
안녕하세요. 지난 포스팅의 [IC2D] Mobile-Former: Bridging MobileNet and Transformer (CVPR2022)에서는 기존의 CNN-Transformer series 구조가 아닌 parallel 구조를 채택하여 MobileNet과 Vision Transformer의 장점을 모두 살린 Mobile-Former를 제안하였습니다. 오늘도 이어서 CNN-Transformer hybrid 구조이지만 frequency 관점에서 해석한 Inception Transformer (iFormer)에 대해서 소개하도록 하겠습니다.
Background
Transformer가 NLP 분야에서 엄청난 성공을 이루게 되면서 Computer Vision 분야에 직접적으로 Transformer를 적용하기 시작하였습니다. 대표적으로 ViT, Swin Transformer, DeiT가 있었죠. 특히, Transformer에서는 기존의 CNN이 local detail만 고려하여 global information을 고려하지 못한다는 문제점을 개선하여 long-range dependency를 적극적으로 활용할 수 있다는 장점이 있습니다. 이는 Multi-Head Self-Attention (MHSA) 단계에서 패치간 correlation을 기반으로 하는 attention을 수행하여 정보 교환이 이루어져 input data에 adaptive하게 적용되죠.
하지만, 최근 ViT의 특성에 대한 연구에 따르면 ViT는 visual data에서 low-frequency 데이터를 잘 추출하는 특성을 가지고 있다는 것을 밝혀냈습니다. 즉, ViT는 입력된 영상 내의 전체적인 객체에 대한 대략적인 모양을 feature로 추출하죠. 이에 반해, CNN에서는 local edge나 texture와 같은 high-frequency 특성을 사용한다는 것이 밝혀졌습니다.
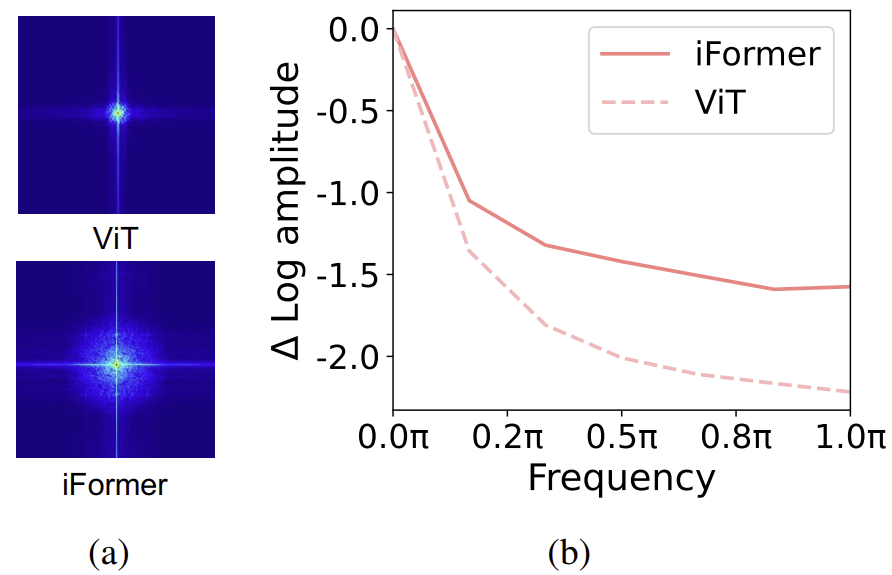
위 그림에서 ViT의 Fourier Spectrum을 확인해보면 실제로 low-frequency가 상대적으로 높은 amplitude을 가지지만 high-frequency는 굉장히 낮은 amplitude을 가지는 것을 볼 수 있죠. 이와 같은 특성은 Computer Vision 분야에서 fine grained classification 분야에서 ViT 계열의 성능이 낮은 이유를 명확히 보여주게 됩니다.
그렇다면 단순히 ViT의 low-frequency feature와 CNN의 high-frequency feature를 함께 사용하여 융합하면 되지 않을까요? 이러한 시도도 당연히 있었습니다. 대표적으로 UniFormer (ICLR2022)는 CNN-Transformer series 그리고 ViTAE (NIPS2021)은 CNN-Transformer parallel 구조를 활용하였습니다. 하지만, series는 구조는 특정 layer에서 오직 low-frequency 또는 high-frequency만 사용한다는 문제점을 가지고 있으면 parallel 구조는 redundant 연산이 존재하여 비용적으로 좋지 않습니다.
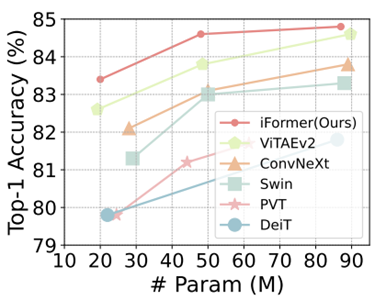
따라서, 본 논문에서는 이러한 문제를 해결하기 위해 Inception Transformer (iFormer)를 제안합니다. 핵심 기여는 Inception Token Mixer로 기존 ViT의 MHSA 파트를 제안하였습니다. 여기서 ViT의 MHSA와 CNN을 함께 사용하여 low/high frequency 특징을 적절하게 활용합니다. 다음으로 deep layer일수록 global information, shallow layer일 수록 local detail이 더 중요한 특징임을 확인하여 본 논문에서는 frequency ramp structure를 제안합니다. 이와 같은 설계를 가진 iFormer는 ViT와 CNN 사이에서 모두 state-of-the-art 성능을 달성하였습니다.
Inception Transformer
1) Revisit Vision Transformer
일단 저희는 ViT의 동작원리를 보도록 하겠습니다. 크게 4개의 단계로 나누어서 볼 수 있죠.
STEP1. 입력 영상을 패치 단위로 나누어 token sequence로 변환
STEP2. 각 토큰을 learnable layer를 이용해 hidden representation vector로 표현
STEP3. 위치 정보를 보존하기 위해 positional embedding를 더함
STEP4. Transformer Layer (MHSA + FFN)에 입력
정말 단순하게 설명하면 위에와 같이 작성해볼 수 있겠죠. 여기서 핵심은 MHSA입니다. 기본적으로 ViT가 global information을 가지게 되는 가장 기본적인 이유는 모든 토큰들에 대한 attention-based mixer를 적용하기 때문이죠. 하지만, 이전 연구에 따르면 이러한 ViT의 특성은 low-frequency representation을 주로 강화하고 high-frequency는 상대적으로 무시한다는 문제점이 있습니다.
2) Inception Token Mixer
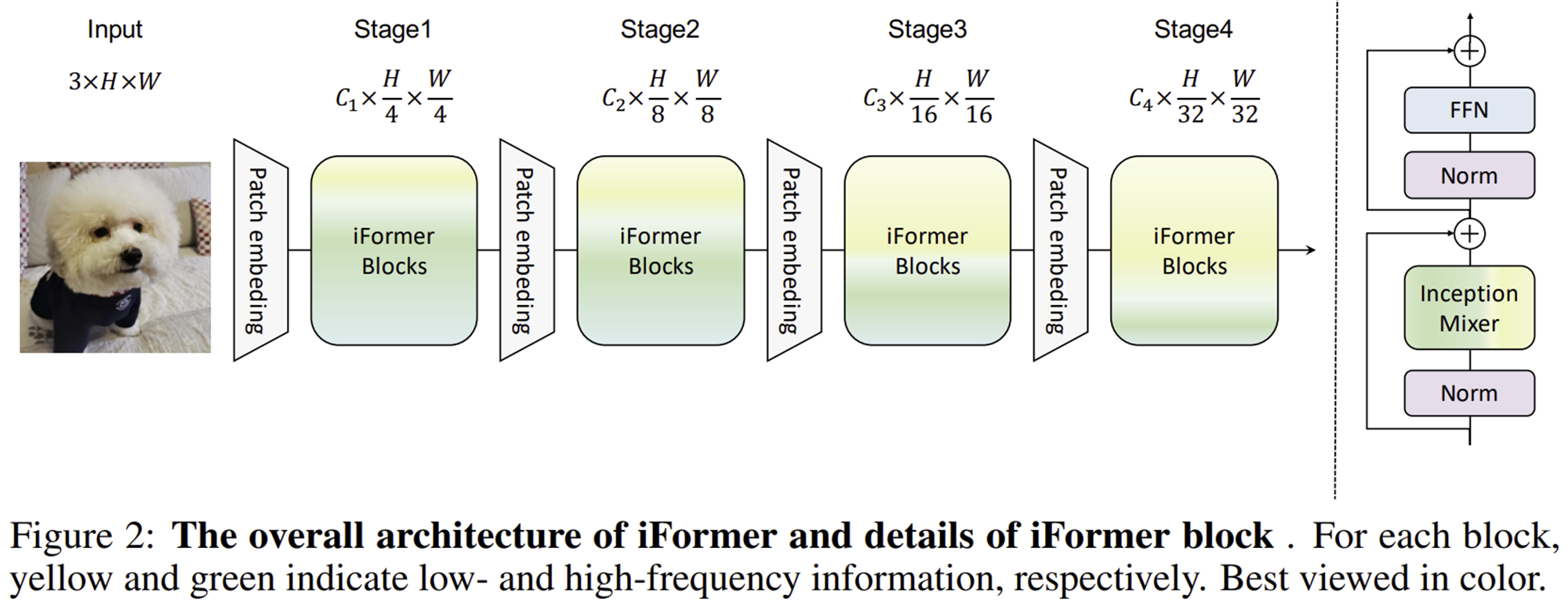
이러한 MHSA를 바꾸는 것이 오늘 소개할 Inception Transformer (iFormer)의 핵심입니다. 먼저 그림 2는 iFormer의 전체적인 구조를 보여주고 있습니다. 여느 ViT 구조와 마찬가지로 4개의 스테이지로 구성되어 있으며 hierarchical architecture를 가지는 것은 동일합니다. 여기서 중요한 것은 iFormer Block을 도입했다는 점이죠. 각 iFormer Block은 오른쪽 그림과 같이 구성되어 있습니다. 그런데 기존의 ViT에서는 MHSA를 사용했지만 본 논문에서는 Inception Mixer라는 새로운 Token Mixer를 도입한 것을 볼 수 있습니다.
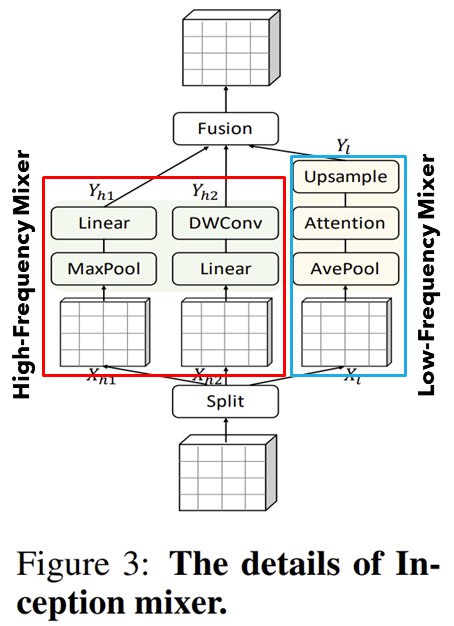
그림 3은 본 논문에서 제안하는 Inception Token Mixer의 전체적인 구조를 보여주고 있습니다. 여기서 오른쪽은 기존의 ViT에서 사용하는 MHSA로 본 논문에서는 이를 low-frequency mixer로 칭하고 있습니다. 반대로 왼쪽은 Max-Pooling과 CNN기반으로 구성된 token mixer로 high-frequency mixer로 부르고 있죠.
본 논문에서는 위와 같이 입력 특징 맵 $\mathbf{X} \in \mathbb{R}^{N \times C}$을 먼저 채널단위로 split ($\mathbf{X}_{l} \in \mathbb{R}^{N \times C_{l}}$ & $\mathbf{X}_{h} \in \mathbb{R}^{N \times C_{h}}$)하여 high-frequency와 low-frequency mixer에 각각 입력을 수행합니다. 여기서 $C = C_{h} + C_{l}$를 만족합니다.
그리고 high-frequency mixer부터 설명하자면 다시 두개의 특징 맵 $\mathbf{X}_{h_{1}}, \mathbf{X}_{h_{2}} \in \mathbb{R}^{N \times \frac{C_{h}}{2}}$로 분할하여 Max pooling branch와 DWConv branch로 각각 입력하게 됩니다.
반대로 low-frequency mixer에서는 연산량을 줄이기 위해 average pooling을 적용하여 $\mathbf{X}_{l}$의 spatial resolution을 어느정도 줄인 뒤 self-attention을 수행합니다. 다음으로 다시 original feature map size로 upsampling을 수행하여 복원합니다.
그러면 총 3개의 feature map $\mathbf{Y}_{h_{1}}, \mathbf{Y}_{h_{2}}, \mathbf{Y}_{l}$을 얻을 수 있습니다. 마지막 단계로는 각 feature map들을 하나로 fusion시켜 주게 됩니다.
$$\mathbf{Y} = \textbf{FC} (\mathbf{Y}_{c} + \textbf{DWConv} (\mathbf{Y}_{c}))$$
여기서 $\mathbf{Y}_{c} = \textbf{Concat} (\mathbf{Y}_{h_{1}}, \mathbf{Y}_{h_{2}}, \mathbf{Y}_{l})$로 각 출력 특징 맵의 채널 차원의 concatentation으로 정의됩니다.
위 과정을 전체적으로 정리하면 다음과 같습니다.
$$\begin{cases} \mathbf{Y} &= \mathbf{X} + \textbf{ITM} (\textbf{LN} (\mathbf{X})) \\ \mathbf{H} &= \mathbf{Y} + \textbf{FFN} (\textbf{LN} (\mathbf{Y}) ) \end{cases}$$
3) Frequency Ramp Structure
이전 논문들의 결과에 따르면 deep layer는 high-frequency detail 그리고 shallow layer는 low-frequency global information 더 필요하다는 것을 볼 수 있었습니다. 따라서, inception token mixer에서 high-frequency와 low-frequency를 깊이에 따라 다르게 나누면 더 좋은 결과를 얻을 수 있을 것으로 예상할 수 있겠죠? 따라서 본 논문에서는 각 stage 별로 high-frequency $\frac{C_{h}}{C}$와 low-frequency $\frac{C_{l}}{C}$를 다르게 설정하여 iFormer가 모든 계층에서 유연하게 high/low-frequency 특성을 동시에 학습할 수 있게 구현하였습니다.
4) Model Configuration

Experiment Results
1) ImageNet-1K
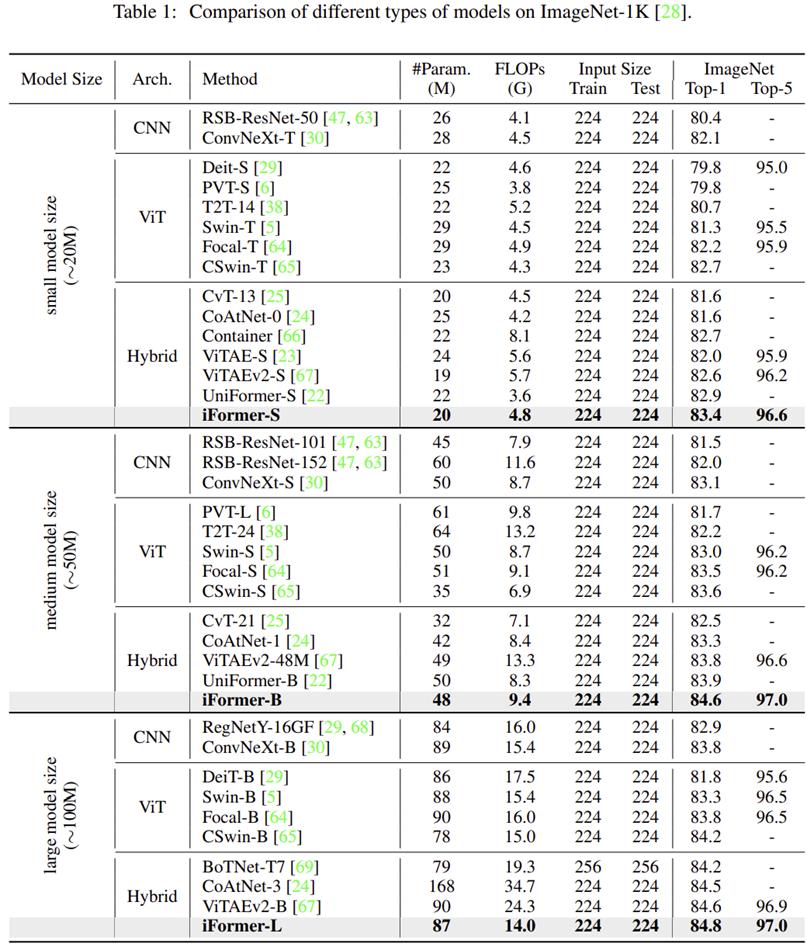
2) ImageNet-1K with Larger Resolution
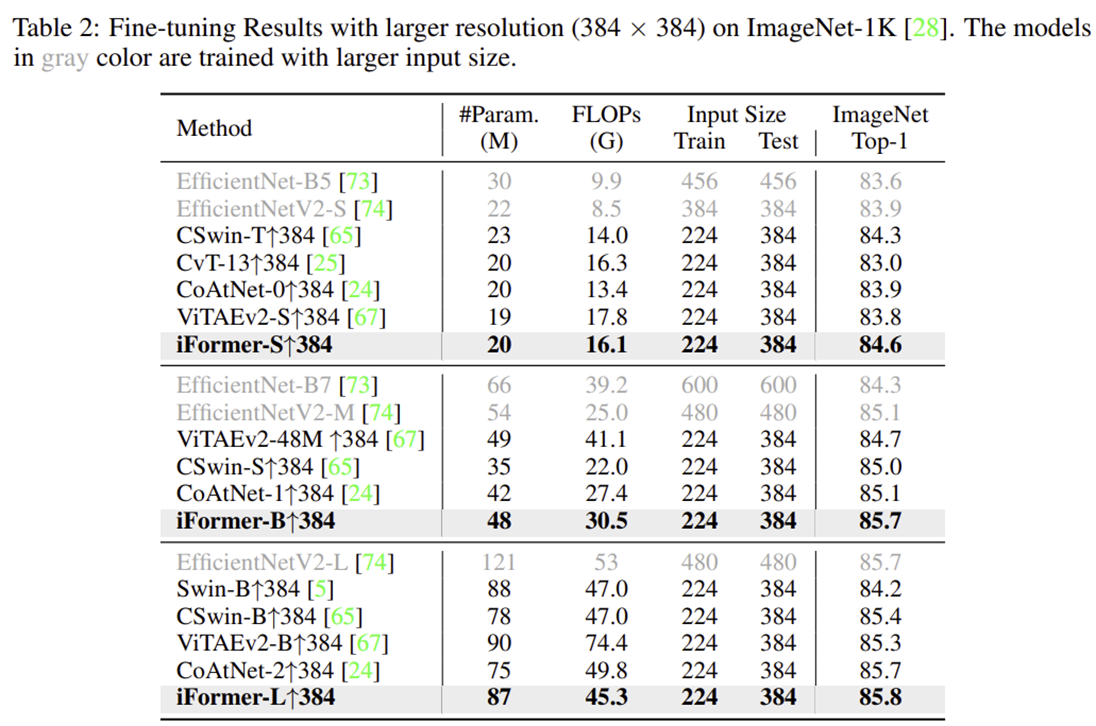
3) Object Detection
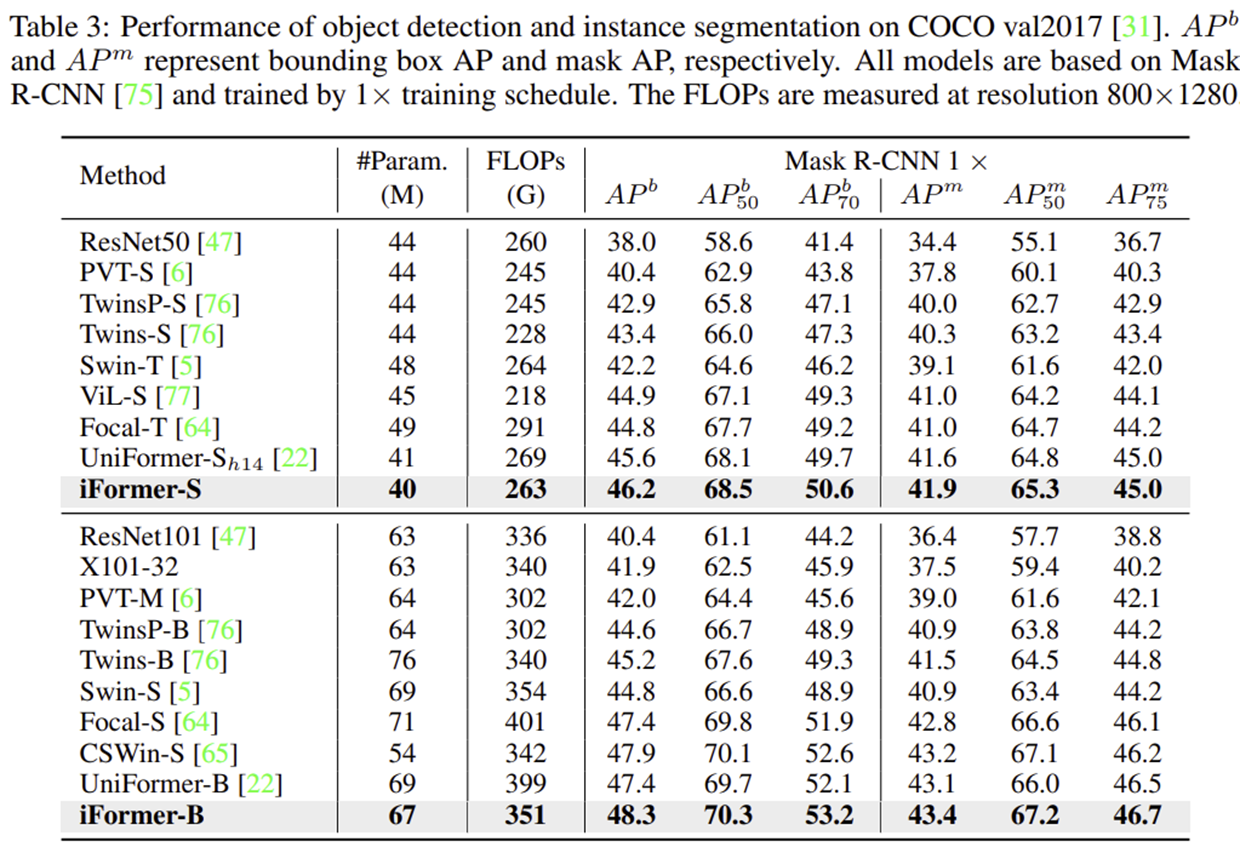
4) Semantic Segmentation
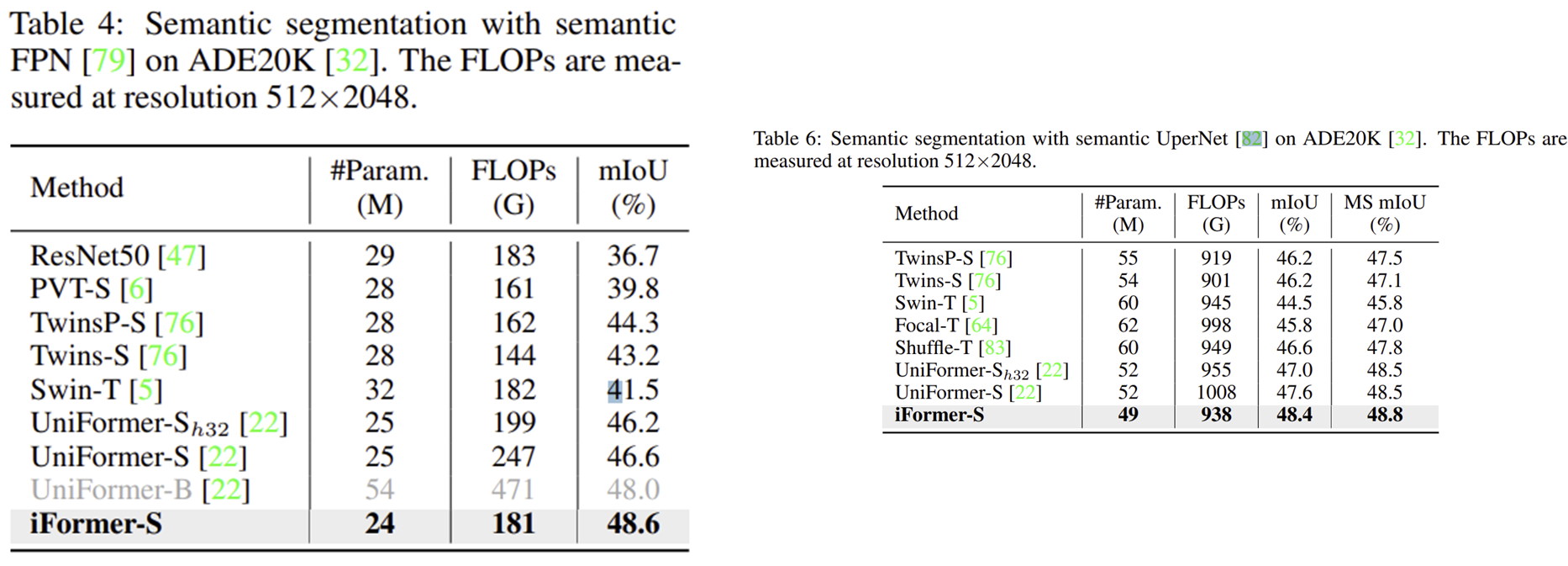
5) Ablation Study
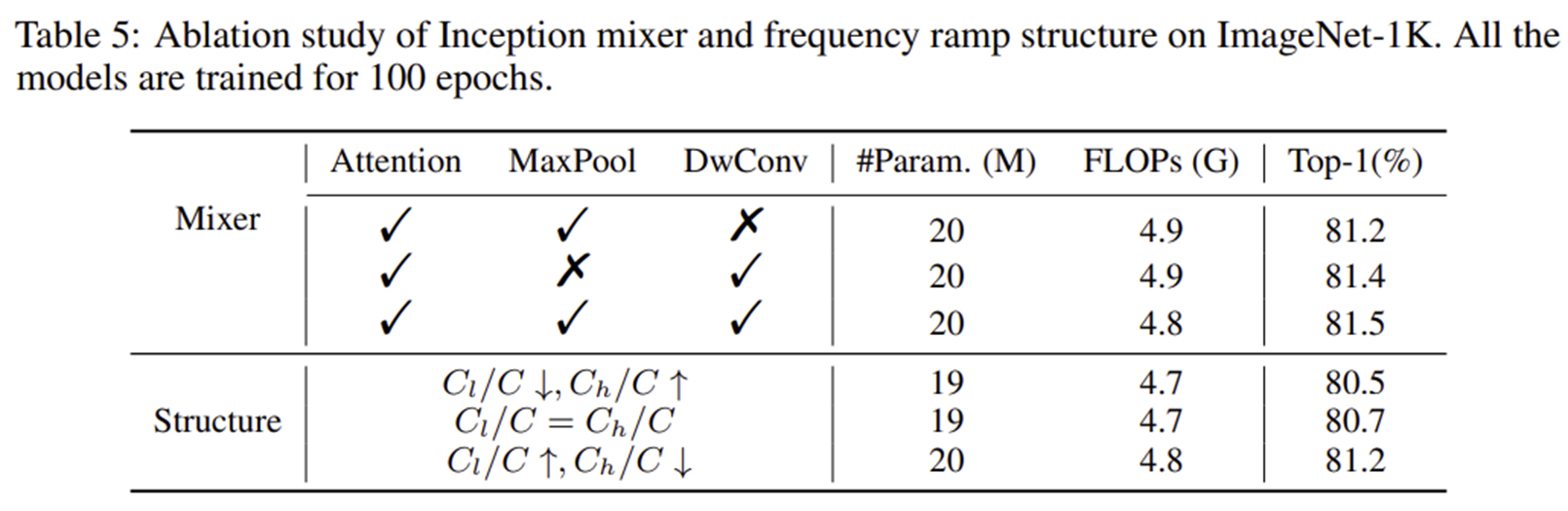
5-1) Inception Mixer and Frequency Ramp Structure
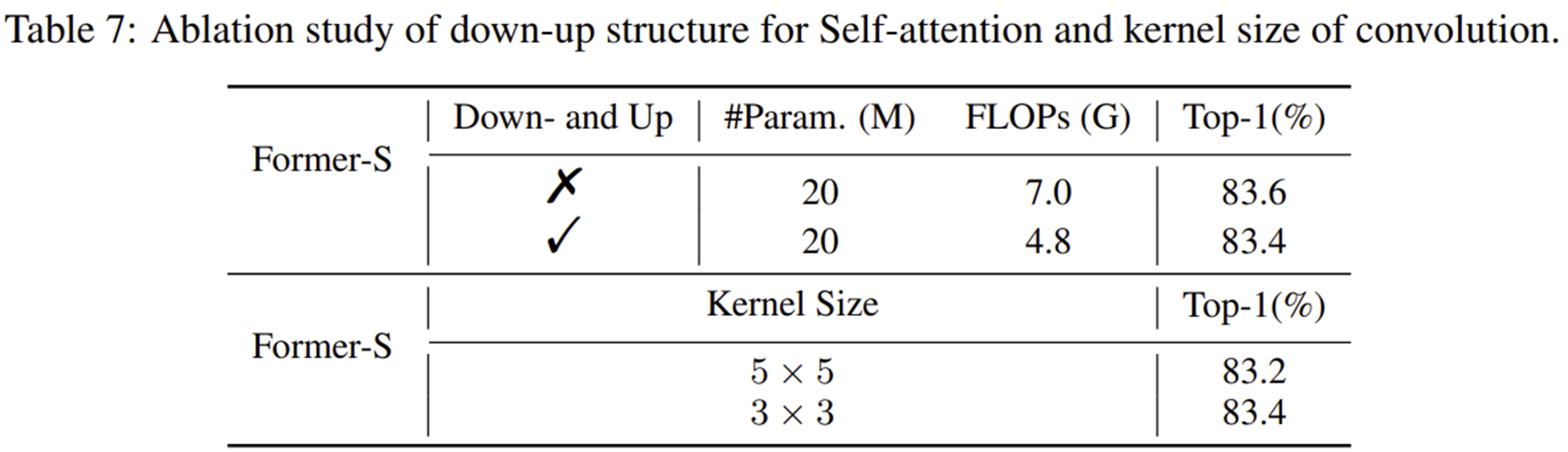
5-2) Down-sample and Up-sample for Self-Attention
6) Feature Visualization
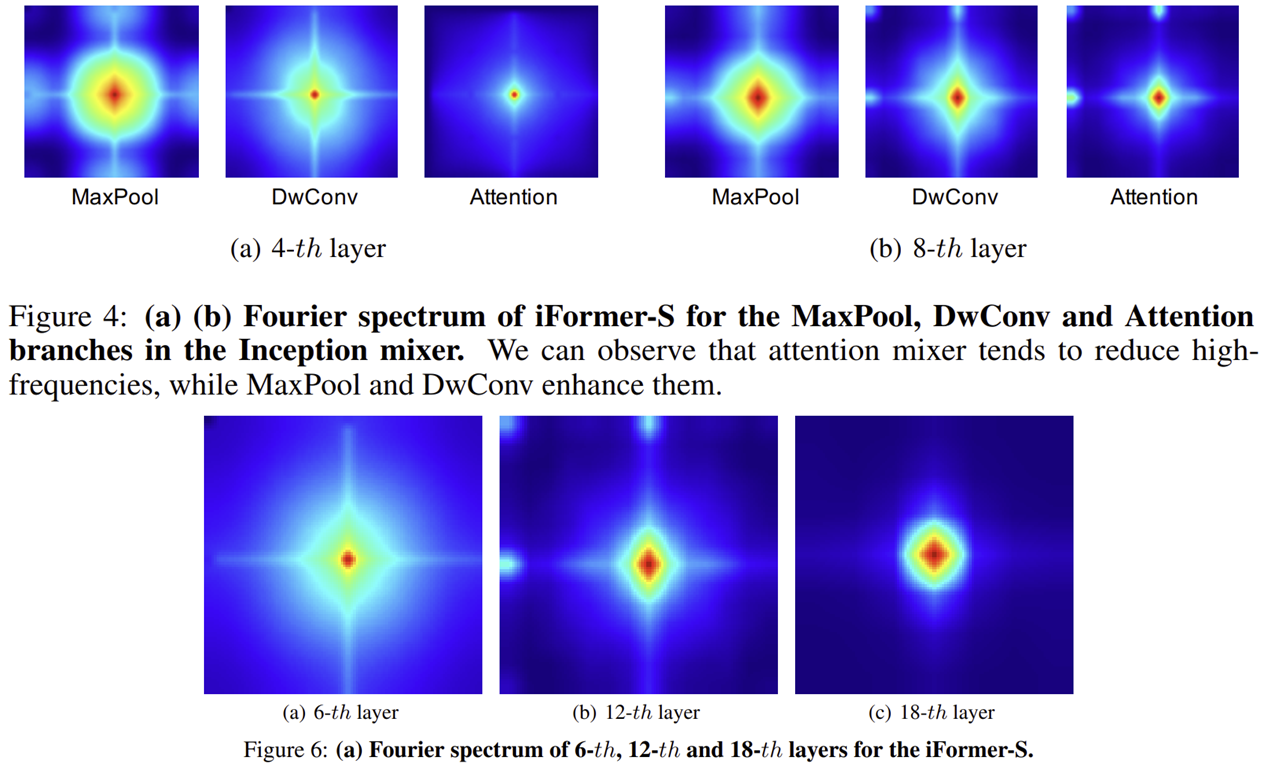
6-1) Fourier Spectrum Analysis
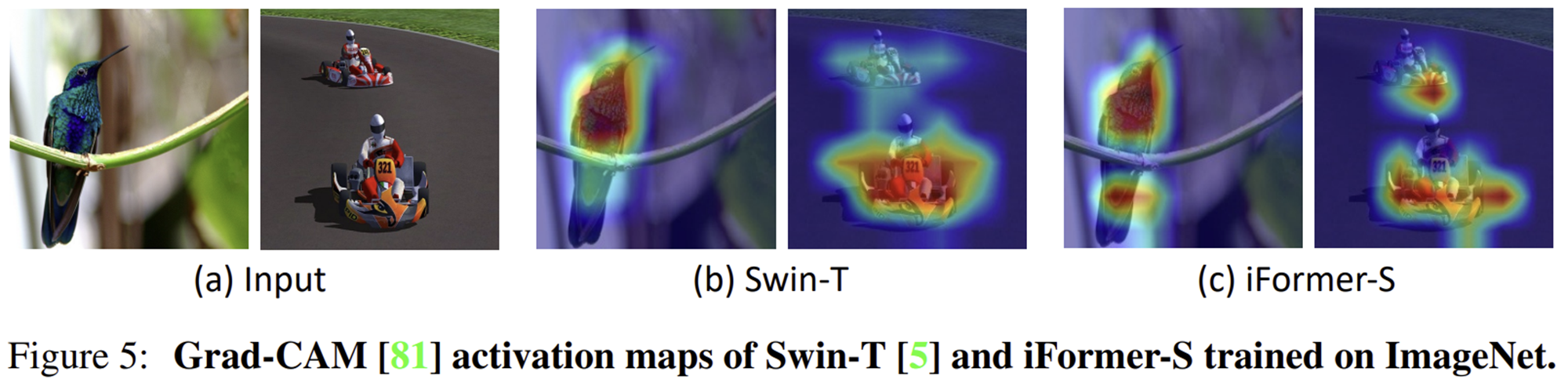
6-2) Grad-CAM
Code Implementation
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, IMAGENET_INCEPTION_MEAN, IMAGENET_INCEPTION_STD
from timm.models.layers import Mlp, DropPath, to_2tuple
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'iformer_small': _cfg(url='https://huggingface.co/sail/dl2/resolve/main/iformer/iformer_small.pth'),
'iformer_base': _cfg(url='https://huggingface.co/sail/dl2/resolve/main/iformer/iformer_base.pth'),
'iformer_large': _cfg(url='https://huggingface.co/sail/dl2/resolve/main/iformer/iformer_large.pth')
}
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
embed_dim=768,
norm_layer=None,
flatten=False,
bias=True,
):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=2, bias=bias, padding=1)
self.norm = nn.BatchNorm2d(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
# _assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
# _assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
class FirstPatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self,
kernel_size: int=3,
stride: int=2,
padding: int=1,
in_chans: int=3,
embed_dims: int=768,) -> None:
super(FirstPatchEmbed, self).__init__()
self.proj1 = nn.Conv2d(in_chans, embed_dims // 2, kernel_size=kernel_size, stride=stride, padding=padding)
self.norm1 = nn.BatchNorm2d(embed_dims // 2)
self.gelu1 = nn.GELU()
self.proj2 = nn.Conv2d(embed_dims // 2, embed_dims, kernel_size=kernel_size, stride=stride, padding=padding)
self.norm2 = nn.BatchNorm2d(embed_dims)
def forward(self, x) -> torch.Tensor:
# [B, C, H, W] -> [B, H, W, C]
x = self.proj1(x)
x = self.norm1(x)
x = self.gelu1(x)
x = self.proj2(x)
x = self.norm2(x)
x = x.permute(0, 2, 3, 1)
return x
class HighMixer(nn.Module):
def __init__(self,
dim: int,
kernel_size: int=3,
stride: int=1,
padding: int=1,
**kwargs) -> None:
super(HighMixer, self).__init__()
self.cnn_in = cnn_in = dim // 2
self.pool_in = pool_in = dim // 2
self.cnn_dim = cnn_dim = cnn_in * 2
self.pool_dim = pool_dim = pool_in * 2
self.conv1 = nn.Conv2d(cnn_in, cnn_dim, kernel_size=1, stride=1, padding=0, bias=False)
self.proj1 = nn.Conv2d(cnn_dim, cnn_dim, kernel_size=kernel_size, stride=stride, padding=padding, bias=False, groups=cnn_dim)
self.mid_gelu1 = nn.GELU()
self.Maxpool = nn.MaxPool2d(kernel_size, stride=stride, padding=padding)
self.proj2 = nn.Conv2d(pool_in, pool_dim, kernel_size=1, stride=1, padding=0)
self.mid_gelu2 = nn.GELU()
def forward(self, x):
cx = x[:, :self.cnn_in, :, :].contiguous()
cx = self.conv1(cx)
cx = self.proj1(cx)
cx = self.mid_gelu1(cx)
px = x[:, self.cnn_in:, :, :].contiguous()
px = self.Maxpool(px)
px = self.proj2(px)
px = self.mid_gelu2(px)
return torch.cat([cx, px], dim=1)
class LowMixer(nn.Module):
def __init__(self,
dim: int,
num_heads: int=8,
qkv_bias: bool=False,
attn_drop: float=0.,
pool_size: int=2) -> None:
super(LowMixer, self).__init__()
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.dim = dim
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.pool = nn.AvgPool2d(pool_size, stride=pool_size, padding=0, count_include_pad=False) if pool_size > 1 else nn.Identity()
self.unpool = nn.Upsample(scale_factor=pool_size, mode='nearest') if pool_size > 1 else nn.Identity()
def att_fun(self, q, k, v, B, N, C):
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = (attn @ v).transpose(2, 3).reshape(B, C, N)
return x
def forward(self, x):
B, _, _, _ = x.shape
xa = self.pool(x)
xa = xa.permute(0, 2, 3, 1).reshape(B, -1, self.dim)
B, N, C = xa.shape
qkv = self.qkv(xa).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(dim=0)
xa = self.att_fun(q, k, v, B, N, C)
xa = xa.view(B, C, int(N ** 0.5), int(N ** 0.5))
xa = self.unpool(xa)
return xa
class Mixer(nn.Module):
def __init__(self,
dim: int,
num_heads: int=8,
qkv_bias: bool=False,
attn_drop: float=0.,
proj_drop: float=0.,
attention_head: int=1,
pool_size: int=2,
**kwargs) -> None:
super(Mixer, self).__init__()
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
self.low_dim = low_dim = attention_head * head_dim
self.high_dim = high_dim = dim - low_dim
self.high_mixer = HighMixer(high_dim)
self.low_mixer = LowMixer(low_dim, num_heads=attention_head, qkv_bias=qkv_bias, attn_drop=attn_drop, pool_size=pool_size)
self.conv_fuse = nn.Conv2d(low_dim+high_dim*2, low_dim+high_dim*2, kernel_size=3, stride=1, padding=1, bias=False, groups=low_dim+high_dim*2)
self.proj = nn.Conv2d(low_dim+high_dim*2, dim, kernel_size=1, stride=1, padding=0)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
x = x.permute(0, 3, 1, 2)
hx = x[:, :self.high_dim, :, :].contiguous()
hx = self.high_mixer(hx)
lx = x[:, self.high_dim:, :, :].contiguous()
lx = self.low_mixer(lx)
if lx.shape[-1] != hx.shape[-1]:
lx = F.interpolate(lx, size=(hx.shape[-2], hx.shape[-1]), mode='bilinear', align_corners=True)
x = torch.cat([hx, lx], dim=1)
x = x + self.conv_fuse(x)
x = self.proj(x)
x = self.proj_drop(x)
x = x.permute(0, 2, 3, 1).contiguous()
return x
class Block(nn.Module):
def __init__(self,
dim: int,
num_heads: int=8,
mlp_ratio: float=4.,
qkv_bias: bool=True,
drop: float=0.,
attn_drop: float=0.,
drop_path: float=0.,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
attention_heads: int=1,
pool_size: int=2,
attn=Mixer,
use_layer_scale=False,
layer_scale_init_value=1e-5) -> None:
super(Block, self).__init__()
self.norm1 = norm_layer(dim)
self.attn = attn(dim=dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, attention_head=attention_heads, pool_size=pool_size)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.use_layer_scale = use_layer_scale
if self.use_layer_scale:
self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2 * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class InceptionTransformer(nn.Module):
def __init__(self,
img_size: int=224,
patch_size: int=16,
in_chans: int=3,
num_classes: int=1000,
embed_dims=None,
depths=None,
num_heads=None,
mlp_ratio: float=4.,
qkv_bias: bool=True,
drop_rate: float=0., attn_drop_rate: float=0., drop_path_rate: float=0.,
embed_layer=PatchEmbed, norm_layer=None, act_layer=None,
weight_init='',
attention_heads=None,
use_layer_scale: bool=False, layer_scale_init_value: float=1e-5,
**kwargs) -> None:
super(InceptionTransformer, self).__init__()
st2_idx = sum(depths[:1])
st3_idx = sum(depths[:2])
st4_idx = sum(depths[:3])
depth = sum(depths)
self.num_classes = num_classes
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.patch_embed = FirstPatchEmbed(in_chans=in_chans, embed_dims=embed_dims[0])
self.num_patches1 = num_patches = img_size // 4
self.pos_embed1 = nn.Parameter(torch.zeros(1, num_patches, num_patches, embed_dims[0]))
self.blocks1 = nn.Sequential(*[
Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer,
attention_heads=attention_heads[i], pool_size=2,
)
for i in range(0, st2_idx)
])
self.patch_embed2 = PatchEmbed(img_size=img_size // 4, patch_size=3, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.num_patches2 = num_patches = num_patches // 2
self.pos_embed2 = nn.Parameter(torch.zeros(1, num_patches, num_patches, embed_dims[1]))
self.blocks2 = nn.Sequential(*[
Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer,
attention_heads=attention_heads[i], pool_size=2,
)
for i in range(st2_idx, st3_idx)
])
self.patch_embed3 = PatchEmbed(img_size=img_size // 8, patch_size=3, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.num_patches3 = num_patches = num_patches // 2
self.pos_embed3 = nn.Parameter(torch.zeros(1, num_patches, num_patches, embed_dims[2]))
self.blocks3 = nn.Sequential(*[
Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer,
attention_heads=attention_heads[i], pool_size=2,
use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value,
)
for i in range(st3_idx, st4_idx)
])
self.patch_embed4 = PatchEmbed(img_size=img_size // 16, patch_size=3, in_chans=embed_dims[2], embed_dim=embed_dims[3])
self.num_patches4 = num_patches = num_patches // 2
self.pos_embed4 = nn.Parameter(torch.zeros(1, num_patches, num_patches, embed_dims[3]))
self.blocks4 = nn.Sequential(*[
Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer,
attention_heads=attention_heads[i], pool_size=2,
use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value,
)
for i in range(st4_idx, depth)
])
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
output = []
x = self.patch_embed(x)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed1, self.num_patches1, H, W)
x = self.blocks1(x)
x = x.permute(0, 3, 1, 2)
output.append(x)
x = self.patch_embed2(x)
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed2, self.num_patches2, H, W)
x = self.blocks2(x)
x = x.permute(0, 3, 1, 2)
output.append(x)
x = self.patch_embed3(x)
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed3, self.num_patches3, H, W)
x = self.blocks3(x)
x = x.permute(0, 3, 1, 2)
output.append(x)
x = self.patch_embed4(x)
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed4, self.num_patches4, H, W)
x = self.blocks4(x)
x = x.permute(0, 3, 1, 2)
output.append(x)
return output
# def forward(self, x):
# x = self.forward_features(x)
# x = self.head(x)
#
# return x
def _get_pos_embed(self, pos_embed, num_patches_def, H, W):
if H * W == num_patches_def * num_patches_def:
return pos_embed
else:
return F.interpolate(pos_embed.permute(0, 3, 1, 2), size=(H, W), mode='bilinear').permute(0, 2, 3, 1)
@register_model
def iformer_small(pretrained=False, **kwargs):
"""
19.866M 4.849G 83.382
"""
depths = [3, 3, 9, 3]
embed_dims = [96, 192, 320, 384]
num_heads = [3, 6, 10, 12]
attention_heads = [1] * 3 + [3] * 3 + [7] * 4 + [9] * 5 + [11] * 3
model = InceptionTransformer(img_size=224,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads,
use_layer_scale=True, layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['iformer_small']
if pretrained:
url = model.default_cfg['url']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
@register_model
def iformer_base(pretrained=False, **kwargs):
"""
47.866M 9.379G 84.598
"""
depths = [4, 6, 14, 6]
embed_dims = [96, 192, 384, 512]
num_heads = [3, 6, 12, 16]
attention_heads = [1] * 4 + [3] * 6 + [8] * 7 + [10] * 7 + [15] * 6
model = InceptionTransformer(img_size=224,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads,
use_layer_scale=True, layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['iformer_base']
if pretrained:
url = model.default_cfg['url']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
@register_model
def iformer_large(pretrained=False, **kwargs):
"""
86.637M 14.048G 84.752
"""
depths = [4, 6, 18, 8]
embed_dims = [96, 192, 448, 640]
num_heads = [3, 6, 14, 20]
attention_heads = [1] * 4 + [3] * 6 + [10] * 9 + [12] * 9 + [19] * 8
model = InceptionTransformer(img_size=224,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads,
use_layer_scale=True, layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['iformer_large']
if pretrained:
url = model.default_cfg['url']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
model = iformer_small(pretrained=True)
print(model)
inp = torch.randn(1, 3, 224, 224)
output = model.forward_features(inp)
print(output[0].shape)
print(output[1].shape)
print(output[2].shape)
print(output[3].shape)