안녕하세요. 지난 포스팅의 [IC2D] NASViT: Neural Architecture Search for Efficient Vision Transformers with Gradient Conflict-Aware Supernet Training (ICLR2022)에서는 Transformer에 NAS를 곁들인 NASViT를 소개시켜드렸습니다. 오늘은 작년에 소개시켜드린 GhostNet의 진화버전인 GhostNetV2를 소개하도록 하겠습니다.
Background
Computer Vision에서 AlexNet, GoogleNet, ResNet등과 같은 모델들의 성공은 지금까지도 수많은 어플리케이션에서 딥 러닝을 활용하게 되는 주요한 원인이 되었습니다. 이러한 성공은 최근 다양한 산업에서 딥 러닝 모델을 모바일 및 웨어러블 디바이스에 이식하여 사용하고자 하는 욕구로 이어졌지만 제한된 컴퓨터 리소스로 인한 소규모 모델의 낮은 성능을 제공해주게 되었습니다.
이러한 효율성 문제를 해결하기 위해 MobileNetV1을 필두로 다양한 MobileNet, ShuffleNet, EfficientNet, CondenseNet 그리고 GhostNet과 같은 모델들이 제안되었죠. 하지만 이러한 합성곱 기반의 모델들은 입력 영상의 quadratic한 복잡도를 요구하는 self-attention mechanism을 기반으로 long-range dependency를 활용할 수 없어 그 표현력이 제한되고 성능이 감소하게 되었습니다. 이러한 문제를 해결하기 위해 제안된 MobileViT는 ViT 계열에서도 높은 효율성을 달성하였지만 CNN 기반의 MobileNetV2 보다 7배 느리다는 문제점이 존재합니다.
본 논문에서는 self-attention이 아닌 새로운 방식으로 long-range dependency를 활용할 수 있는 decoupled fully-connected (DFC) attention을 기반으로 기존의 GhostNet을 개선한 GhostNetV2를 제안합니다.
GhostNetV2
1) Preliminary
본 논문에서는 본격적으로 GhostNetV2를 설명하기 전에 이전 모델인 GhostNet에 대해서 간단한 설명을 진행합니다.
1-1) A Brief Review of GhostNet
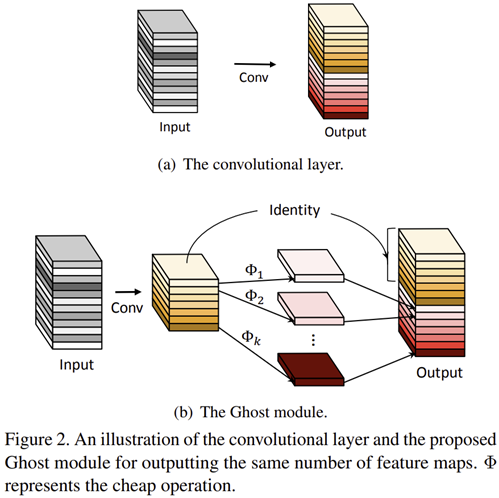
GhostNet은 MobileNet과 마찬가지로 모바일 디바이스에서 딥 러닝 모델을 사용하고자 제안된 CNN-based light-weight 모델 중에 하나입니다. 핵심 모듈을 Ghost Module로 기존의 convolution 연산을 단순한 cheap operation으로 바꾸어 구현하였죠.
첫번째 단계는 $1 \times 1$ 합성곱을 적용하여 intrinsic feature인 $Y^{'} = X * F_{1 \times 1}$를 만들어줍니다. 다음 단계는 Depth-wise operation과 같이 상대적으로 적은 비용의 연산을 이용하여 intrinsic feature에 더 다양한 feature map들을 만들어줍니다. 마지막으로 intrinsic feature와 depth-wise convolution을 적용한 feature map을 하나로 concat하여 최종 출력 특징 맵을 생성하죠.
$$Y = Concat ([Y^{'}, Y^{'} * F_{dp}])$$
이렇게 매우 단순한 연산으로 구성된 Ghost Module은 연산량을 줄일 수 있게 되었지만 그만큼 표현력이 상대적으로 떨어질 수 밖에 없습니다. 특히, Ghost Module은 더욱 정확한 인지를 위한 spatial pixel 간의 관계성을 무시하였기 때문에 이러한 결과는 당연하죠.
1-2) Revisit Attention for Mobile Architecture
Self-Attention은 long-range dependency를 고려하는 데에 있어 가장 기본적으로 핵심적인 연산 중 하나입니다. 하지만 feature map size의 quadratic하게 복잡도가 증가한다는 문제점으로 인해 쉽게 선택되지 못하죠. 이러한 복잡도 문제를 해결하기 위해 Swin Transformer와 MobileViT와 같은 방법들도 제안되었지만 여전히 CNN 기반의 light-weight 모델들에 비해 낮은 성능을 보여주죠.
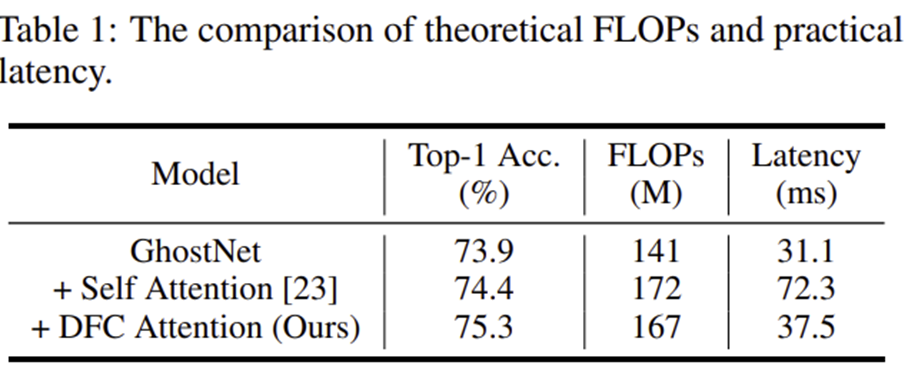
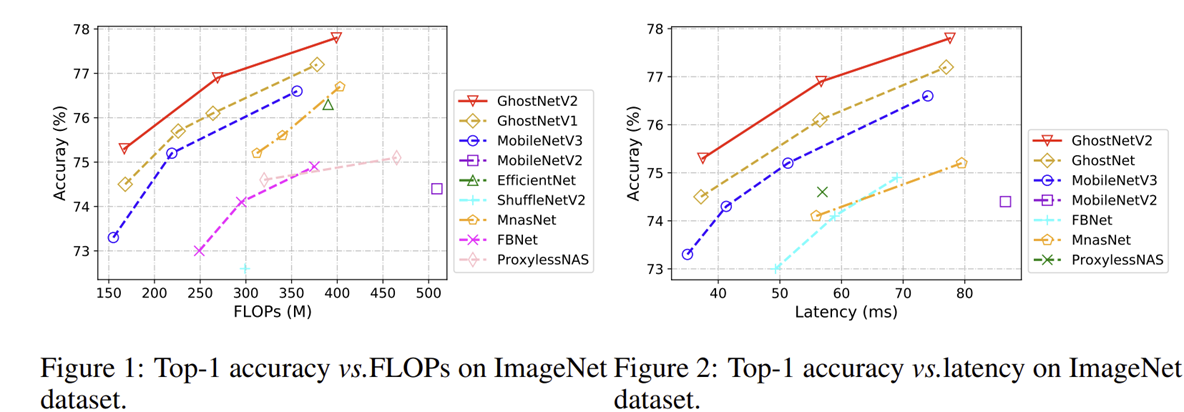
본 논문에서는 간단한 실험으로 MobileViT에서 사용된 self-attention을 GhostNet에 그대로 적용하여 분석해봅니다. 그 결과 성능은 실제로 0.5%로 미세하게 향상되지만 Latency가 거의 2배 정도 크게 증가한 것을 볼 수 있습니다. 이는 long-range dependency의 중요성을 강조하면서 self-attention의 복잡도 이슈도 함께 보여주고 있습니다. 하지만, 잠시 뒤 설명드릴 본 논문에서 제안하는 DFC Attention을 적용하면 성능도 1.4% 향상되면서 Latency도 self-attention과 비교했을 때 크게 증가하지 않는 것을 볼 수 있죠.
2) DFC Attention for Mobile Architecture
결국 Attention Mechanism에서 중요한 것은 3가지 입니다: 1) Long-range Dependency, 2) Deployment-efficient, 3) Concept-simple. 하지만 self-attention의 경우 1)은 달성하지만 2)와 3)은 달성하지 못하였죠. 따라서 본 논문에서는 훨씬 단순하고 쉬운 fully-connected layer만을 이용해서 long-range dependency를 활용하고자 합니다. 그러면 1), 2), 3)을 동시에 달성하여 그 목표를 이루게 되죠.
입력 특징맵 $Z \in \mathbb{R}^{H \times W \times C}$이 주어졌을 때, $HW$개의 토큰 $Z = \{ z_{11}, z_{12}, \dots, z_{HW} \}$로 고려할 수 있으며 여기서 각 토큰 $z_{i} \in \mathbb{R}^{C}$의 형식을 가집니다. DFC Attention의 핵심은 FC layer의 직접적인 구현은 다음과 같이 설계합니다.
$$a_{hw} = \sum_{h^{'}, w^{'}} F_{hw, h^{'}w^{'}} \odot z_{h^{'}w^{'}}$$
$F_{hw, h^{'}w^{'}}$은 learnable weight로 token 간의 long-range dependency를 위한 global information aggregator라고 볼 수 있습니다. 하지만, 여전히 그 복잡도는 $O ((HW)^{2})$로 높기 때문에 이를 줄여주어야합니다. 이를 위해 본 논문에서는 CNN의 특징 맵이 low-rank라는 점에 주목합니다. 쉽게 말하면 중요한 정보는 한정된 영역에 존재한다는 것이죠. 따라서, 모든 token을 동시에 고려하지 않는 것을 고려해봅니다.
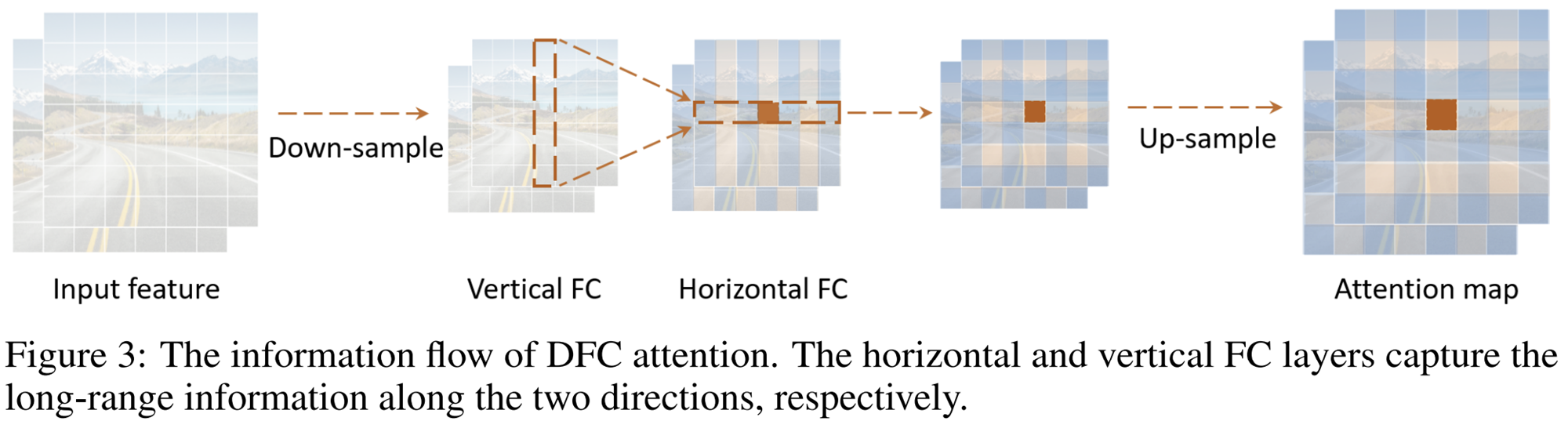
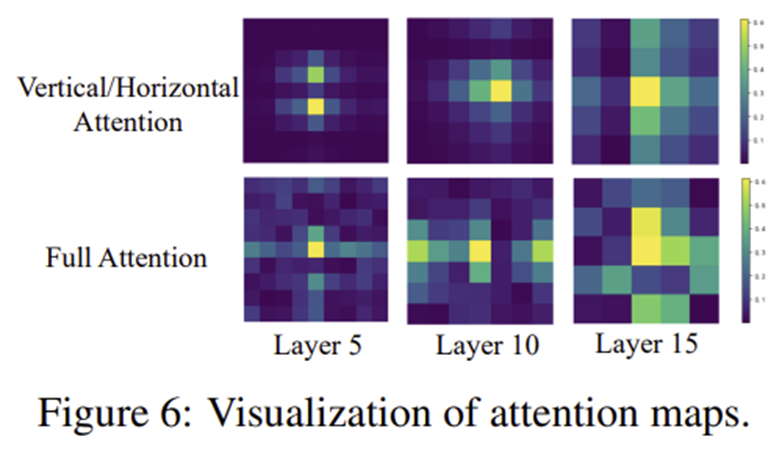
이를 위해 그림 3과 같이 다운샘플링을 수행한 뒤 FC layer를 적용할 때 vertical/horizontal FC를 따로 분해하여 attention을 수행해주는 방식을 채택합니다.
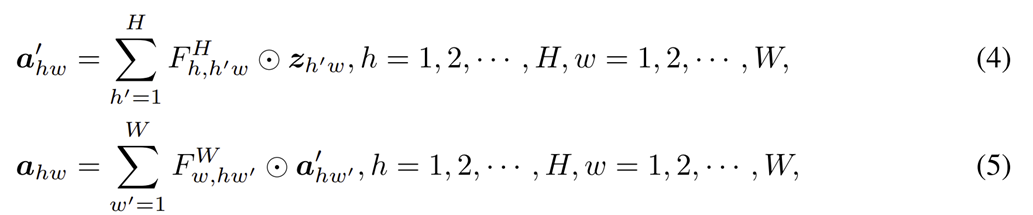
이를 수식화하면 위 두개의 방식으로 표현할 수 있습니다. 이를 통해, 복잡도는 $O (HW (H + W))$로 줄게 됩니다. 하지만, FC Layer가 아닌 convolution으로 구현하면 보다 쉽게 구현하고 더욱 효율성이 증가될 수 있어 본 논문에서는 convolution 기반으로 설계하였습니다.
3) GhostNetV2
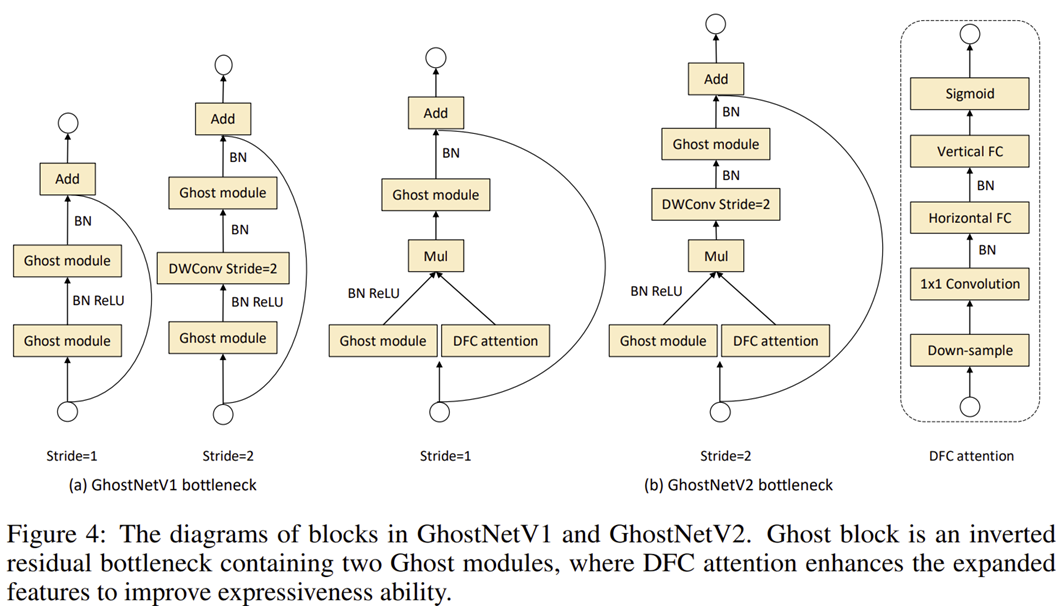
그림 4는 GhostNetV1과 GhostNetV2 사이의 비교를 보여주고 있습니다. 두 모듈의 핵심적인 차이는 DFC Attention의 유무로 입력 특징 맵은 Ghost Module과 DFC Attention에 각각 입력되어 element-wise multiplication을 취한 뒤 다시 Ghost Module을 통과하여 연산이 수행되죠.
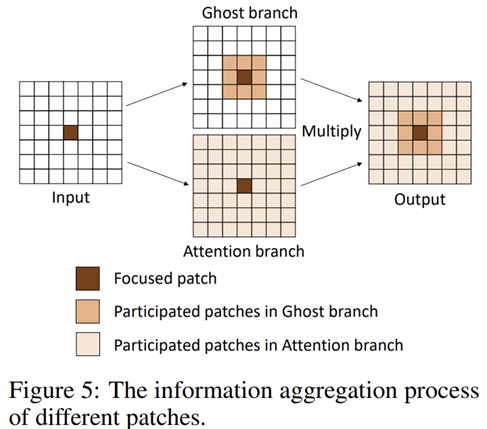
그림 5는 전체적인 정보 흐름을 한번더 도식화하는 것으로 특정 패치를 중심으로 전체를 보면서도 지역적 특징도 고려하는 것을 볼 수 있죠.
Experimental Results
1) Image Classification
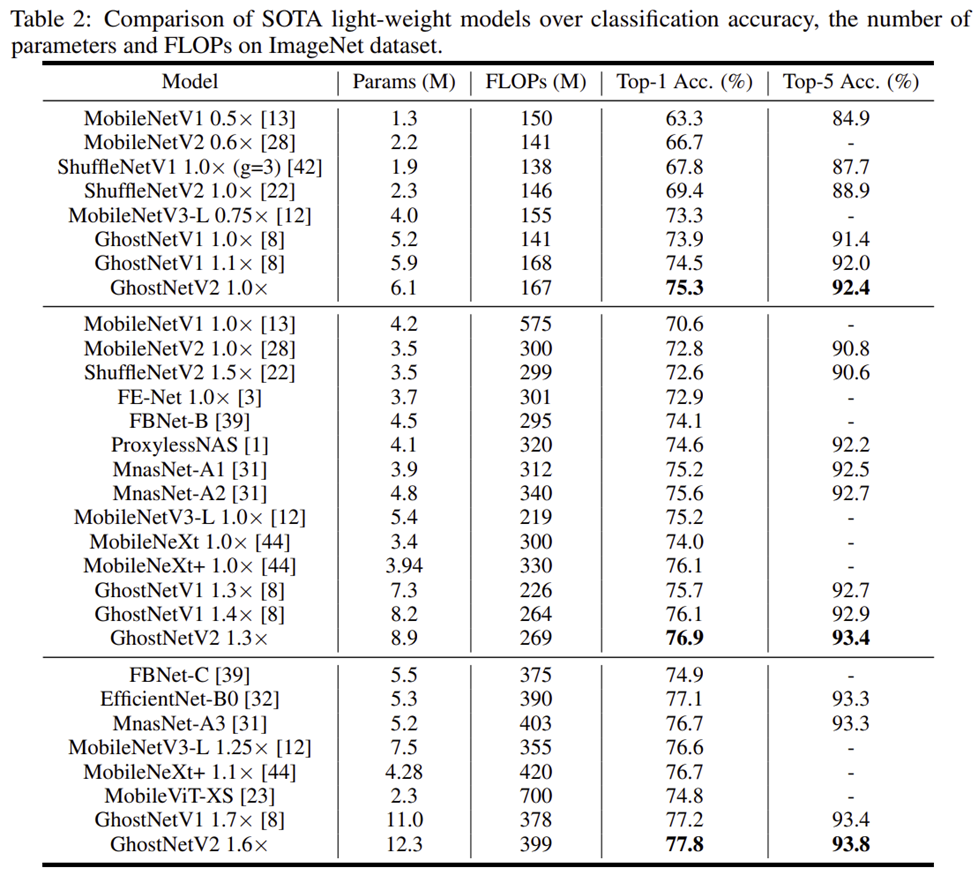
2) Object Detection
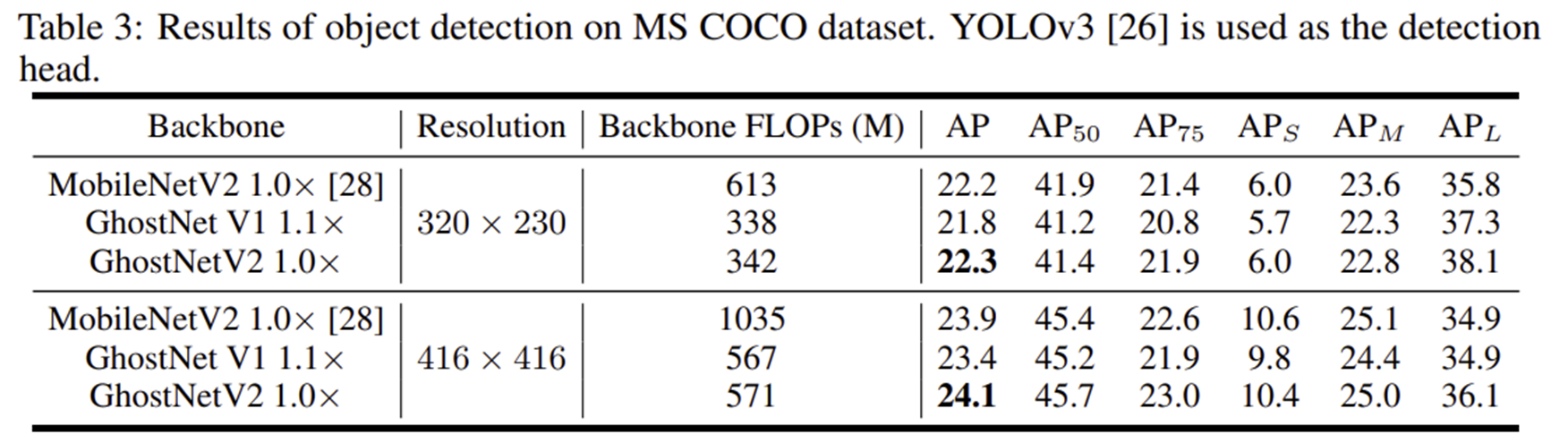
3) Semantic Segmentation
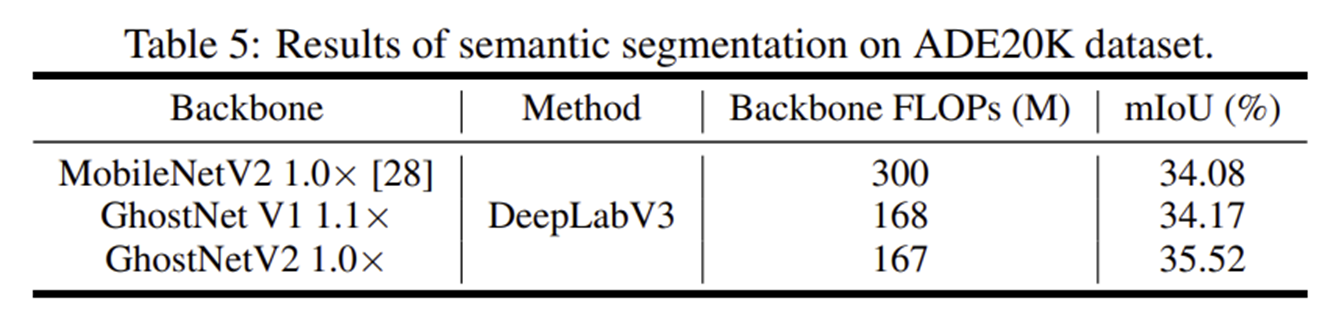
4) Ablation Study
4-1) Location of DFC Attention
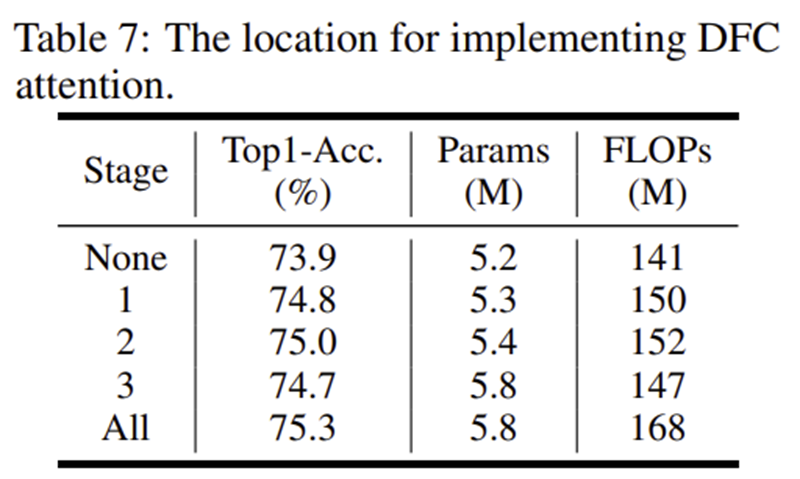
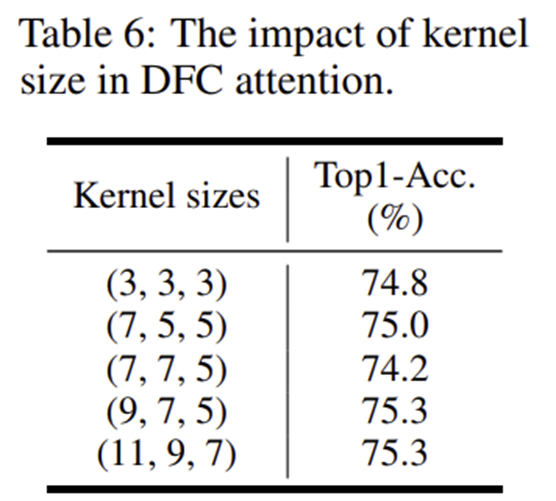
4-2) Kernel Size of DFC Attention
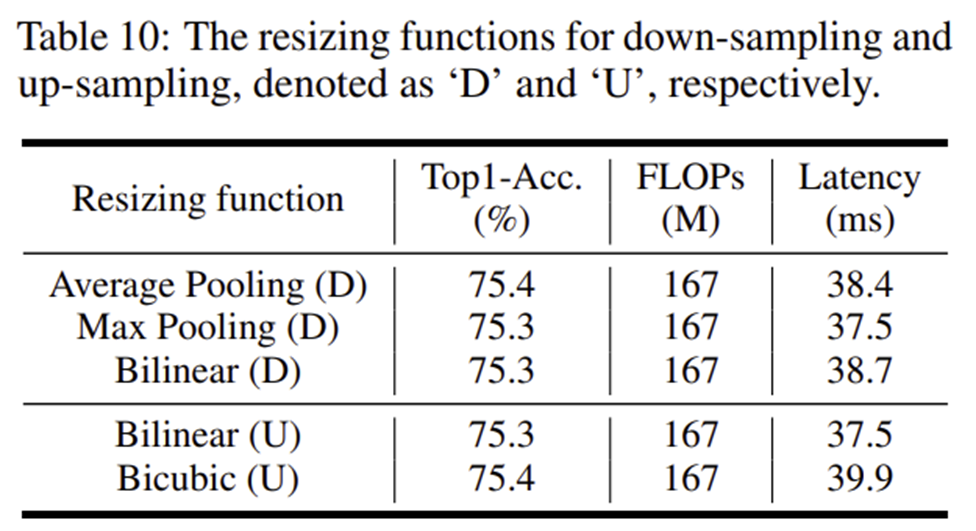
4-3) Resizing Function
5) Attention Map Visualization