안녕하세요. 지난 포스팅의 [Transformer] Escaping the Big Data Paradigm with Compact Transformers (arxiv2021)에서는 대용량 데이터셋에서만 학습해야하는 Transformer의 단점을 해결한 CVT와 CCT에 대해서 알아보았습니다. 이를 통해, 대표적인 소규모 데이터셋인 CIFAR에 직접 학습해도 높은 성능이 나오는 것을 관찰할 수 있었죠. 오늘은 매우 간단한 논문입니다. 조금 옛날 제가 리뷰했던 Pyramid Vision Transformer (PVT)의 Journal Extension 버전으로 이전 논문만 이해한다면 매우 쉽게 읽어볼 수 있는 논문입니다. 또한, 기본적으로 Background 역시 PVT와 유사하기 때문에 생략하도록 하겠습니다.
Pyramid Vision Transformer v2
1) Main Difference between PVT v1 & PVT v2
PVT v1과 PVT v2의 핵심적인 차이는 아래의 세 가지로 요약할 수 있습니다.
- Linear Complexity Attention Layer
- Overlapping Patch Embedding
- Convolutional Feed-Forward Network
2) Linear Complexity Attention Layer
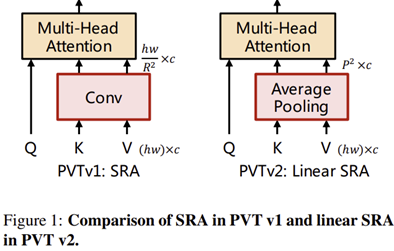
그림 1은 두 모델의 핵심 차이점인 SRA와 Linear SRA의 차이점을 보여주고 있습니다. PVT v1에서 Multi-Head Self-Attention의 복잡도에는 입력 특징 맵의 해상도가 큰 영향을 끼친다는 점을 확인하여 stride를 더 크게 잡은 convolution 계층을 도입하여 FLOPs를 줄였습니다. 하지만, 이 과정에서 Convolution operation의 복잡도가 추가로 요구되기 때문에 이를 방지하기 위한 방법으로 Linear SRA를 도입하였습니다. 이는 매우 간단하게 convolution operation을 average pooling으로 바꾸어 추가적인 파라미터와 FLOPs를 상쇄하여 Linear Complexity를 가질 수 있게 만들었습니다.
3) Overlapping Patch Embedding & Convolutional Feed-Forward Network
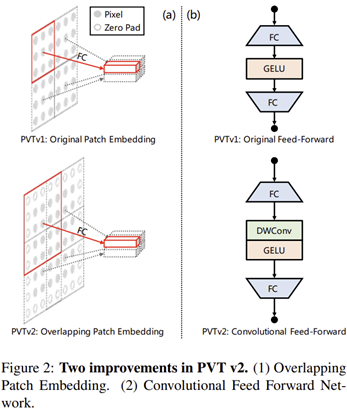
다음 차이점은 patch embedding 시 정확하게 격자를 쪼개어 서로 겹치지 않게 했던 PVT v1과는 달리 픽셀 간의 연속적인 관계를 추가로 이해하기 위해 overlapping patch embedding을 추가하였습니다.
또한, 기존 MLP 기반의 FFN을 Depth-wise convolution 기반의 FFN으로 대체함으로써 CNN에 비해 상대적으로 부족한 inductive bias를 주입해줍니다. 이를 통해 고정된 크기의 position encoding을 수행하지 않아도되기 때문에 다양한 해상도의 데이터를 다루어야하는 segmentation 및 object detection에서 큰 활약을 펼치게 되었습니다.
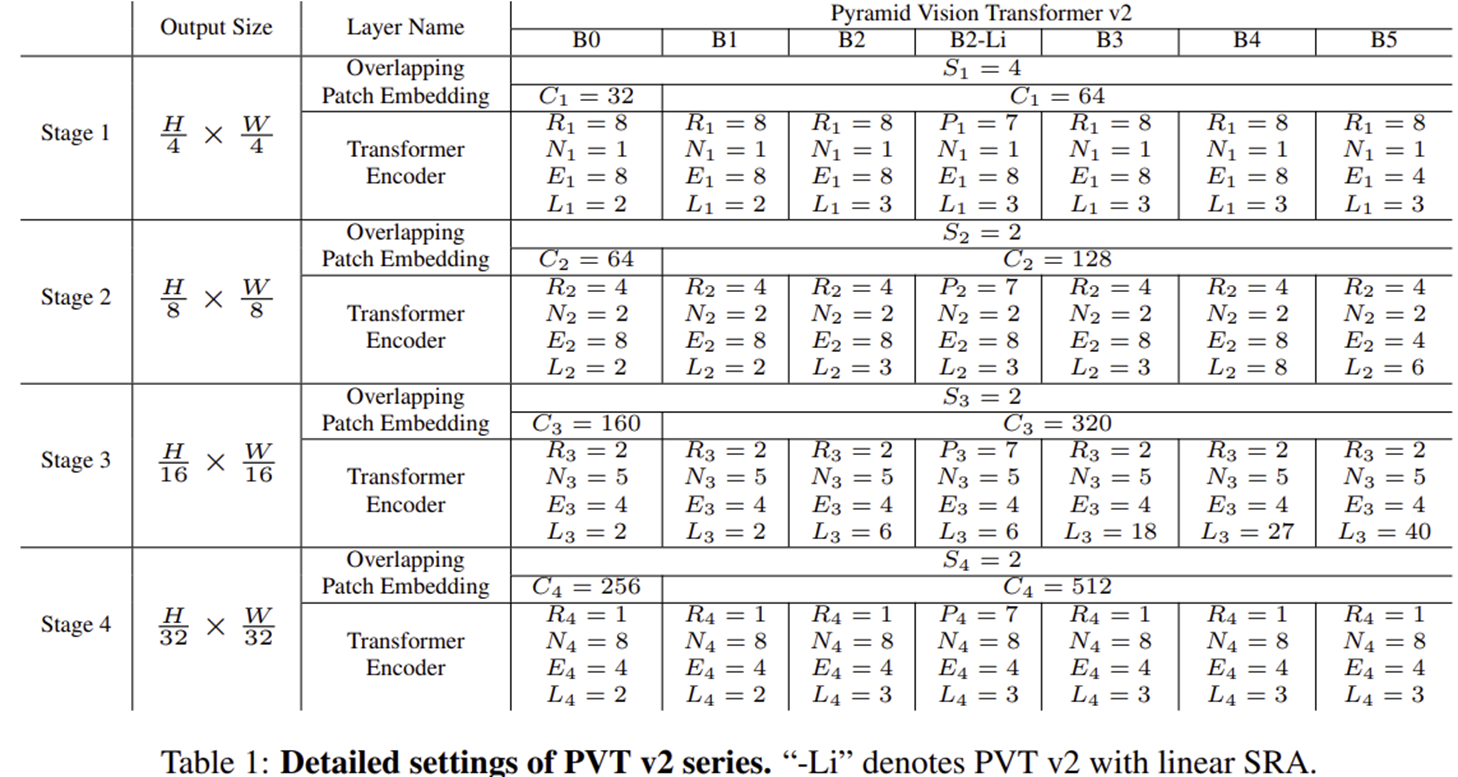
4) Variants of PVT v2 Architecture
Experiment Results
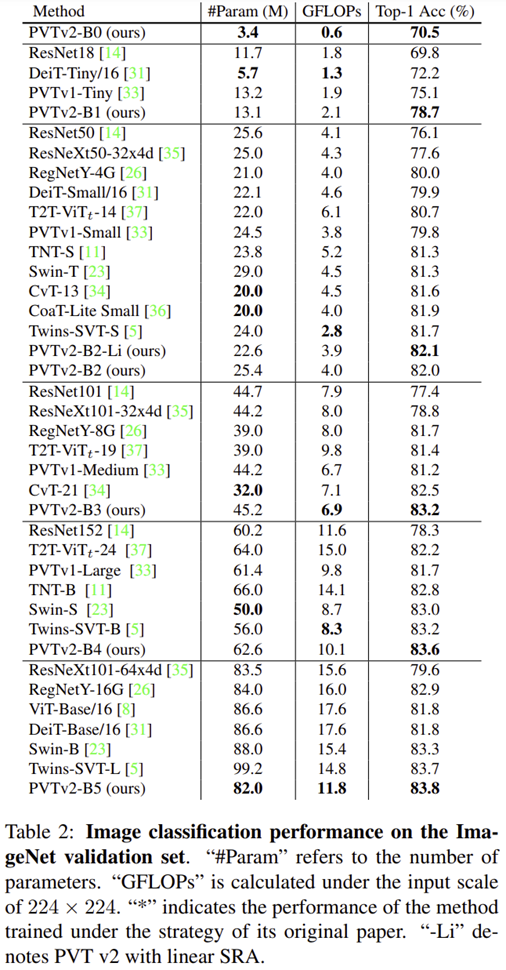
1) Image Classification
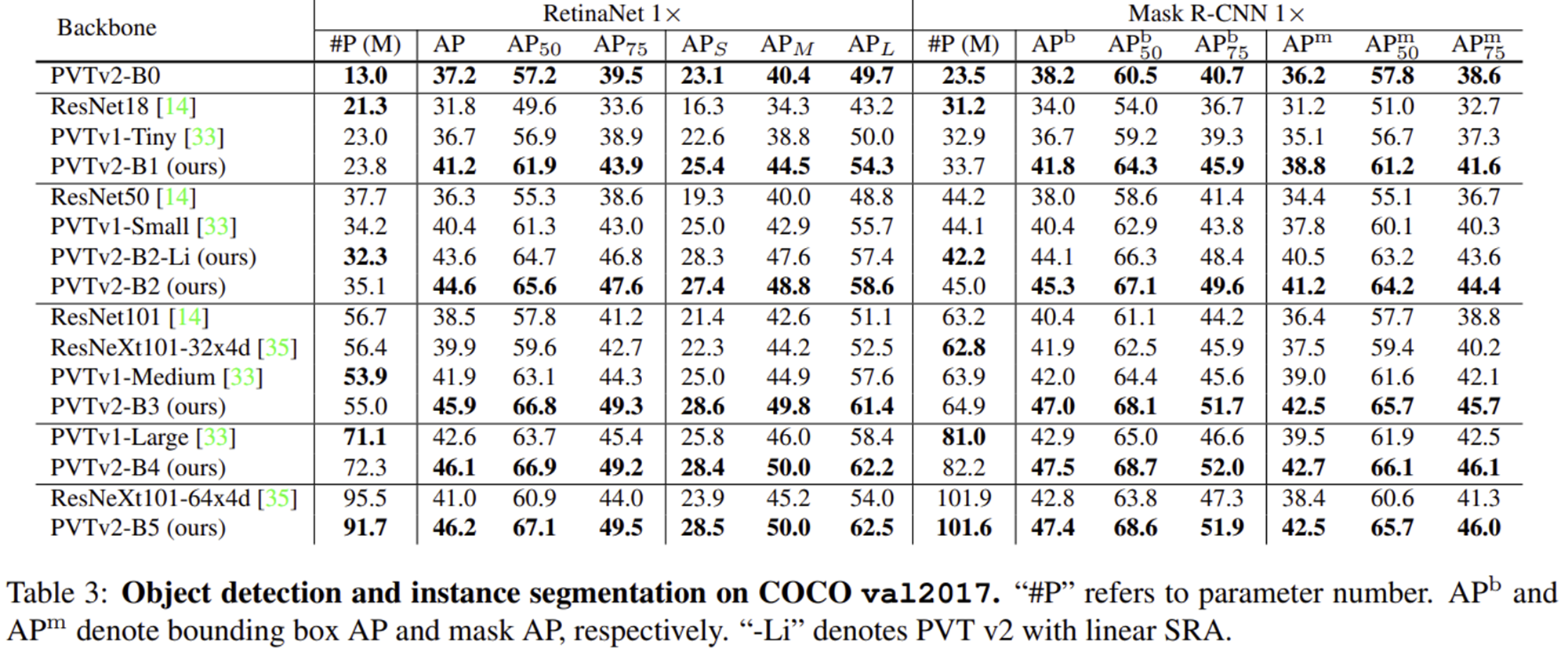
2) Object Detection
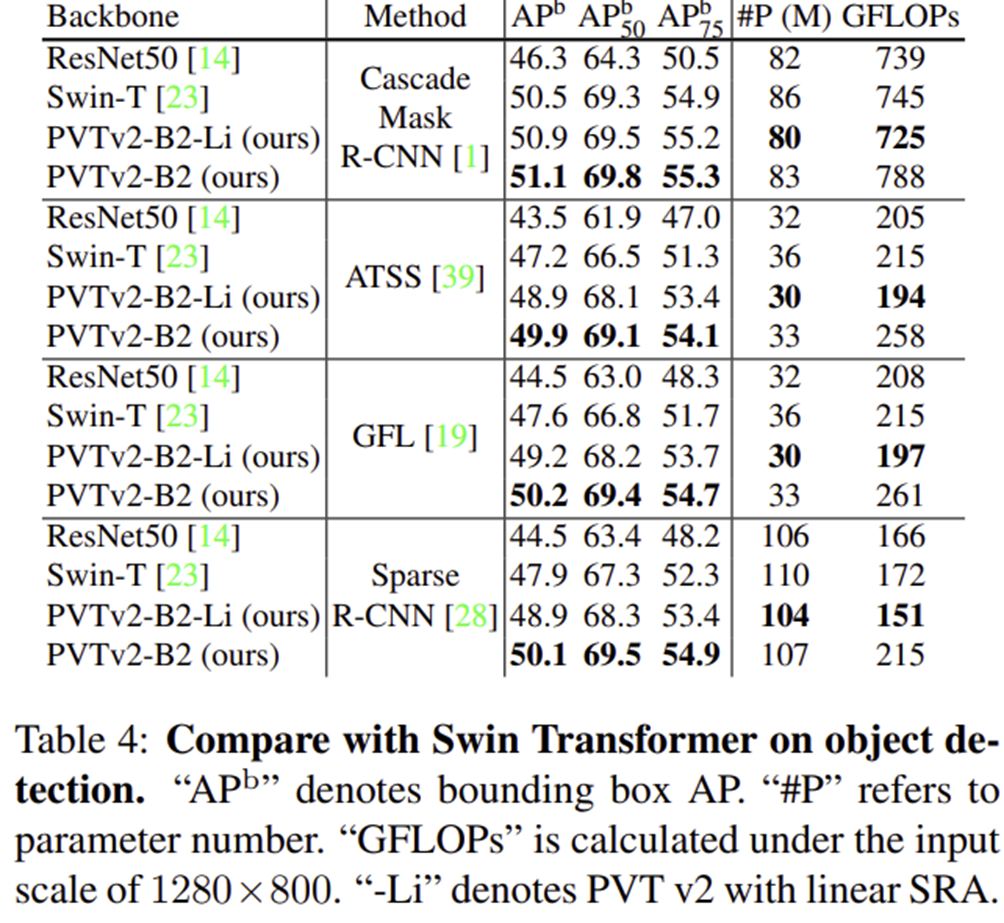
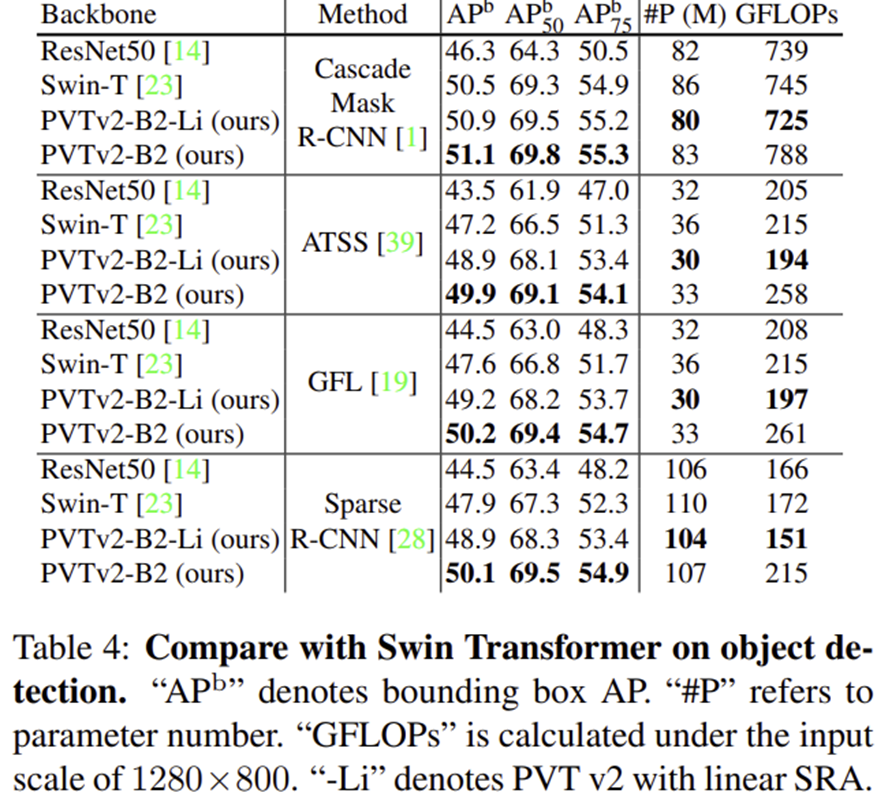
3) Semantic Segmentation
4) Qualitative Results

5) Ablation Study
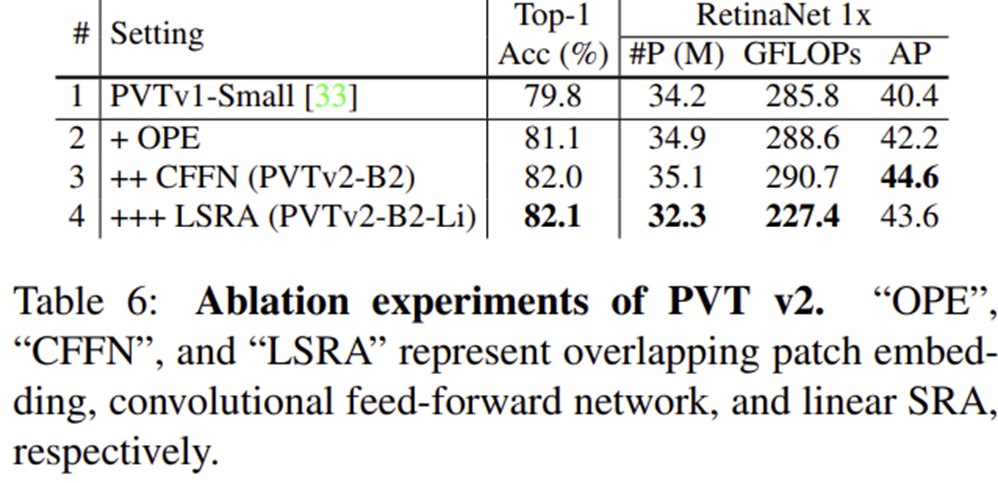
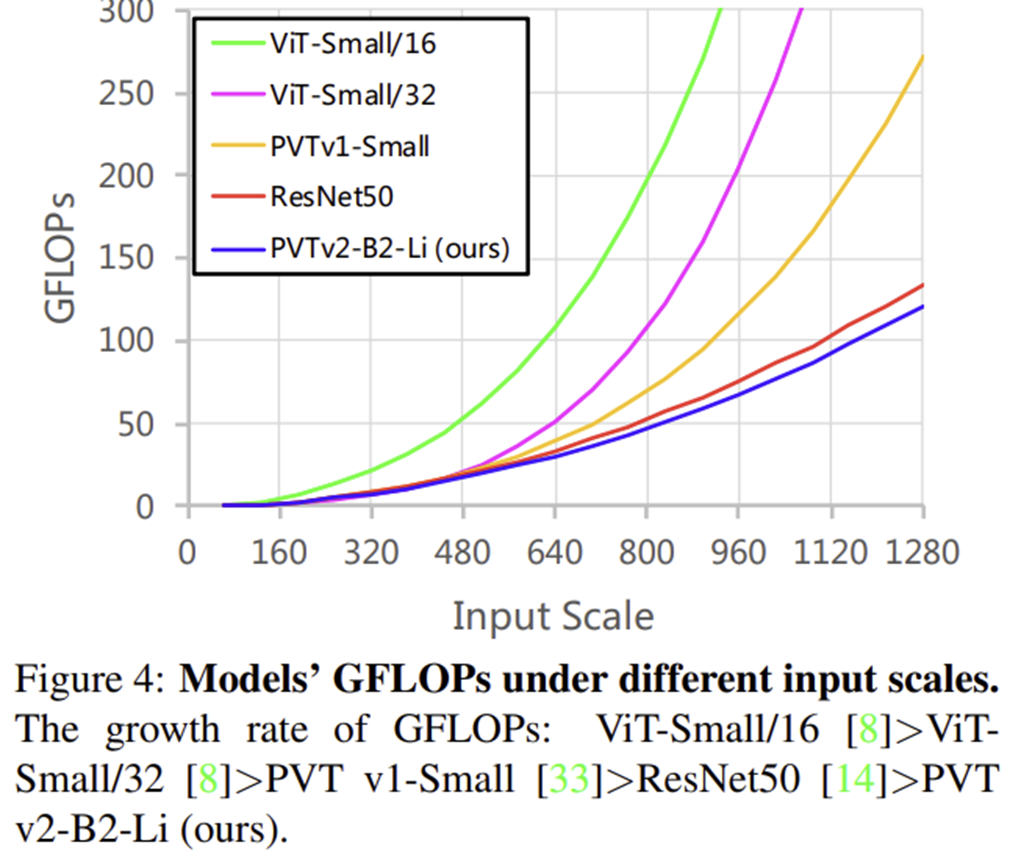
6) Model Complexity