안녕하세요. 지난 포스팅의 [Transformer] Incorporating Convolution Designs into Visual Transformers (ICCV2021)에서는 CeiT 에 대해서 알아보았습니다. 핵심은 CNN의 low-level feature와 Transformer의 Long-range dependency를 결합하기 위해 Image-to-Token (I2T), Locally-enhanced Feed-Forward (LeFF) 그리고 Layer-wise Class Token Attention (LCA)를 도입하였습니다. 오늘은 CNN을 Transformer에 결합하기 위한 새로운 시도 중 하나인 LeViT에 대해서 설명드리도록 하겠습니다.
Background
CvT 그리고 CeiT에서와 마찬가지로 본 논문에서도 ViT의 근본적인 문제인 large-scale 데이터셋의 의존성을 강조합니다. 물론 DeiT도 이후에 제안되었지만 teacher 모델과 distillation type에 따른 성능 변화가 너무 커서 적절한 조합을 찾는 것이 중요하기 때문에 실용성이 떨어진다는 문제점이 있죠. 뿐만 아니라 가장 중요한 문제점은 ViT와 DeiT 모두 컴퓨터 비전과 관련된 문제를 해결하기 위해 중요한 inductive bias가 부족하다는 것이죠.
본 논문에서는 이러한 문제를 해결하기 위해 일차적으로 ViT와 DeiT의 구조를 좀 더 자세히 분석합니다. 그리고 CNN 구조를 결합하기 위해 기존 ViT에서 사용했던 ResNet-50을 patch extractor로 적용하는 실험을 수행합니다. 이를 기반으로 새롭게 제안된 LeViT는 ViT의 구조를 차용하고 DeiT의 학습 방식을 활용하여 다양한 플랫폼 (GPU, Intel CPU, ARM)에서 모두 높은 효율성을 가지게 되었습니다.
Motivation
1) Convolution in the ViT Architecture

그림 2와 같이 Vision Transformer 기반 모델 중 하나인 DeiT의 attention weight를 시각화해보겠습니다. 그러면 여기서 몇 가지 관찰점이 보입니다.
- Attention head는 특정 패턴에 집중되어 weight가 만들어진다.
- Gabor Filter와 어느정도 유사한 모양이다.
또한, CNN은 convolution mask를 입력 특징맵을 이동하면서 조금씩 겹치면서 다음 특징맵을 추출하기 됩니다. 이 과정에서 CNN은 "spatial smoothness"를 얻을 수 있게 된다고 합니다. 비록, ViT에서는 이러한 작업이 없지만 데이터 증강으로 인해 CNN과 같이 유사한 "spatial smoothness" 효과를 달성한다고 합니다.
이와 같은 이유로 비록 Transformer가 CNN과 같이 inductive bias를 가지고 있지 않음에도 불구하고 CNN과 거의 유사한 필터 (attention weight)를 만들 수 있다고 합니다.
2) Preliminary Experiment: Grafting
한편 ViT에서는 patch extractor로 ResNet-50을 사용하는 것도 가능하다고 언급합니다. 비록 이와 같은 방식은 CNN이 가지고 있는 inductive bias를 활용할 수 있는 방법이지만 굉장히 높은 계산비용이 요구되기 때문에 비효율적이죠. 그렇다면 ResNet-50과 ViT를 활용할 때 전체 Stage를 이용하지 않고 몇몇 계층만 이용한다면 어느정도 연산량을 크게 줄일 수 있지 않을까요? 따라서, 본 논문에서는 ResNet-50과 DeiT-Small을 이용해 CNN과 Transformer의 stage 개수를 바꾸어보며 파라미터, FLOPs, Speed, 그리고 ImageNet-1K에서의 성능을 평가합니다.
표 1은 해당 실험의 결과를 보여주고 있습니다. 결과적으로 DeiT-Small만 사용 (첫번째 행)하거나 ResNet-50만 사용 (마지막 행)에 비해 두 구조를 적절히 섞어주는 것이 항상 좋은 결과를 낸다는 것을 알 수 있습니다. 또한 그림 3에서는 두 구조가 섞인 모델은 학습과정에서 ResNet-50과 초기 학습에서는 어느정도 유사했지만 중반 이후에는 DeiT-Small의 수렴 속도와 거의 유사해지는 것을 볼 수 있습니다.
LeViT
1) Overall Architecture
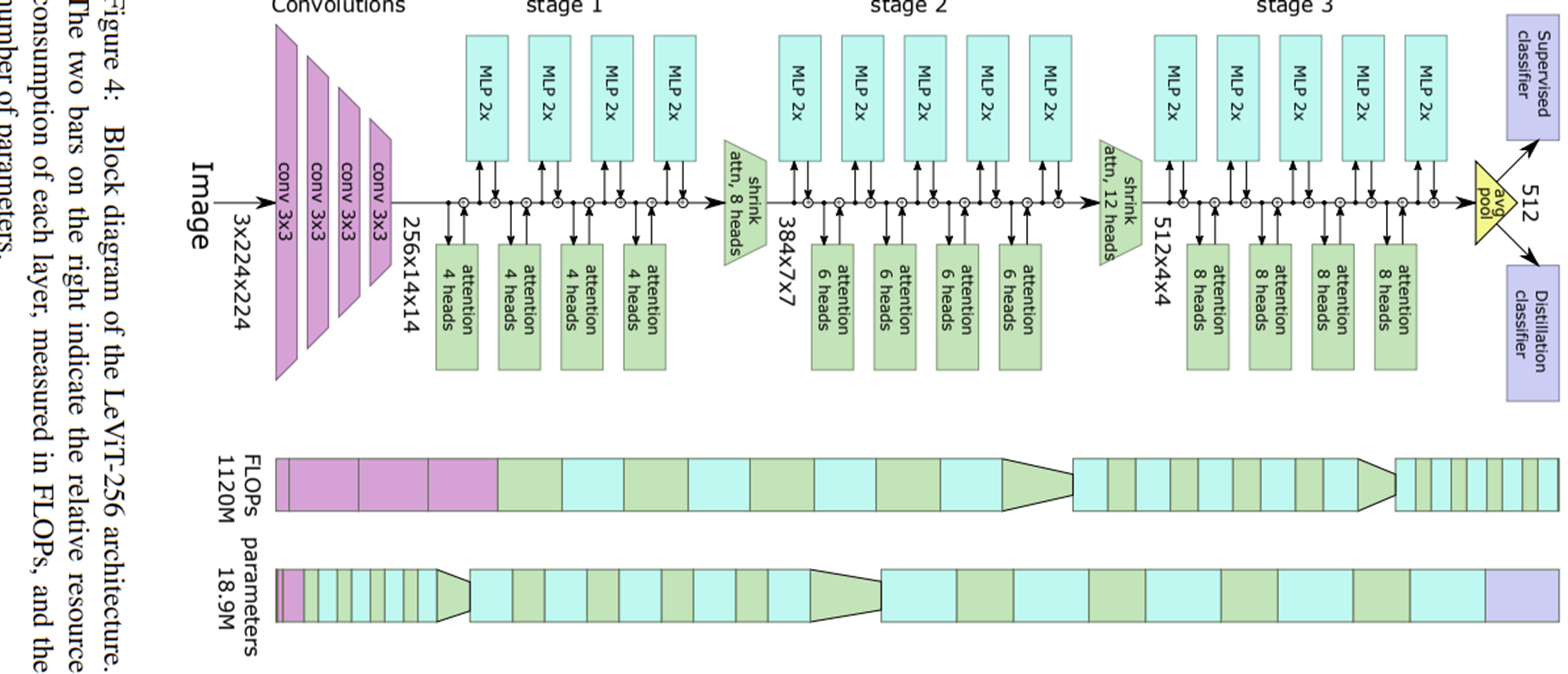
그림 4는 LeVit의 전체적인 블록 다이어그램을 보여주고 있습니다. 처음에 말씀드린 것처럼 입력 영상이 주어지면 CNN 모델을 이용해 패치를 추출한 뒤 ViT와 유사한 구조를 통과하는 것을 볼 수 있습니다. 다만 전체적인 학습과정은 DeiT를 사용하였기 때문에 distillation token이 있는 것을 볼 수 있습니다.
2) LeViT Components
본 논문에서는 LeViT의 핵심 성분 별로 정리를 해놓았습니다. 본문에는 훨씬 더 많은 데 중요한 성분 정리해놓도록 하겠습니다.
Patch Embedding
처음에 설명드린대로 ResNet-50과 같이 대규모 CNN 구조를 이용하여 패치를 추출할 수도 있지만 이는 연산량에 부담이 됩니다. 본 논문의 목표는 "더 빠른 추론 속도"를 얻을 수 있는 Transformer 구조를 만드는 것을 목표로 하기 때문에 4개의 계층을 가지는 단순한 $3 \times 3$ 크기의 커널에 stride 2를 가지는 합성곱을 이용합니다. 그리고 각 합성곱 계층을 통과하게 되면 특징 맵의 채널 개수는 $\{ 3, 32, 64, 128, 256 \}$으로 늘어나게 됩니다. 최종적으로 패치의 형상은 $(3, 224, 224) \rightarrow (256, 14, 14)$로 줄어들게 됩니다. 이때, 184 MFLOPs를 사용하게 되는 데 ResNet-18을 사용할 경우 1042 MFLOPs인 것과 비교해보면 매우 큰 차이로 줄어든 것을 볼 수 있습니다. 만약, ResNet-18이 아닌 ResNet-50으로 비교했다면 훨씬 더 큰 연산량 감소를 얻을 수 있었을 것 입니다.
Normalization layers and Activations
일반적으로 Fully-Connected Layer (FCL)는 연산량을 굉장히 많이 차지하게 됩니다. 이러한 문제를 해결하기 위해 본 논문에서는 MLP 단계의 FCL을 $1 \times 1$ 합성곱 계층으로 바꾸어줍니다. 그리고 각 합성곱 계층 다음에 배치 정규화를 적용하죠. 마지막으로 활성화 함수로 기존에 많이 사용하던 GeLU가 아닌 h-swish를 사용해주었습니다.
Multi-Resolution Pyramid and Shrinking Attention Block
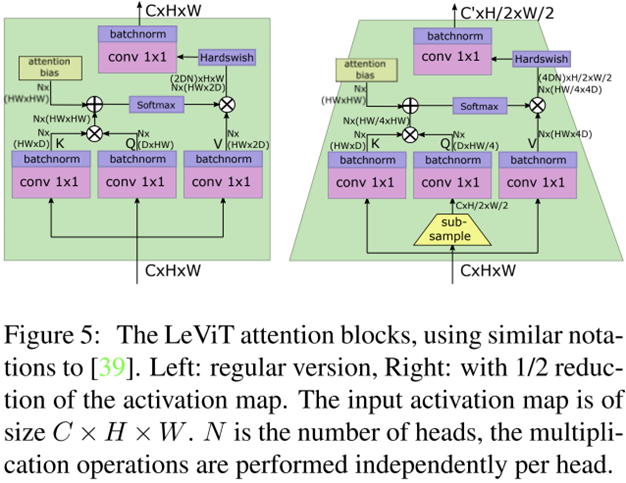
기존의 ViT는 CNN과 같이 계층적 구조를 활용하지 못하기 때문에 입력 영상으로부터 multi-scale feature를 추출하지 못한다는 단점이 있습니다. 물론 이러한 문제를 해결하는 다른 논문인 PVT도 있었죠. LeViT에서는 Query 벡터에 sub-sampling을 적용하여 spatial resolution을 줄여주는 방식으로 연산량을 줄이는 방식을 선택합니다. 또한, 이는 multi-scale 구조를 활용하기 때문에 향후 dense prediction과 같은 task에서 좋은 성능을 보일 수도 있습니다 (본문에서는 실험은 없습니다.).
Attention Bias instead of Positional Embedding
일반적으로 Positional Embedding은 local-dependent한 학습가능한 파라미터를 token embedding에 더해주어 token 간 위치 정보를 부여해주는 방식입니다. 하지만, 입력 토큰에만 해당 연산을 수행하고 각 attention block에서는 수행하지 않죠. 본 논문에서 고민하는 것은 attention block에 relative positional information을 주입하는 것 입니다.
본 논문에서 그래서 생각한 것이 Attention Bias입니다. 이는 다음과 같은 연산으로 수행됩니다.
$$A^{h}_{(x, y), (x^{'}, y^{'})} = Q_{(x, y), :} \cdot K_{(x^{'}, y^{'}), :} + B^{h}_{| x - x^{'} |, |y - y^{'}|}$$
여기서 첫번째 항은 일반적인 Attention을 수행하기 위한 단계입니다. 중요한 것은 두번째 항으로 Translation-invariant한 attention bias를 의미하죠. 각 토큰의 좌표 $(x, y)$를 이용해 상대적 위치 정보를 주입해줍니다. 이때, 절댓값을 적용했기 때문에 flip에 invariace한 정보를 얻을 수가 있겠죠.
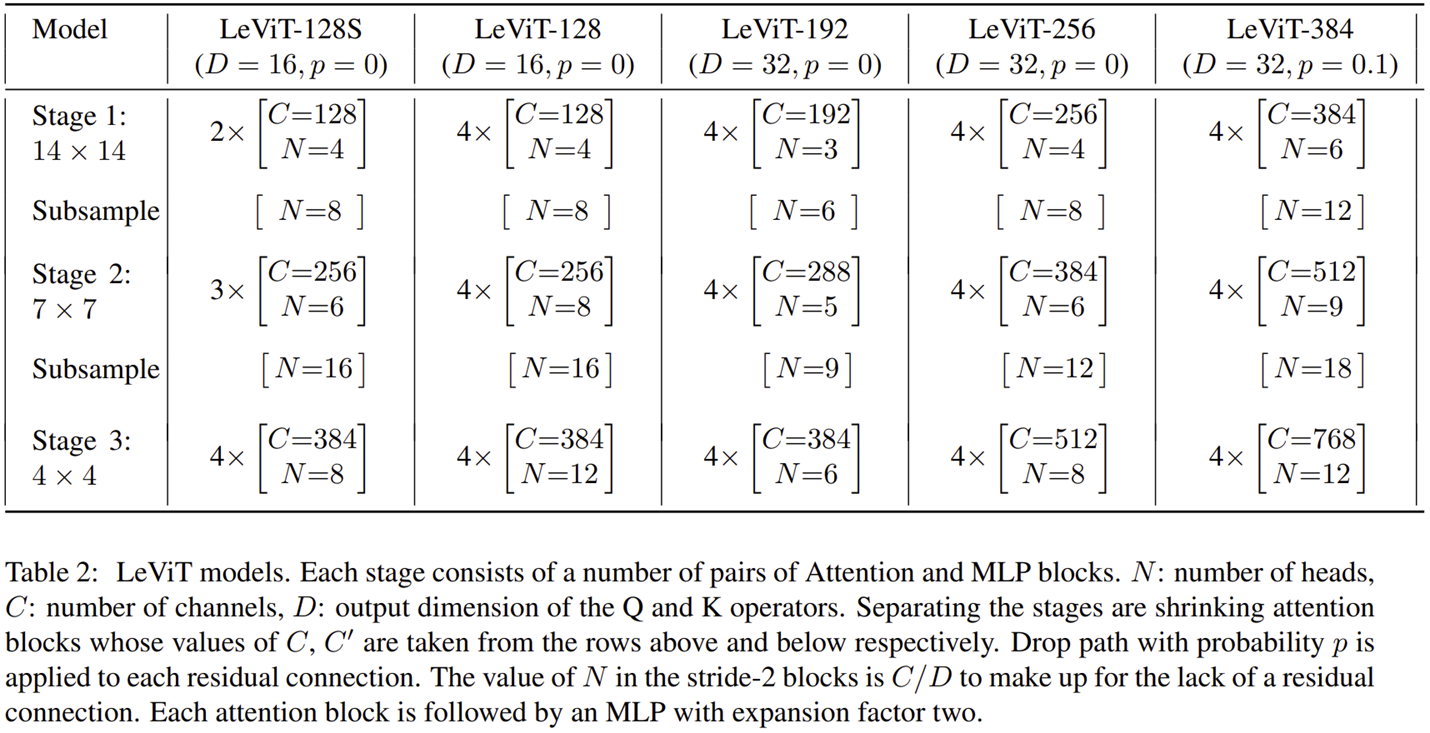
LeViT Model Variants
Experiment Results
1) ImageNet Classification
- Dataset
- ImageNet-1K: 1.28 million training images & 50K validation images with 1,000 classes
- Data Augmentation (Same as DeiT): random cropping, random horizontal flipping, label-smooting regularization, MixUp, CutMix, Random Erasing
- Teacher Model: RegNetY-16GF
- Optimization: -
- batch size: -
- epochs: 300
- 16GB NVIDIA Volta GPU & Intel Xeon 6138 CPU at 2.0 GHz & ARM Graviton2 CPU
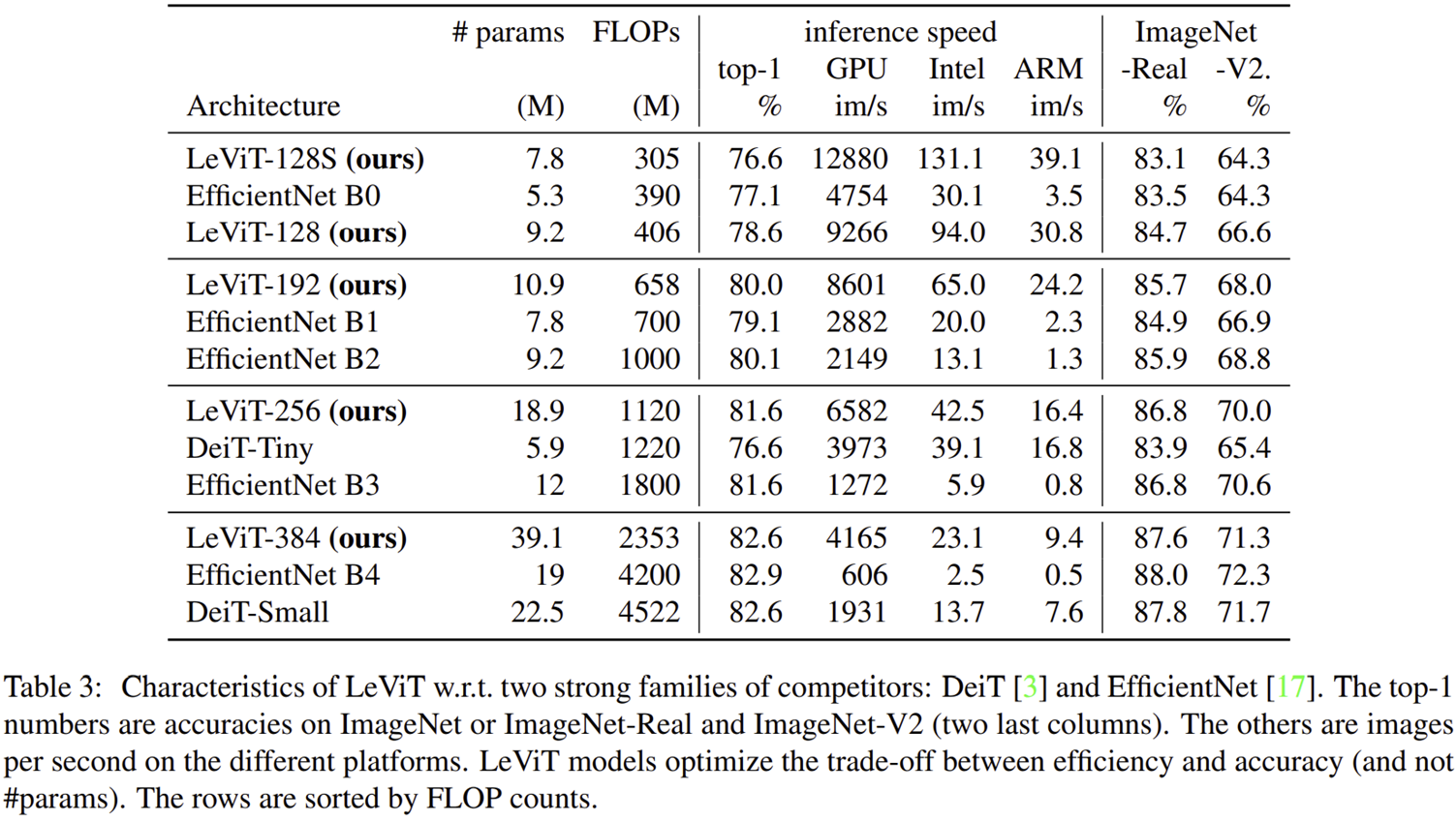
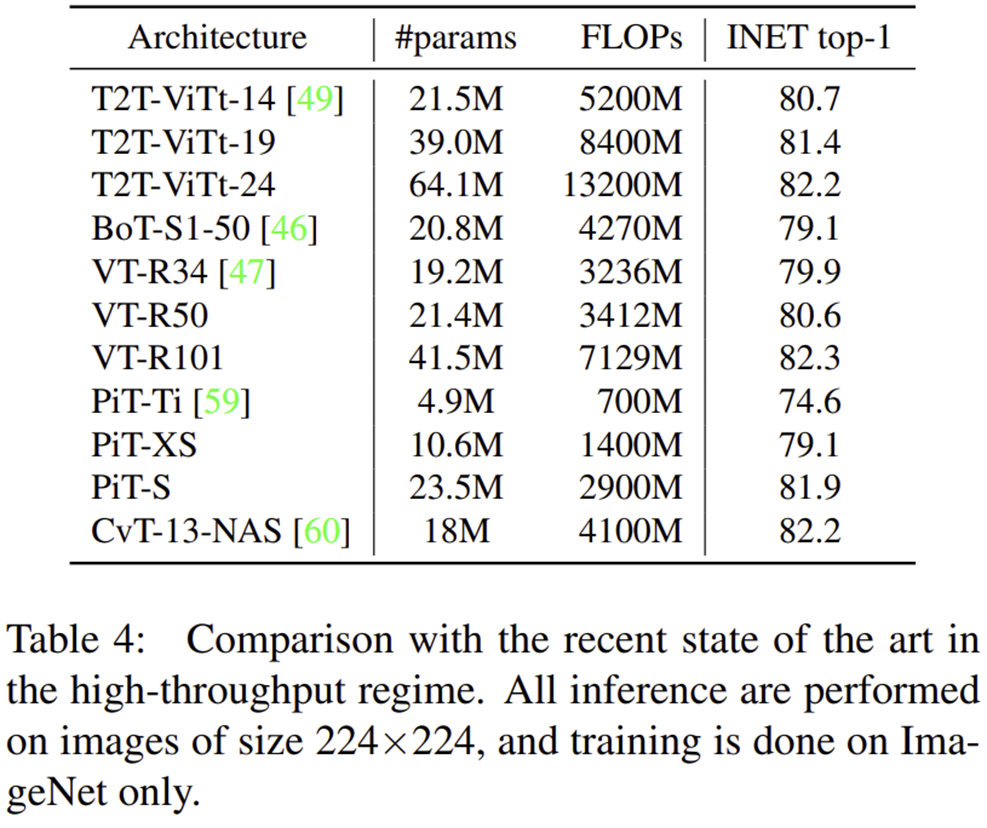
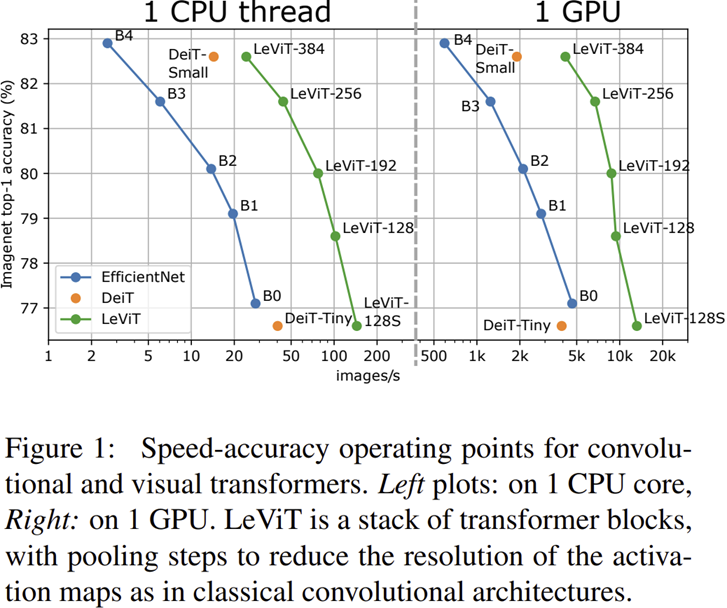
2) Ablation Study