
안녕하세요. 지난 포스팅의 [IC2D] Self-Training with Noisy Student Improves Imagenet Classification (CVPR2020)에서는 외부 unlabeled dataset을 이용하여 기존 Knowledge Distillation에서 Knowledge Expansion으로 바꾸어 ImageNet-1K에서 높은 성능 향상을 달성한 Noisy Student에 대해서 알아보았습니다. 오늘은 전이학습 (Transfer Learning)을 보다 효율적으로 다양한 task들에 적용할 수 있는 Big Transfer (BiT)에 대해서 알아보도록 하겠습니다. 결과적으로 구글의 실험 능력이 정말 넘사벽이라는 것을 느끼게 해준 논문인 거 같습니다.
Big Transfer (BiT): General Visual Representation Learning
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a targe
arxiv.org
Background
지금까지 보았던 다양한 모델들은 영상 인식 (분류, 분할, 탐지 등)에서 인간보다 매우 높은 성능을 달성하고 있습니다. 하지만, 실질적으로 영상 분류를 위해 학습된 모델을 의미론적 분할 또는 객체 탐지 등에 사용하기 위해서는 추가적으로 많은 데이터셋에 학습하는 전이학습이 필수입니다.
본 논문에서는 이러한 전이학습의 효율성을 강조하며 단 한번의 전이학습으로도 다른 task들에서 높은 성능을 달성할 수 있는 Big Transfer (BiT)를 제안합니다. 이를 통해, 다양한 downstream task들에서 state-of-the-art 성능을 달성하였으며 이를 위한 새로운 데이터셋에 대한 전이학습 과정은 짧고 하이퍼파라미터 튜닝 역시 단순한 방식을 수행하는 것을 제안합니다.
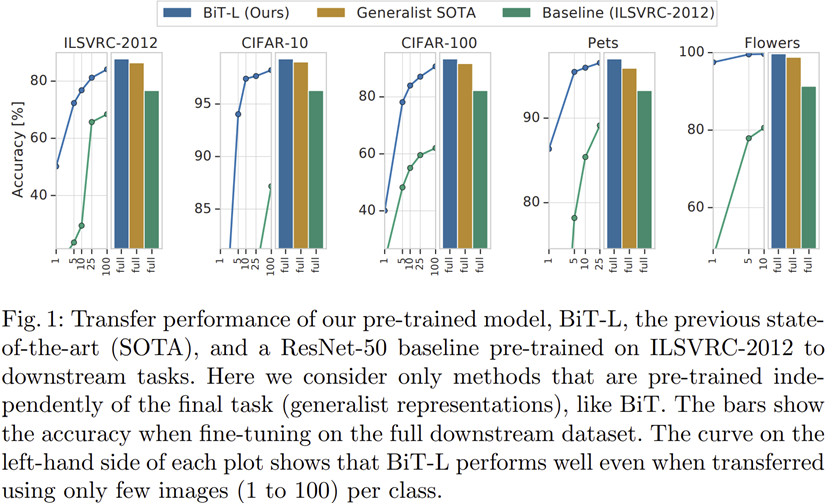
그림 1은 BiT가 실제로 기존 baseline 모델보다 훨씬 높은 성능을 가지는 것을 보여주고 있습니다. 해당 결과에 대한 분석은 실험 파트에서 더 자세히 진행하도록 하겠습니다.
Big Transfer (BiT)
BiT의 방법론 자체는 매우 단순하기 때문에 쉽게 이해할 수 있습니다. 본 논문에서는 pre-training 과정인 Upstream Pre-training과 fine-tuning 과정은 Downstream task로 나누어 설명하고 있습니다.
1). Upstream Pre-training
첫번째로 모델을 학습하는 데 있어 가장 중요한 것은 scale이라고 할 수 있습니다. 여기서 scale은 데이터셋 크기, 모델 규모를 모두 언급하는 것 입니다. 예를 들어, 데이터셋의 규모는 크지만 모델 규모가 작다면 데이터셋이 가지고 있는 복잡한 특성을 작은 모델은 잡을 수 없을 것 입니다. 반대로 모델의 규모는 크지만 데이터셋의 규모가 작다면 과적합이 발생하여 향후 새로운 데이터셋에 대한 올바른 예측을 하지 못할 가능성이 높습니다. 이를 위해, 본 논문에서는 데이터셋의 규모에 따른 3가지 변형 모델인 BiT-S (ImageNet-1K), BiT-M (ImageNet-21K), BiT-L (JFT-300M)들을 제안합니다. 각 데이터셋에 대한 설명은 이후 실험 파트에서 더 자세히 설명하도록 하겠습니다만 ImageNet-1K이 가장 규모가 작고 JFT-300M이 가장 규모가 큰 데이터셋이라고 보시면 될 거 같습니다.
두번째는 저자들이 실험해보았을 때 배치 정규화 (Batch Normalization)은 두 가지 문제가 있음을 언급합니다. 첫번째는 Multi-GPU 학습 시 발생하는 문제점입니다. 일반적으로 저희는 큰 규모의 데이터셋과 모델을 학습할 때는 대부분 Multi GPU를 활용합니다. 이때, 각 GPU에 입력되는 데이터의 규모가 작다면 배치 정규화의 특성 상 해당 데이터셋에 대한 정확한 분포 추정이 어려울 뿐만 아니라 서로 다른 GPU들간의 동기화 비용이 발생합니다. 두번째 문제는 전이학습 시 배치 정규화는 통계량 (평균 및 분산)을 재추정해야하기 때문에 오히려 성능 하락이 발생한다고 합니다. 이러한 문제점들로 인해 저자들은 배치 크기에 독립적인 정규화 방식인 Layer Normalization과 Instance Normalization을 고려할 수 밖에 없습니다. 따라서, 두 방식의 적절한 혼합 정규화 방식인 Group Normalization (GN)을 통해 이 문제를 해결합니다.
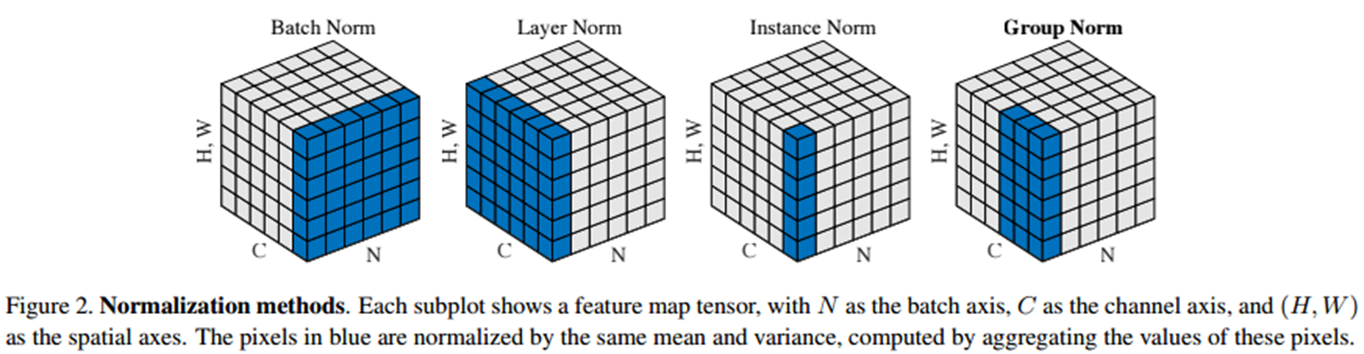
본 논문에서는 단순히 GN만을 이용하는 게 아니라 Weight Standardization (WS)도 함께 활용합니다. 이를 통해, 가중치가 특정 데이터셋에 편향되어 학습되는 문제를 해결할 수 있다고 합니다.
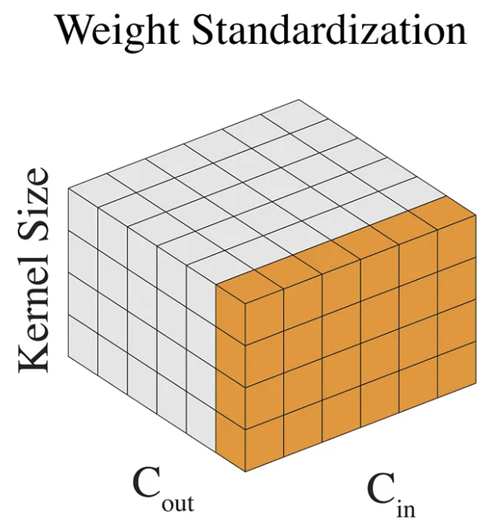
2). Transfer to Downstream Tasks
이전 단계에서 사전학습이 끝났다면 이제 새로운 task과 데이터셋에 대한 전이학습을 진행해야합니다. 본 논문에서는 전이학습 단계에서 발생하는 비용들을 최소화하는 것을 목표로하고 있습니다. 이를 위해, 모든 하이퍼파라미터들을 새로 튜닝하는 것이 아닌 몇몇 중요한 하이퍼파라미터들만 튜닝하는 규칙인 BiT-HyperRule을 제시합니다. 이는 Training Schedule Length (Epoch을 의미하는 거 같긴 한데 정확한 의미는 모르겠네요 ㅠㅠ), 데이터셋의 해상도, MixUp 정규화 사용 유무로 3개의 하이퍼파라미터에 대한 튜닝을 의미합니다.
다음으로 전처리 및 데이터 증강에는 resize, crop, horizontal flip을 사용하였습니다. 다만, 객체 탐지 및 의미론적 분할과 같이 픽셀 공간에서 레이블의 정보가 훼손되는 경우에는 crop과 flip을 적용하지 않습니다.
마지막은 개인적으로 정말 의외이지만 흔히 저희가 많이 사용하는 weight decay와 같은 정규화 트릭을 사용하지 않습니다. 즉, weight_decay = 0이라는 뜻이죠.
Experiment Results
1). Upstream Training Settings
- Dataset: ImageNet-1K (BiT-S), ImageNet-21K (BiT-M), JFT-300M (BiT-L)
- ImageNet-1K: 1.28 million training images & 50K validation images with 1,000 classes
- ImageNet-21K: 14.2 million training images with 21K classes
- JFT-300M: 300 million training images with with 1.26 labels per image on average. The labels are organized into a hierarchy of 18,291 classes
- Resolution: 224 $\times$ 224
- Backbone: PreAct ResNet-152$\times$4 with Group Normalization and Weight Standardization
- Data Augmentation: Resizing & Random Cropping & Horizontal Flipping
- Optimization: Stochastic Gradient Descent
- momentum: 0.9
- weight decay: 0.0001
- initial learning rate: 0.03
- learning rate warm-up for 5,000 optimization steps & Multiply learning rate by batch size / 256 (Linear Scale Batch Size)
- Batch Size: 4,096
- Epochs
- BiT-S & BiT-M: 90 epochs (learning rate decay by a factor of 10 in 30, 60, 80 epoch)
- BiT-L: 40 epochs (learning rate decay by a factor of 10 in 10, 23, 30, 37 epoch)
- Cloud TPU V3-512
- Note that -S/-M/-L suffix does not mean "model scale", it means "dataset scale".
2). Downstream Tasks Training Settings
- Dataset: ImageNet-1K, CIFAR-10/100, Oxford-IIIT Pet, Oxford Flowers-102, Visual Task Adaptation Benchmark (VTAB), ObjectNet, COCO-2017
- Fine-tune BiT on the official training split
- Report results on the official test split if publicly available
- If test split does not be available, use val split
- Resolution
- Resize $160 \times 160$ & Random Crop $128 \times 128$
- Resize $448 \times 448$ & Random Crop $384 \times 384$
- Backbone: ImageNet-1K/ImageNet-21K/JFT-300M Pretrained PreAct ResNet-152$\times$4 with Group Normalization and Weight Standardization
- Data Augmentation
- Classification: Resizing & Random Cropping & Horizontal Flipping
- Object Detection: Resizing
- Optimization: Stochastic Gradient Descent
- momentum: 0.9
- weight decay: 0 (Does not use weight decay)
- initial learning rate: 0.003
- Batch Size: 512
- Epochs (Schedule Length)
- Small Dataset ($\le$ 20K): 500 steps
- Medium Dataset ($\le$ 500K): 10K steps
- Small Dataset ($\ge$ 500K): 20K steps
- MixUp regularization with $\alpha = 0.1$
3). Results
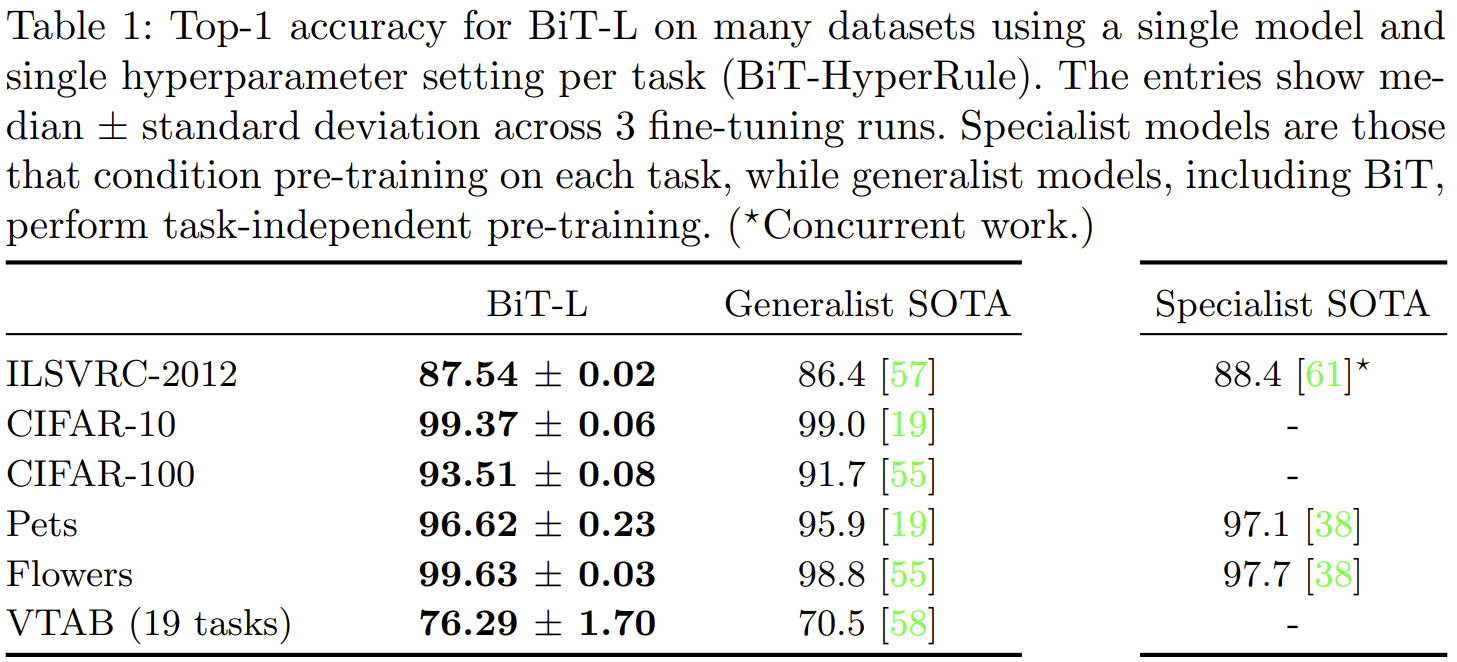
- 표 1은 BiT를 이용한 첫번째 실험 결과입니다. 여기서 Generalist는 task-independent한 모델, Specialist는 task-dependent한 모델을 의미합니다. 참고로 여기서 [61] 논문이 지난 포스팅에서 언급한 Noisy Student입니다.
- 결과적으로는 Specialist SOTA의 성능이 훨씬 높습니다 (약 1% 차이). 하지만, Specialist 모델의 문제는 새로운 task에 대해서는 완전히 새롭게 재학습을 해야한다는 문제점이 있습니다. 이러한 관점에서 Generalist 모델들이 범용성이 큰 것을 볼 수 있습니다.
- 다만 표 1에서는 BiT-L을 사용한 결과로 JFT-300M에 대해 학습한 모델을 비교하고 있기 때문에 공개되지 않아 사용하지 못하는 측면에서는 실질적으로 비교하기 어렵습니다.
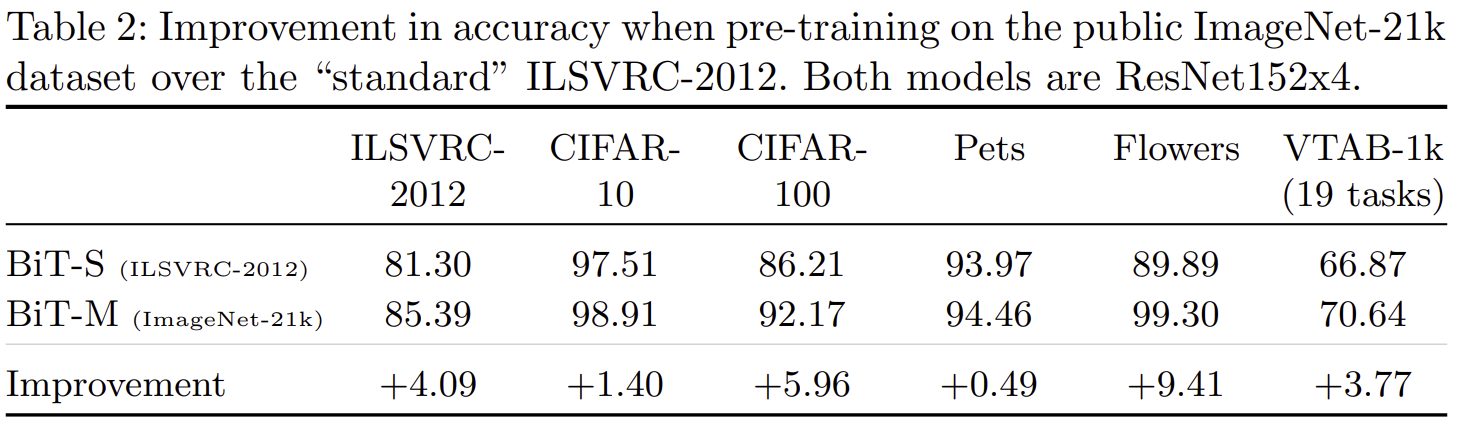
- 표 2는 BiT-M와 BiT-S를 이용한 실험결과로 이 결과를 통해 데이터셋의 scale의 중요도를 알 수 있습니다.
- Oxford Flowers-102에서 BiT-M와 BiT-S은 9.41%의 높은 차이를 보이고 있으며 Oxford-IIIT Pet에서는 0.49%로 가장 낮은 차이를 보여주고 있습니다.
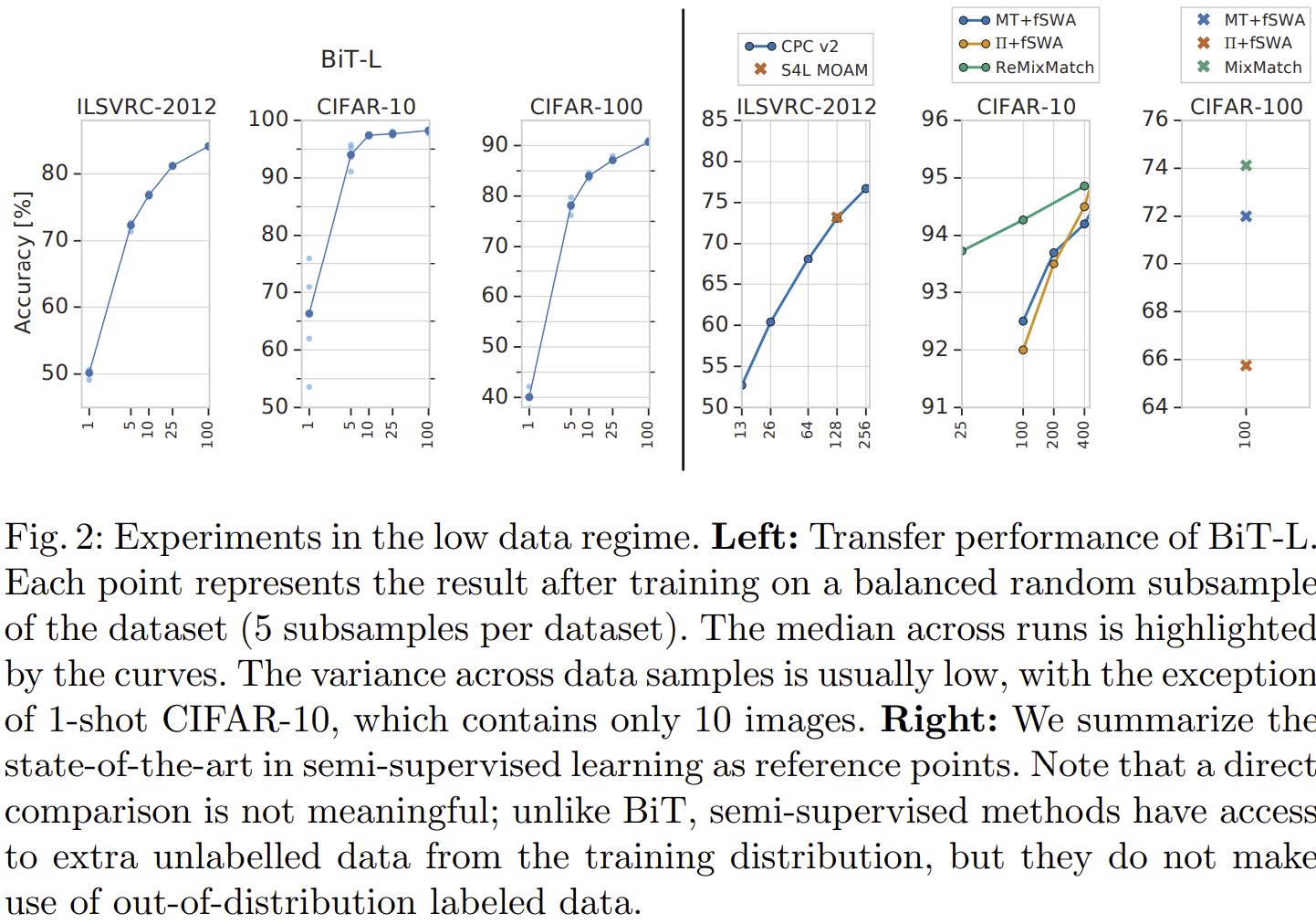
- 그림 2는 downstream task의 레이블별 데이터셋 개수를 극단적으로 줄였을 때 ($[1, 5, 10, 25, 100]$) 성능을 보여주고 있습니다.
- 좌측 3개 그래프는 BiT-L의 실험 결과이고 우측 3개는 Few-Shot learnig 기반 모델의 실험 결과로 Few-Shot learning 모델들보다도 훨씬 높은 성능을 보여주고 있습니다.
- 또한 데이터의 개수가 점점 많아질수록 BiT-L은 빠르게 성능이 향상되고 있습니다. 하지만, Few-Shot learning 모델을 선형적으로 천천히 증가하고 있음을 볼 수 있습니다.
- 이를 통해, BiT는 데이터가 없는 극단적인 상황에서도 성능을 보장한다는 것을 볼 수 있습니다. 다만, BiT-M이나 BiT-S에 대한 결과는 없어 아쉽네요.
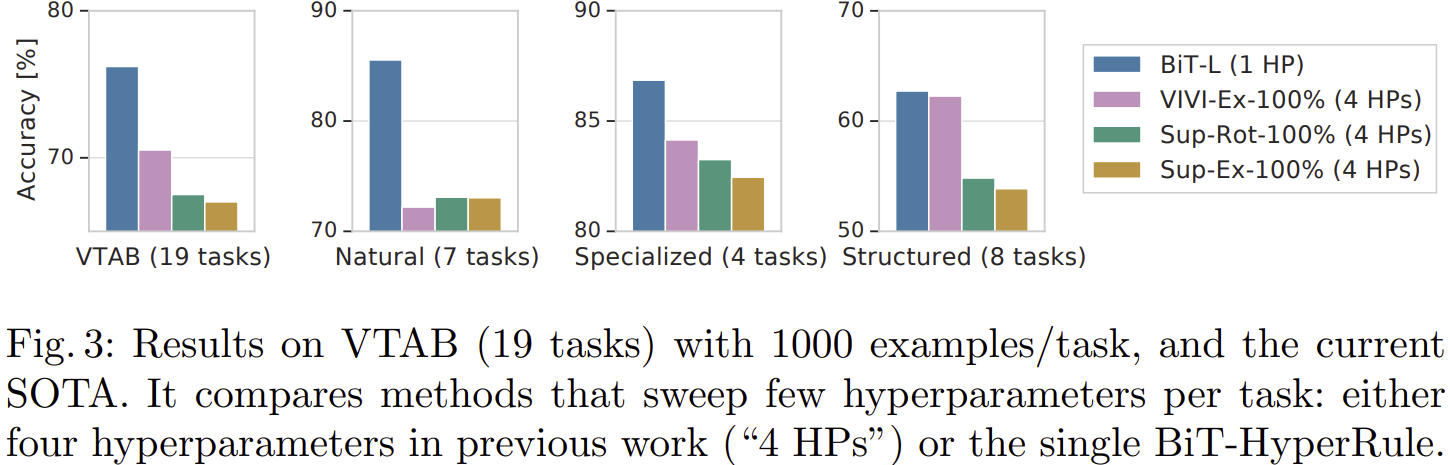
- 그림 3은 VTAB에서 성능을 보여주고 있습니다. VTAB는 natural, specialized, structure tasks로 구성되어 있습니다.
- 결과적으로 모든 task들에 대해서 기존 SOTA 모델들보다 훨씬 높은 성능을 달성하고 있습니다.
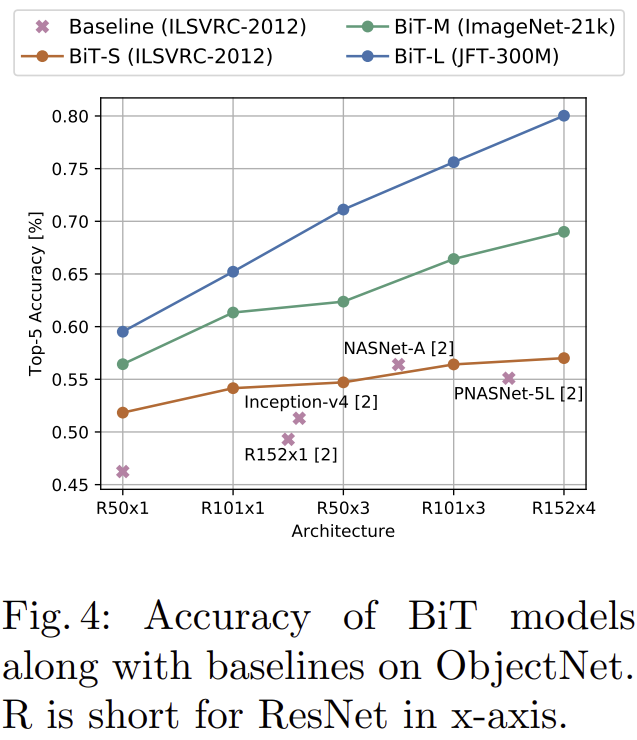
- 그림 4는 ObjectNet이라는 더 실제 상황의 영상들로 구성된 데이터셋에 대한 실험 결과입니다.
- 기존의 ResNet, InceptionNet, NASNet, PNASNet들보다 BiT-S, BiT-M, BiT-L의 성능이 훨씬 높은 것을 볼 수 있습니다.

- 표 3은 COCO-2017 데이터셋을 이용한 객체 탐지 실험 결과입니다.
- RetinaNet을 backbone 모델로 하였으며 BiT가 모든 경우에 대해 높은 성능을 달성하였습니다.
Analysis
결과적으로 다양한 downstream tasks에서 BiT는 높은 성능을 보여주고 있습니다. 이번에는 BiT에 대한 자세한 분석을 보도록 하겠습니다.
1). Scaling Models and Datasets
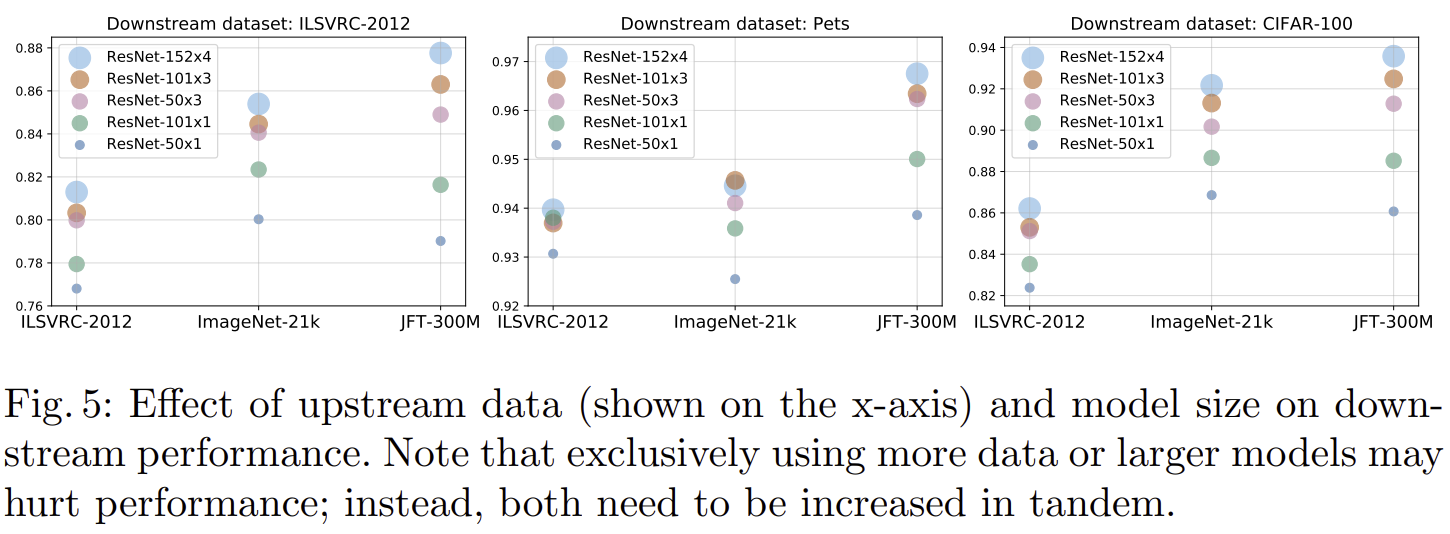
- 그림 5는 데이터셋 규모와 BiT의 규모에 따른 실험결과를 보여주고 있습니다. $x$-축은 pre-training에서 사용한 데이터셋, $y$-축은 성능, 원의 크기는 모델의 규모를 의미합니다.
- 전체적으로 경향성은 사전학습을 수행할 때 데이터셋의 규모에 따라 성능이 크게 향상된다는 점 입니다.
- 다만, 중간 그림에서 ImageNet-1K를 이용하여 사전학습하는 경우 모델의 규모에 따른 성능 향상 정도가 많이 떨어지는 것을 볼 수 있습니다.
- 이러한 결과는 큰 데이터셋을 이용하여 큰 모델에 사전학습하면 downstream tasks들에서 높은 성능을 달성한다는 것을 의미합니다. 이는 표 2에서도 확인할 수 있는 결과입니다.
2). Optimization on Large Datasets
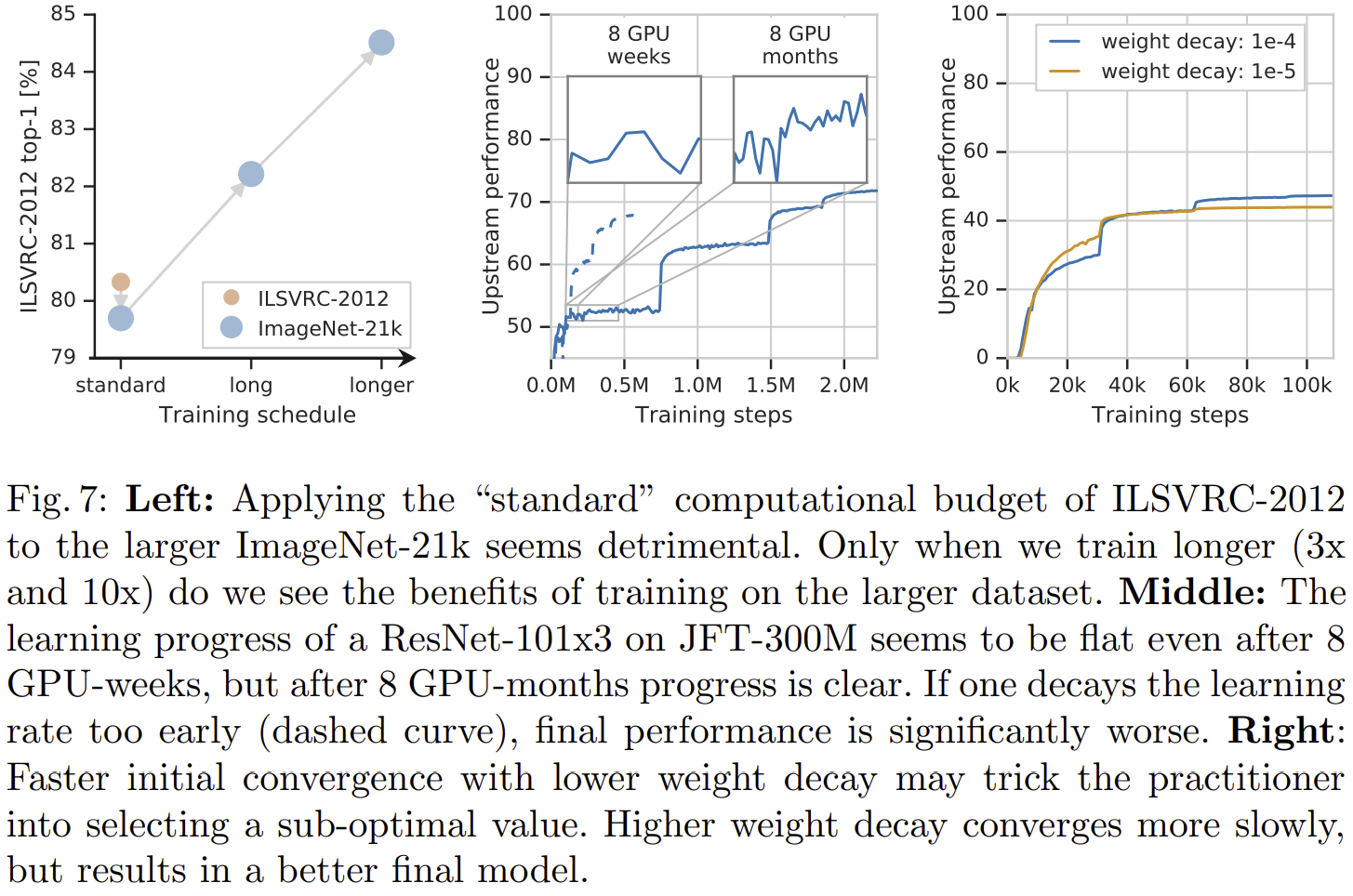
- 그림 7의 좌측 그림은 데이터셋의 규모가 커질수록 더욱 많은 학습 시간을 투자해야한다는 것을 보여주고 있습니다. ImageNet-21K 데이터셋을 학습 시 ImageNet-1K와 동일한 시간으로 학습 시 오히려 성능이 하락되지만 점점 많은 시간을 학습하면 성능이 약 6% 향상되는 것을 볼 수 있죠.
- 그림 7의 중앙 그림은 학습 시 성능이 주 (Week) 단위에서는 노이지하게 보이지만 개월 단위로 보면 점점 향상되고 있는 것을 볼 수 있습니다.
- 그림 7의 우측 그림은 weight decay의 크기에 따른 성능 변화를 보여주고 있습니다. weight decay를 작게 주면 초기 성능이 빠르게 향상되지만 향후에는 모델의 성능이 더 이상 향상되지 않습니다. 반대로 weight decay를 크게 주면 초기 성능 향상은 느리지만 향후 모델 성능이 훨씬 높은 것을 볼 수 있습니다.
3). Large Batches, Group Normalization, Weight Standardization
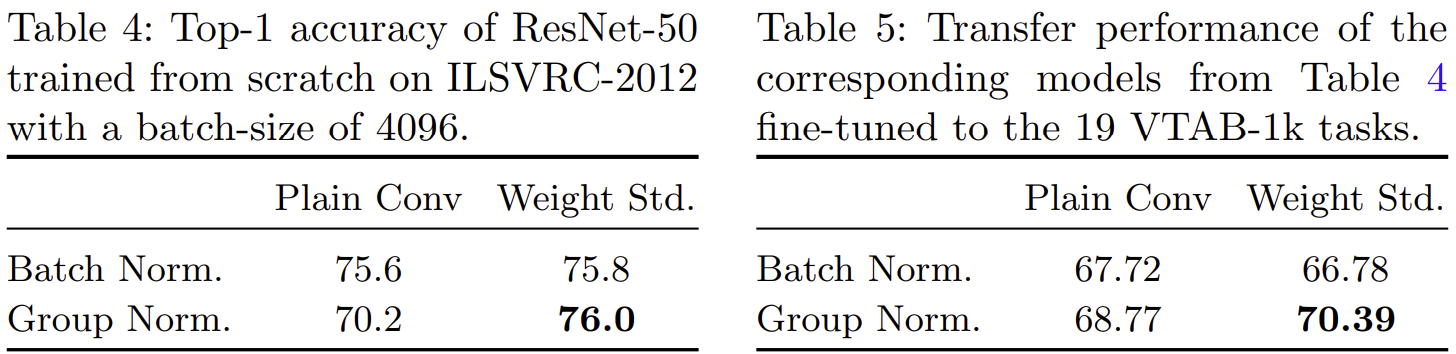
- 표 5와 표 6은 BN 및 GN 그리고 Plain Convolution 및 WS의 성능 향상 관계를 보여주고 있습니다.
- 처음 BN에 대한 문제점 중 하나는 배치 크기가 작을수록 데이터셋에 대한 전체적인 통계량을 추정하기 어렵기 때문에 성능이 떨어진다는 점을 언급하였습니다. 하지만, 그렇다고 해서 GN만 쓰게 되면 성능이 크게 떨어지게 되었죠. 이때, WS를 함께 적용하여 BN보다 성능 향상 정도가 훨씬 높은 것을 볼 수 있습니다. 심지어 표 5에서는 BN + WS를 적용 시 성능이 아예 감소하지만, GN + WS에서는 성능이 향상됩니다.