
안녕하세요. 지난 포스팅의 [Transformer] LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference (ICCV2021)에서는 기존의 ViT 구조에서 보다빠른 inference 속도를 달성할 수 있는 몇 가지 트릭을 활용하여 GPU, Intel CPU, ARM에서 모두 높은 효율성을 가지도록 만든 LeViT에 대해서 소개하였습니다. 오늘도 역시 CNN의 특성을 조금이라도 Transformer 구조에 이식하기 위한 시도였던 Tokens-to-Token ViT에 대해서 소개하도록 하겠습니다.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformer (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then a
arxiv.org
Background
기본적으로 Self-Attention은 자연어 처리 분야에서 긴 문맥 사이의 전체 맥락을 이해하는 데 있어 매우 중요한 역할을 수행하는 연산입니다. Vision Transformer (ICLR2021)에서는 이러한 특성을 컴퓨터 비전 분야에 직접적으로 적용한 첫번째 Transformer 기반 모델이 되었습니다. 이때, 근본적으로 Transformer이기 때문에 입력 영상을 패치 단위로 쪼개는 Patchify를 적용한 뒤 flatten하여 벡터화를 시켜 Linear Embedding을 통해 마치 자연어의 벡터를 다루는 것과 같이 똑같은 Transformer Encoder를 거치게 되었습니다. 이를 통해, ViT는 영상 분류를 위한 전체 맥락 (global relation)을 이해할 수 있게 되었죠.
하지만, ViT의 가장 큰 문제점은 중간 규모의 데이터셋인 ImageNet-1K에 직접적으로 학습했을 때 CNN에 비해 성능이 많이 떨어진다는 문제점이 있었습니다. 본 논문에서는 이러한 문제의 원인으로 2가지로 설명합니다.
1) 입력 영상에 hard split (non-overlapping)을 통한 tokenization (patchify)으로 인한 영상의 local structure 모델링 실패
2) ViT의 attention backbone은 애초에 자연어 처리를 위해 만들어져있기 때문에 컴퓨터 비전 분야에 직접적으로 사용하는 것은 풍부한 특징을 추출하는 데 제한적

실제로 저자들은 이러한 문제를 그림 2와 같이 feature map들을 시각화함으로써 확인해봅니다. 여기서 ViT는 CNN에 비해 feature map들의 다양성이 많이 떨어지는 것을 볼 수 있습니다. 심지어 어떤 경우에는 아예 zero matrix가 있는 경우도 있습니다.
이러한 문제를 해결하기 위해 본 논문에서는 Tokens-to-Token (T2T) Module을 제안하여 점진적 tokenization 방법을 제안합니다. 이를 통해 ViT 모델은 입력 영상의 local structure를 보다 잘 이해할 수 있으며 token의 길이도 점진적으로 줄일 수 있기 때문에 효율적인 방식이라고 합니다. 또한, ViT에 알맞는 attention backbone 구조를 찾기 위해 기존의 CNN의 핵심 설계 전략 중 하나인 "Deep-Narrow" 방식을 채택하였습니다. 두 가지를 결합한 T2T-ViT는 ImageNet-1K에 직접적으로 학습했을 때 ResNet과 ViT 보다 높은 성능을 달성하게 되었습니다. 뿐만 아니라, MobileNet과도 비교했을 때도 효율적으로 성능을 향상시키는 것을 볼 수 있습니다.
Tokens-to-Token ViT
1) Tokens-to-Token (T2T): Progressive Tokenization
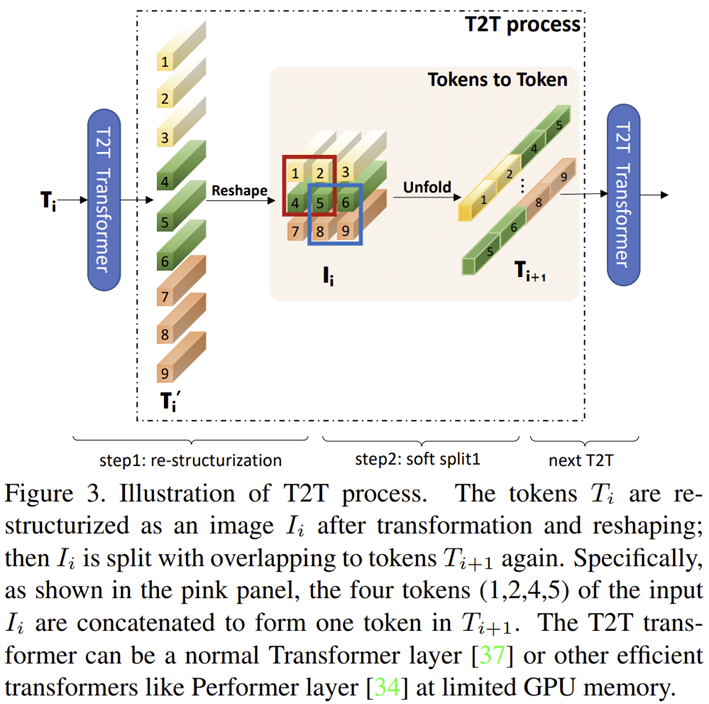
T2T Module은 ViT의 단순한 Tokenization의 한계를 극복하기 위해 제안된 모듈입니다. 핵심은 token들을 영상으로 변환하는 Restructurization과 overlapping하면서 Tokenization을 하는 Soft-Split 입니다.
첫번째 단계인 Restructurization은 단순히 $l = h \times w$로 flatten된 벡터를 다시 영상의 형상을 가지도록 바꾸어주는 것입니다. 이는 다음과 같이 진행됩니다.
STEP1. 이전 T2T Transformer Block에서 Self-Attention 수행
$$T^{'} = \text{MLP} (\text{MSA} (T)) \in \mathbb{R}^{l \times c}$$
여기서 $\text{MLP} (\cdot)$과 $\text{MSA} (\cdot)$은 Multi-Layer Perceptron과 Multi-head Self-Attention을 의미합니다.
STEP2. Token $T^{'}$을 영상의 형상을 가지도록 reshape
$$I = \text{Reshape} (T^{'}) \in \mathbb{R}^{h \times w \times c}$$
이제 두번째 단계인 Soft-Split입니다. 기존 Transformer 같은 경우에는 overlapping하지 않고 token을 만들었기 때문에 local structure를 이해하지 못하는 것이라고 본 논문에서는 주장하였습니다. 이는 매우 단순한 방식으로 수행됩니다. 일단, token을 만들기 위해 패치의 개수 $k \times k$와 얼마나 겹치면서 쪼갤것인지인 $s$ 그리고 패딩 $p$가 핵심 파라미터 입니다. 이때, 저희는 $k - s$가 기존 Convolution 연산 파라미터 중 하나였던 stride와 비슷하다는 것을 알 수 있습니다.

좀 더 직관적으로 보기 위해 그림으로 그려보면 위와 같습니다. 전체 $5 \times 5$ 크기의 입력 영상 토큰들이 있을 때 $3 \times 3$의 크기로 1칸씩 겹치면서 split 한다고 가정하겠습니다. 그러면 첫번째에서 그림에서 시작했을 때 한 칸만 겹치기 위해서는 오른쪽 그림과 같이 2칸 이동해서 split 해야합니다. 따라서 stride는 2가 되겠네요. 실제로 $k = 3$ 그리고 $s = 1$이였으니 $k - s$가 stride와 동일하다는 것을 알았습니다. 결국 저희는 출력 토큰의 형상까지 다음과 같이 계산해볼 수 있겠네요.
$$l_{0} = \lfloor \frac{h + 2p - k}{k - s} + 1 \rfloor \times \lfloor \frac{w + 2p - k}{k - s} + 1 \rfloor $$
이제 마지막으로 쪼개진 토큰들을 flatten 시켜 $T_{o} \in \mathbb{R}^{l_{0} \times ck^{2}}$을 얻을 수 있습니다.
T2T Module은 이와 같이 Re-structurization과 Soft-Split을 번갈아가면 진행함으로써 각 token 들간 관계성을 이해할 수 있기 때문에 ViT보다 local structure를 더 잘 파악할 수 있습니다. 하지만, 이 과정에서 ViT 보다 더 많은 개수의 token을 필요로 하기 때문에 본 논문에서는 이를 상쇄하기 위해 채널의 개수를 32개나 64개로 더 줄여서 MAC을 줄여줍니다. 또는 본 논문에 따르면 Performer라고 하는 Transformer 모델을 적용하면 GPU 소모량을 더 아낄 수 있다고 합니다.
2) T2T-ViT Backbone

본 논문에서는 ViT에 알맞은 Backbone 모델을 찾기 위해 다음과 같이 기존 CNN 모델의 특성을 가져옵니다.

Backbone까지 위 구조들중 하나로 결정이 되었다면 다음과 같이 수학적으로 풀어서 쓸 수 있습니다.
$$\begin{cases} T_{f_{0}} &= [ t_{cls}; T_{f} ] + E \\ T_{f_{i}} &= \text{MLP} (\text{MSA} (T_{f_{i - 1}})) \\ y &= \text{fc} (\text{LN} (T_{f_{b}}))\end{cases}$$
여기서 $E$는 Sinusoidal Position Embedding, $\text{LN} (\cdot)$은 Layer Normalization, 그리고 $\text{fc} (\cdot)$은 영상 분류를 위한 Fully-Connected Layer을 의미합니다.
3) T2T-ViT Architecture

Experiment Results
1) ImageNet Classification
- Dataset
- ImageNet-1K: 1.28 million training images & 50K validation images with 1,000 classes
- Data Augmentation (Same as ViT)
- Optimization: -
- batch size: 512 or 1024
- epochs: 300
- NVIDIA GPU x 8

2) Transfer Learning
