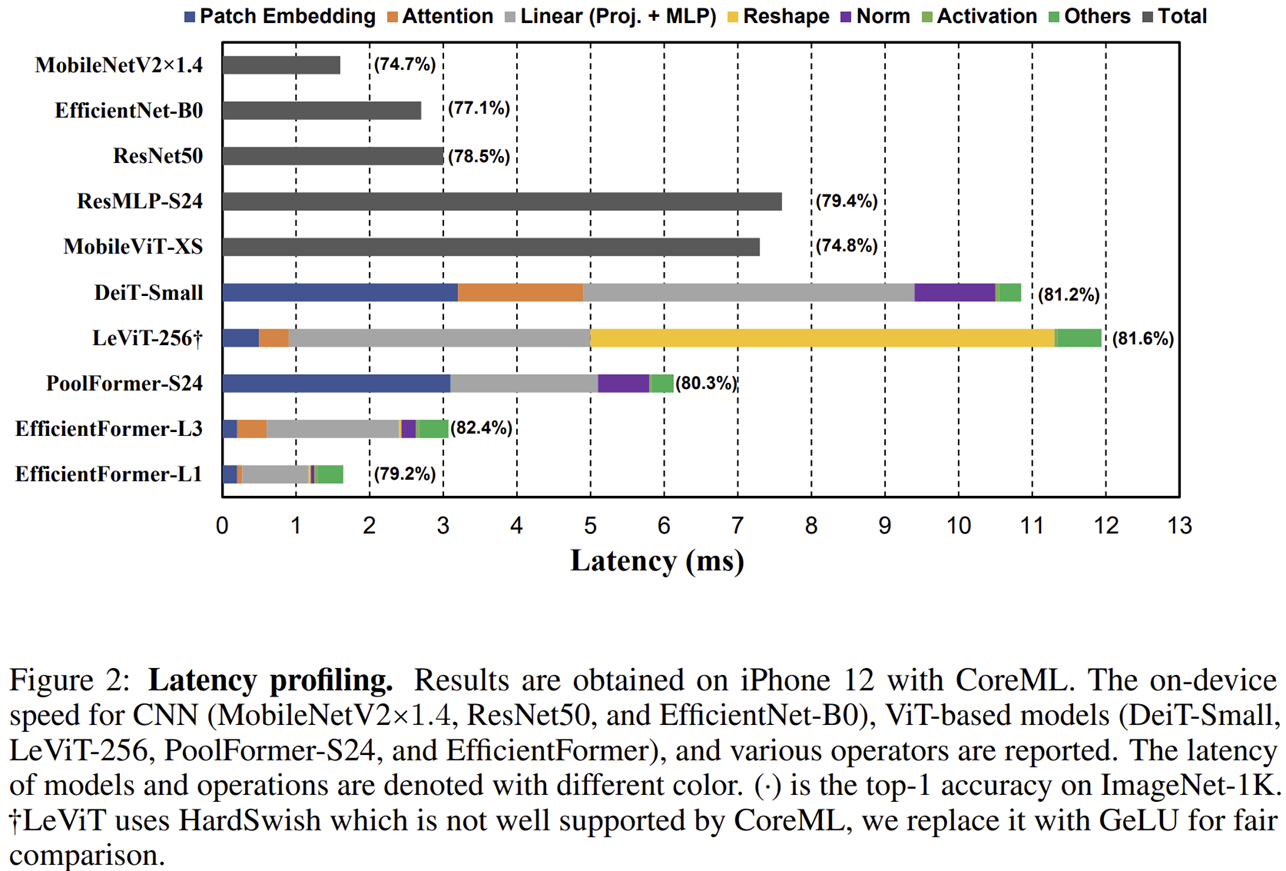
그림 2는 CNN을 포함하여 ViT 계열 모델들의 latency profiling를 보여주고 있습니다. 본 논문에서 관찰한 점을 보고 어떤 부분에서 latency가 크게 증가하는 지 분석해보도록 하겠습니다.
Observation 1: Patch embedding with large kernel and stride is a speed bottleneck on mobile devices.
일반적으로 ViT 관련 모델들에서는 공통적으로 patch embedding 자체는 크게 연산량을 요구하지 않는다는 이야기를 하였습니다 (ViT, MetaFormer). 하지만, DeiT vs. PoolFormer 그리고 LeViT vs. EfficientFormer를 확인해보면 patch embedding이 mobile에서 생각보다 높은 연산량이 요구되는 것을 볼 수 있습니다.
이는 큰 크기의 kernel size를 사용했을 때 convolution operation의 연산을 최적화시키는 알고리즘 ( Winograd )이 대부분의 compiler에 적절하게 동작하지 못하기 때문일 것 입니다. 이러한 문제를 해결하는 방법은 큰 크기의 kernel size를 사용하지 않고 LeViT, CeiT, CvT와 같이 하드웨어에 효율적으로 구성된 $3 \times 3$ 커널 사이즈의 몇 개의 계층으로 구성된 convolution layer를 사용하는 것 입니다.
Observation 2: Consistent feature dimension is important for the choice of token mixer. MHSA is not necessrily a speed bottleneck.
보통 MLP block이나 어떤 다른 종류의 token mixer를 ViT 계열 모델들에서 사용합니다. 이러한 token mixer는 효율적인 ViT 모델을 설계하는 데에 있어 중요한 요소입니다. 다음은 대표적인 ViT 계열 모델들의 예시를 보여주고 있습니다.
- Vision Transformer: Conventional MHSA Mixer with a global receptive field
- Swin Transformer: More sophiscated Shifted Window Attention
- MetaFormer: Non-parameteric Operation (Pooling)
여기서 Swin Transformer에서 사용하는 방법은 연산량이 대체적으로 많이 요구되는 편이기 때문에 ViT와 MetaFormer에서 선택하는 MHSA와 Pooling 기법에 집중해보도록 하겠습니다. Pooling 기법은 매우 단순하고 효율적이지만 MHSA는 훨씬 더 좋은 성능을 내는 데 도움을 줍니다. 그리고 PoolFormer vs. LeViT를 보면 Reshape operation이 speed bottleneck이 심해지는 것을 볼 수 있습니다. 또한, DeiT vs. LeViT도 보면 Reshape 연산 없이 차원이 유지되는 상태로 MHSA가 생각보다 높은 speed bottleneck을 요구하지는 않습니다.
이러한 부분에서 본 논문에서 4D feature implementation과 3D MHSA를 적절하게 배열하여 설계한 dimension-consistent network를 제안하고 이는 방금 관찰에서 보았던 Reshape 연산을 최소한으로 줄여주는 모델입니다.
Observation 3: CONV-BN is more latency-favorable than LN (GN)-Linear and the accuracy drawback is generally acceptable.
MLP 구현을 어떤 방식으로 할지도 ViT 모델을 설계하는데에 있어 중요한 요소입니다. 가장 큰 종류는 다음과 같이 설계하는 방법들이 있습니다.
- LN with 3D Linear Projection (DeiT)
- $1 \times 1$ CONV with BN (PoolFormer)
여기서 DeiT vs. PoolFormer를 비교해보면 LN에 의해 발생하는 latency는 10% ~ 20%로 꽤나 높은 편입니다.
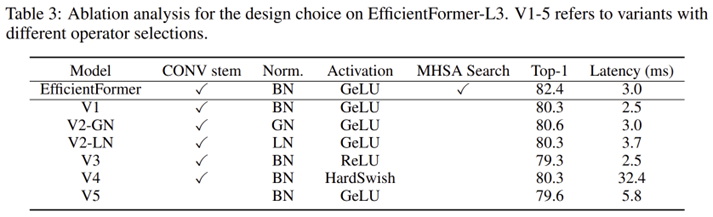
또한, 표 3에서 볼 수 있듯이 CONV-BN는 GN과 비교했을 때 매우 적은 성능 하락을 보여주며 channel-wise LN과 거의 비슷한 성능을 보여주고 있습니다. 따라서, 4D feature dimension에서는 CONV-BN을 사용하고 3D feature dimension에서는 MHSA를 사용한 것을 선택합니다.
Observation 4: The latency of nonlinearity is hardware and compiler dependent.
또한, nonlinearity에 의한 latency의 증가는 hardware에 따라 큰 차이가 존재합니다. 따라서, 어떤 hardware에서 동작할것이냐에 따른 선택이 매우 중요할 것 입니다.
EfficientFormer
1) Overall Architecture
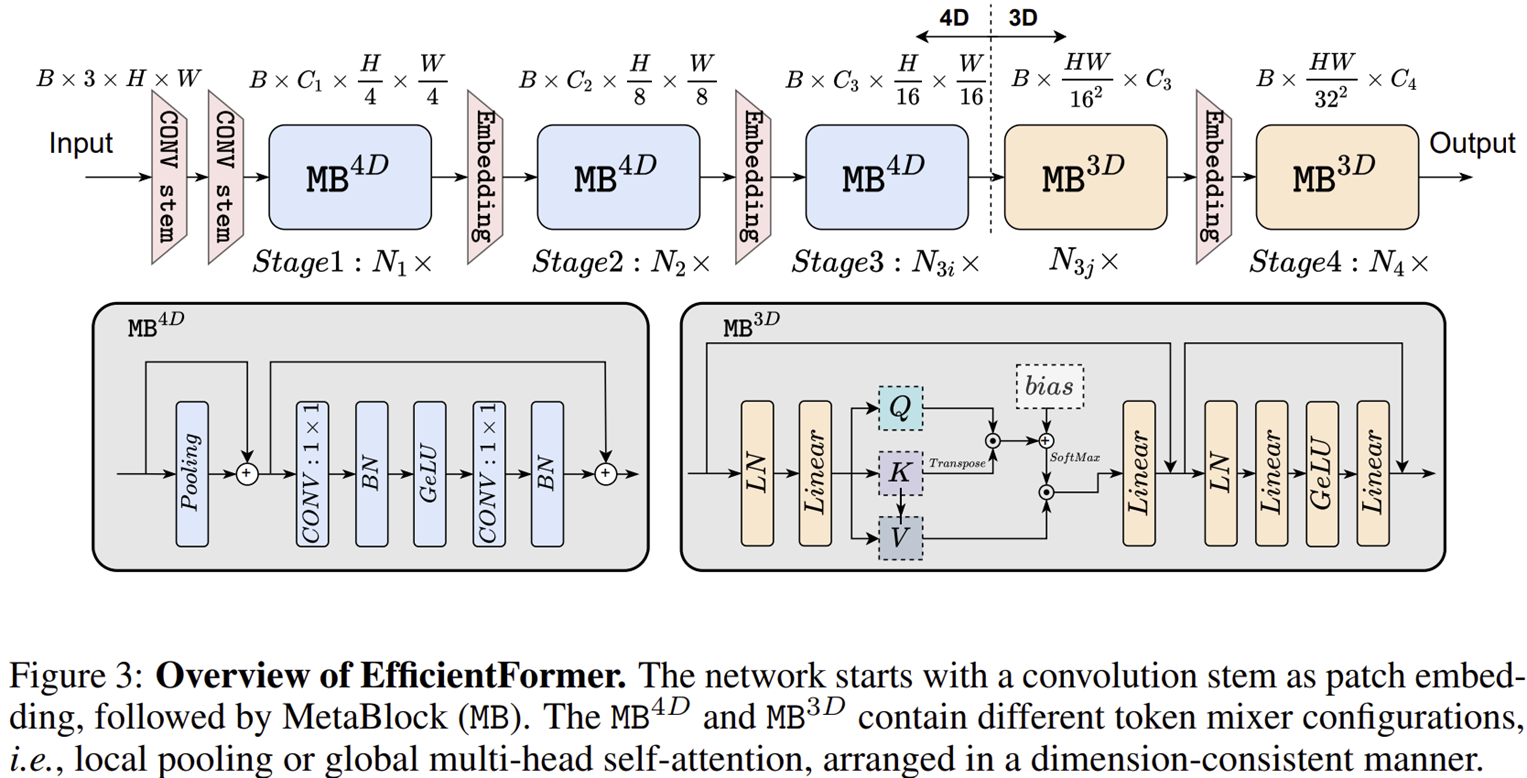
그림 3은 EfficientFormer의 전체적인 네트워크 구조를 보여주고 있습니다. 여타 다른 ViT 계열 모델들과 같이 총 4개의 스테이지로 구성되어 있습니다. 그리고 각각의 스테이지 사이에 Embedding 계층이 있고 token length를 점차적으로 줄여주어 연산량을 줄여주는 과정을 거치게 됩니다.
2) Dimension-Consistent Design
EfficientFormer는 그림 3에서 보이는 것과 같이 4D partition과 3D partition을 나누어져 있습니다. 그리고 4D partition에서는 CONV-Net Style을 주로 사용하고 3D partition에서는 linear projection과 attention mechanism을 주로 이용하게 됩니다. 이때, Reshape 연산 사용을 최소화하기 위해서 처음에는 4D parition으로 시작하다가 마지막 스테이지에서만 3D partition을 사용합니다.
STEP1. 입력 영상을 $3 \times 3$ 크기의 커널과 stride 2로 구성된 가진 몇 개의 CONV 계층을 patch embedding으로 적용한다.

STEP2. low-level feature를 추출하기 위해 단순한 Pool Mixer로 구성된 $\text{MB}^{4D}$를 적용한다.
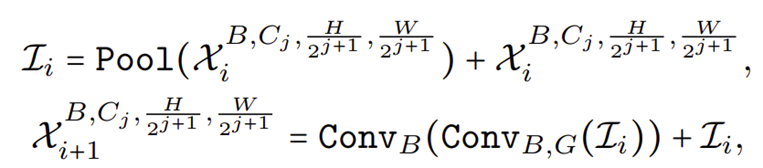
STEP3. 3D partition $\text{MB}^{3D}$에 통과하기 전 Resahpe을 한번만 적용하고 $\text{MB}^{3D}$를 적용한다.
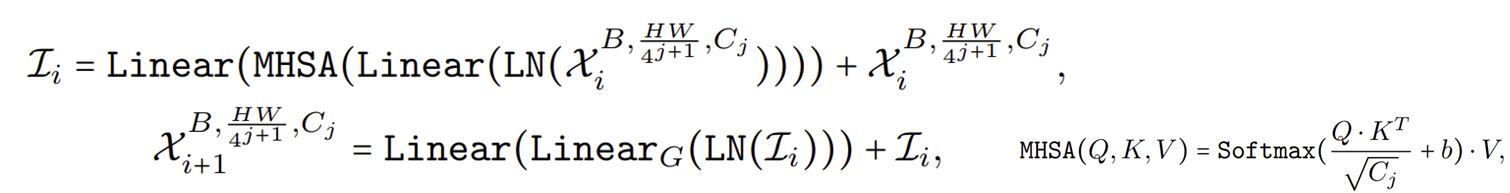
3) Latency-driven Slimming

마지막으로 위 알고리즘을 이용해서 최종적으로 NAS를 적용하여 efficient한 ViT를 찾도록 합니다.
Experiment Results
1) Image Classification
2) Object Detection and Instance Segmentation