
안녕하세요. 지난 포스팅의 [IC2D] Improving Convolution Networks with Self-Calibrated Convolutions (CVPR2020)에서는 기존 어텐션 모듈과는 다르게 전혀 연산량을 늘리지 않는 Self-Calibrated Convolution에 대해서 설명드렸습니다. 오늘은 외부 unlabeled 데이터셋을 활용하여 ImageNet에서 성능 향상을 이룬 Noisy Student Training에 대해서 소개시켜드리도록 하겠습니다.
Background
저희가 지금까지 보았던 다양한 모델들의 필수 과정은 ImageNet과 같은 대규모 데이터셋에서 full supervision을 필요로 합니다. 본 논문에서는 레이블이 존재하지 않는 외부 데이터셋도 함께 사용하여 ImageNet에서 뿐만 아니라 오염된 데이터셋에서도 큰 성능 향상을 달성하였습니다.
이는 기본적으로 Self-Training 방식으로 이루어집니다. 현재 label이 존재하지 않는 이미지에 대해서도 학습을 진행하기 위해서는 해당 이미지에 대한 가짜 label (pseudo label)을 만들어 학습하는 것을 의미합니다. 이를 위해, 본 논문에서는 Knowledge Distillation에서도 활용한 Teacher & Student 모델을 구성하여 학습을 진행하였습니다. 다만, 기존의 Knowledge Distillation과는 다르게 Student 모델의 Teacher 모델보다 동일한 규모이거나 더 큰 규모로 설계했다는 점입니다.
Noisy Student Training
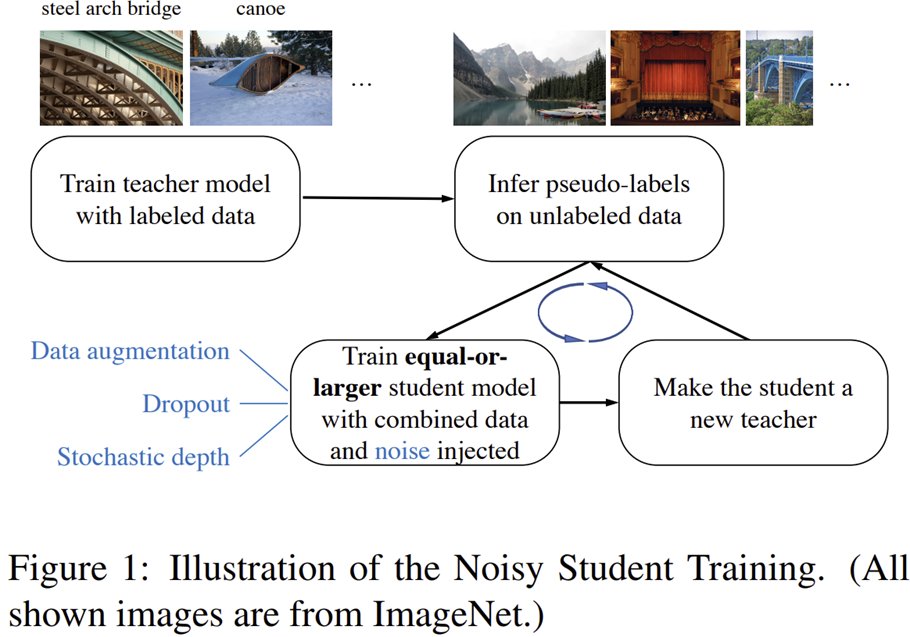
그림1은 Noisty Student Training의 전체적인 과정을 보여주고 있습니다. 보시면 일단, Teacher 모델을 labeled dataset으로 학습하게 됩니다. 여기서 labeled dataset은 ImageNet이 되겠죠? 다음으로 학습이 종료된 Teacher 모델을 이용해서 unlabeled dataset에 대한 psuedo-label을 만들어내게 됩니다. 여기서, unlabeled dataset에는 ImageNet에 존재하지 않는 label도 존재합니다. 현재 저희는 unlabeled dataset에 대해서도 pseudo-label을 만들었기 때문에 이제 Student 모델을 이용해서 supervision 학습이 가능합니다. 이때, Student 모델은 이전에도 설명드렸다 싶이 Teacher 모델보다 동일하거나 더 큰 규모의 모델로 구성합니다. Student 모델을 학습할 때는 노이즈들 (데이터 노이즈 및 모델 노이즈)를 주입하면서 학습을 진행합니다. Student 모델도 학습이 종료되면 학습된 Student 모델을 다시 Teacher 모델로 정의하고 unlabeled dataset의 pseudo-label을 다시 만들어 새로운 Student 모델을 만들어 학습을 진행합니다. 본 논문에서는 이러한 과정을 Iterative Learning으로 이야기하고 있습니다.
해당 알고리즘의 전체적인 컨셉은 "청출어람"입니다. 기존의 Student 모델이 Teacher 모델보다 더 뛰어난 성능을 보이면서 Student 모델이 다시 Teacher 모델로 바뀌면서 후속 Student 모델의 지식이 점점 "확장"되고 있는 듯한 느낌을 받죠. 따라서, 본 논문에서는 기존의 Knowledge Distillation과는 다르게 Student 모델의 지식이 줄어들지 않고 발전한다는 의미에서 Knowledge Expansion이 수행된다고 합니다.
아래는 전체적인 알고리즘입니다.

1단계에서는 Teacher Model이 cross-entropy 손실을 이용해서 labeled dataset을 학습하게 되죠.
2단계에서는 1단계에서 학습된 Teacher 모델을 이용해서 unlabeled dataset에 대한 pseudo-label을 만들게 됩니다.
3단계에서는 2단계에서 얻은 unlabeled dataset에 대한 pseudo-label과 labeled dataset을 이용해서 학습하게 됩니다. 이때, 중요한 점은 학습 시 영상 및 모델에 노이즈를 적용한다는 점이죠.
4단계에서는 학습된 Student 모델을 Teacher 모델로 바꾼 뒤 2단계를 수행합니다. 이 과정의 반복횟수는 하이퍼파라미터가 됩니다.
Noisy Student Training에서는 2가지 종류의 노이즈를 적용합니다. 각각 input noise와 model noise입니다.
먼저, input noise는 데이터 증강 (data augmentation)으로 이미지의 다양한 변환에 강건한 모델을 만들 수 있도록 도와줍니다. 이를 위해 RandAug를 이용해서 학습합니다. RandAug는 기존의 강화학습 기반 AutoAug가 학습 속도가 느리다는 점을 지적하며 성능은 어느정도 포기하고 빠르게 학습할 수 있는 데이터 증강 방법입니다. 다만, 데이터 증강을 위한 연산의 개수와 각 데이터 증강의 최대 변환 파라미터는 labeled dataset에서 미리 학습을 통해 얻어야합니다.
다음으로 model noise는 저희가 흔히 알고 있는 DropOut과 Stochastic Depth를 적용합니다. 이는 향후 Student 모델을 다시 Teacher 모델로 바꾸고 pseudo-label을 얻을 때 앙상블 효과를 얻을 수 있습니다.
여기서, 효율적인 Noisy Student Training을 위한 몇 가지 트릭이 존재합니다. 먼저, Data Filtering과 Balacing입니다. 저희가 아무리 잘 학습된 Student 모델을 이용해서 pseudo-label을 얻는다고 가정해도 몇몇 pseudo-label들은 신뢰도가 매우 낮아 오히려 학습에 방해가 될 수 있습니다. 따라서, 신뢰도가 낮은 pseudo-label에 대응되는 이미지를 학습에 제외시키는 것을 Data Filtering이라고 합니다. 하지만, ImageNet의 경우 평가 데이터셋에 존재하는 각 클래스의 비율이 어느정도 유사합니다. Data Filtering으로 인한 클래스 불균형 문제를 해결하기 위해 unlabeled dataset의 pseudo-label 중 높은 신뢰도를 가지는 이미지를 복사하였습니다. 마지막으로 pseudo-label를 구성할 때 softmax 결과값 자체를 사용하는 soft pseudo-label과 최대확률값에 대응하는 클래스를 원핫벡터 인코딩으로 바꾸어 사용하는 hard pseudo-label를 생각해볼 수 있습니다. 본 논문에서는 두 가지 방식을 모두 사용해보았을 때 soft pseudo-label가 더 높은 성능을 얻었다고 합니다.
Experiment
1). Experimet Settings
- 본 논문에서 labeled dataset은 ImageNet-1K, 그리고 unlabeled dataset은 JFT dataset을 이용하였습니다. JFT dataset은 300M개의 영상으로 구성된 데이터셋으로 아쉽게도 구글의 비공개 데이터셋이기 때문에 사용할 수 없습니다. 그리고 Data Filtering을 위해 confidence > 0.3이 되는 pseudo-label만 선택해서 사용하게 됩니다. 그리고 balancing을 통해 각 클래스가 130K로 다 맞추어줍니다.
- 본 논문에서 사용한 모델은 EfficientNet-B7에서 모델 구조를 더 복잡하게 구성한 EfficientNet-L2를 사용하였습니다.
- 학습 시 배치사이즈를 512, 1024, 2048로 바꾸어가보면서 했을 때 성능 차이가 없었기 때문에 가장 큰 2048로 셋팅했다고 합니다. 그리고 350 에폭으로 학습을 수행하였으며 초기 학습률은 0.128에서 시작하여 0.97씩 2.4 에폭마다 줄였다고 합니다. 그리고 labeled dataset의 배치 사이즈보다 unlabeled dataset의 배치 사이즈를 14배로 셋팅했다고 합니다.
2). ImageNet-1K Classification Results
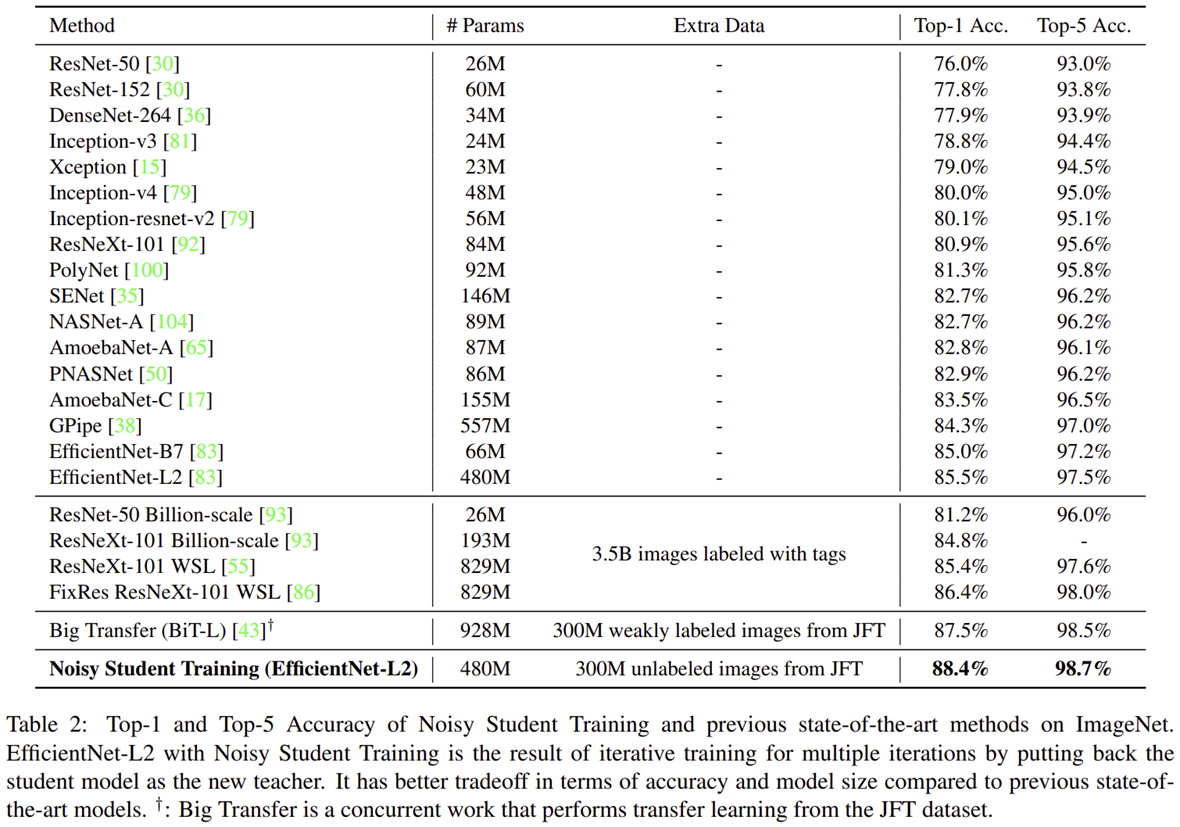
결과적으로 동일하게 외부 데이터셋들을 이용하는 모델들보다 높은 성능을 얻게 됩니다. 특히, 동일하게 JFT 데이터셋을 사용하지만 weakly labeled 조건에서 학습한 BiT 보다 0.9% 향상되었을 뿐만 아니라 파라미터도 절반 가까히 감소한 것을 볼 수 있습니다.
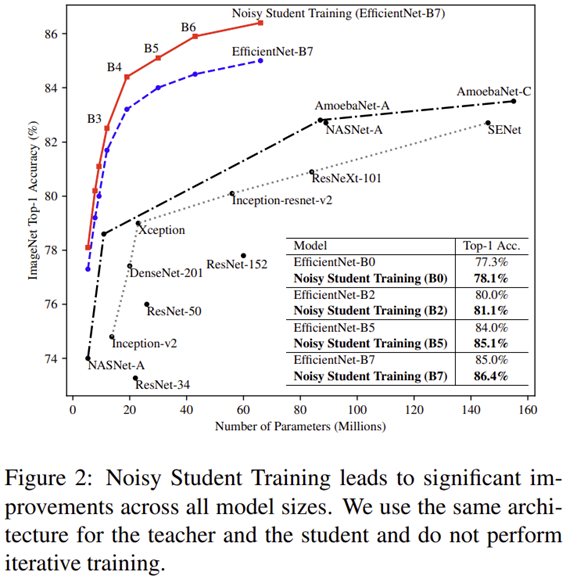
그림2는 Noisy Student Training이 Vanilla EfficientNet에 비해서 얼마나 성능이 향상되었는 지 볼 수 있습니다. 파라미터가 증가할 수록 성능 향상 차이가 점점 커지게 됩니다 (0.8% ~ 1.4%).
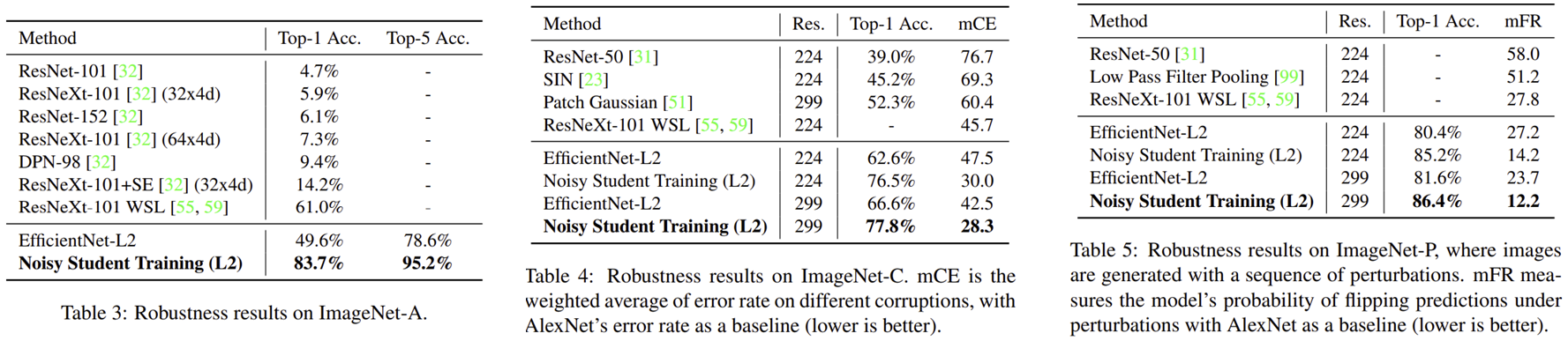
다음으로 Robustness 테스트까지 수행합니다. ImageNet-A은 기존의 ImageNet보다 더욱 어려운 영상들로 구성되어 단순한 모델들에서는 성능이 매우 낮지만 Noisy Student Training에서는 유일하게 80%이상의 성능을 보여주고 있습니다. 뿐만 아니라, 15개의 오염 데이터셋으로 구성된 ImageNet-C와 변동 데이터셋으로 구성된 ImageNet-P에서도 모두 높은 성능 향상을 보여주고 있습니다.

그림 3은 ImageNet-A, ImageNet-C, ImageNet-P에서 Noisy Student Training (검은색)과 EfficientNet (빨간색)의 예측 결과를 보여주고 있습니다. 본 논문에서 제시하는 모든 영상에서 강건하게 예측하고 있음을 볼 수 있습니다.
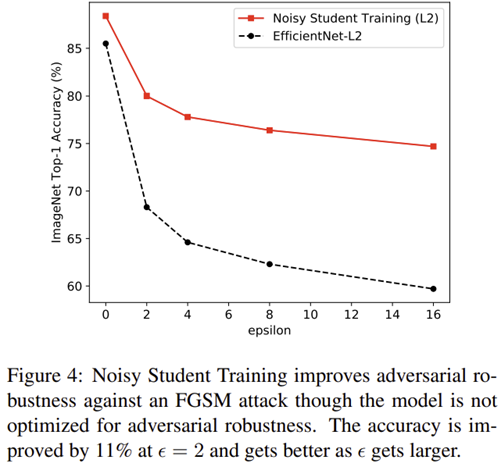
그림 4는 적대적 공격 (Adversarial Attack) 중 하나인 FGSM에 공격당한 영상에 대한 모델의 강건도를 측정합니다. epsilon이 클수록 강한 공격을 수행하기 때문에 성능이 크게 하락합니다. EfficientNet과 비교했을 때 모든 경우에서 강건하게 예측하고 있음을 볼 수 있습니다.
3). Ablation Study
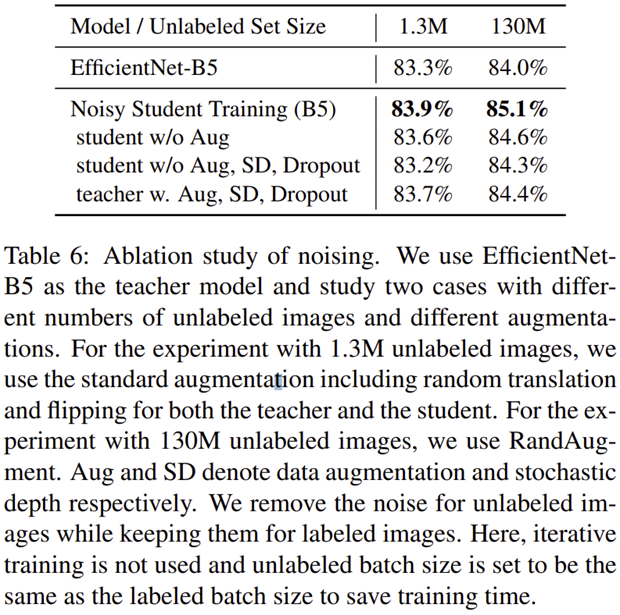
표 6에서는 Noisy Student Training의 노이즈의 중요성을 보여주고 있습니다. 모든 노이즈를 적용했을 때 가장 높은 성능을 얻게 됩니다. 다만, Teacher 모델에 노이즈를 적용하면 성능이 약간 하락하는 데 이는 pseudo-label을 구성할 때 오히려 방해가 되서 그러지 않나 생각이 듭니다.
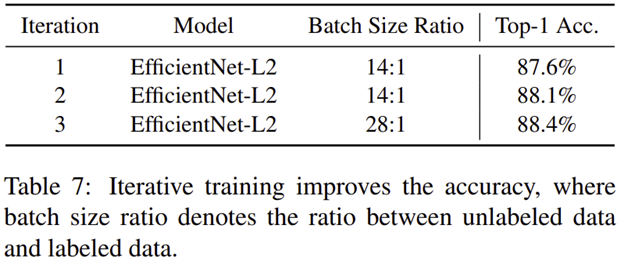
마지막으로 표7에서는 Iterative Learning의 횟수에 따른 성능 향상 정도를 보여주고 있습니다. 당연히 여러번 반복하면서 학습할수록 성능이 향상되는 것을 볼 수 있습니다. 다만, 그만큼 학습시간이 배로 늘어나기 때문에 이는 유의해서 결정해야합니다.