
안녕하세요. 지난 포스팅의 [Transformer] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (ICCV2021)에서는 기존의 ViT아 가지고 있는 고질적인 한계점인 "큰 해상도 영상에 대한 과도한 어텐션 연산량"을 해결하기 위한 W-MSA와 SW-MSA를 제안한 Swin Transformer에 대해서 알아보았습니다. 지금까지 저희는 Computer Vision 분야에 Transformer를 적용한 두 가지 방법인 ViT와 Swin Transformer에 대해서 보았죠? 하지만, 지난 포스팅에서 비교할 때 DeiT라는 Transformer 기반 모델이 있었던 것을 기억하시나요? 오늘은 DeiT 모델에 대해서 집중적으로 알아보도록 하겠습니다.
Background
지금까지 제안된 CNN 기반 모델들은 모두 대규모 데이터셋인 ImageNet의 등장으로 큰 성능 향상을 달성하였습니다. 이러한, CNN의 발전은 현재까지도 이어지고 있죠. 하지만, Vision Transformer (ViT)의 등장은 이러한 기조를 바꾸기 시작하였습니다. Transformer는 기본적으로 1D Sequence 데이터의 전체적인 정보 (Global Context)를 수집하여 학습을 진행합니다. 따라서, ViT 역시 입력 영상의 전체 패치 간 관계성을 분석하기 때문에 데이터셋의 Global Context를 추출하는 데 좋은 방법이 될 수 있다고들 하죠.
하지만, 문제점이 있습니다. Computer Vision에서 기본적으로 가지고 있는 가정은 입력 영상에서 특징 픽셀의 주변 픽셀과 관계성이 많다는 Locality 그리고 의미있는 2D Structure가 존재한다는 가정 (Inducive Bias)가 Transformer에서는 포함될 수 없습니다. 물론, ViT에 따르면 ImageNet보다 더 큰 JFT-300M 데이터셋에 먼저 학습한 뒤 ImageNet에 fine-tuning 하면 inductive bias를 얻을 수 있다고 하지만 이는 학습하는 데도 굉장히 비효율적입니다. 그렇다면, 실제로 저희가 실험하고자 하는 ImageNet-1K 데이터셋만을 이용해서 학습을 했을 때 CNN과 ViT보다 높은 성능을 얻게 만들 수 없을까요? 오늘 설명드릴 DeiT가 바로 이러한 문제를 해결하기 위해 제안된 모델입니다.
DeiT는 기본적으로 ViT와 동일한 구조로 되어있기 때문에 ViT만 이해하고 있다면 전혀 어렵지 않습니다. 즉, DeiT는 ImageNet-1K에 학습하기 위한 효율적인 "학습 전략"을 제안하고 있습니다. 핵심은 지식 증류 (Knowledge Distillation)과 증류 토큰 (Distillation Token)입니다.
본 논문에서는 ViT에 대한 Overview에 대해서 설명하지만 이번 포스팅에서는 반복설명하지는 않겠습니다.
Distillation Through Attention
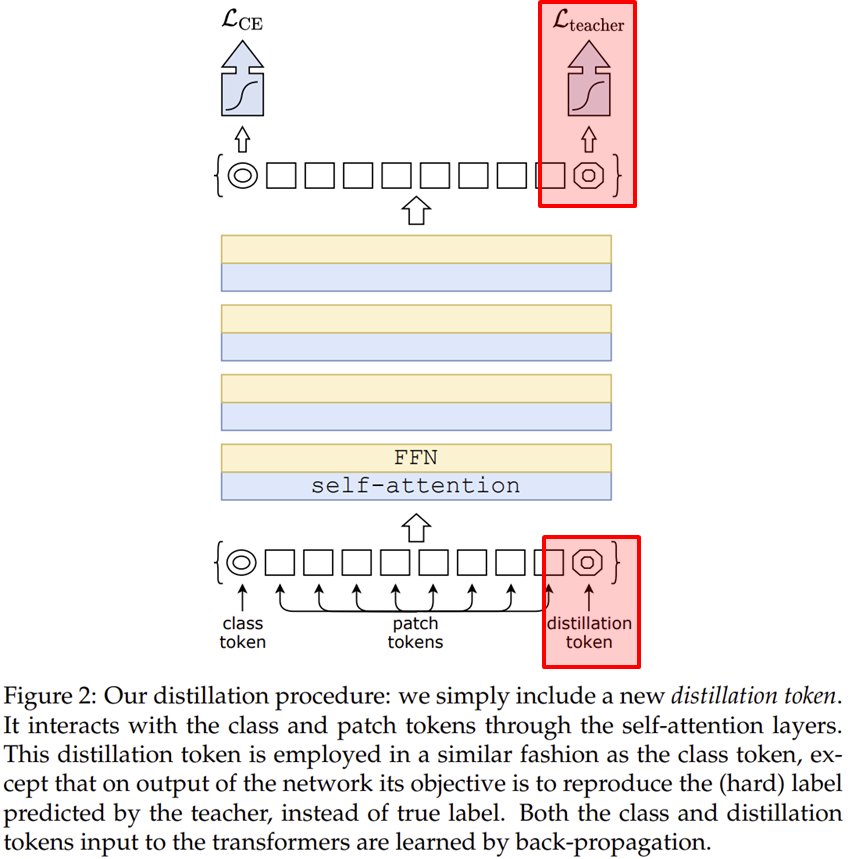
그림 2는 DeiT의 전체 구조입니다. 제가 빨간색으로 표시한 부분이 기존 ViT와의 차별성이라고 이해하시면 될 거 같습니다. 이를 위해서는 지식 증류에 대한 내용을 빠르게 이해하고 넘어가도록 하겠습니다.
1). Knowledge Distillation
일단 지식 증류는 2015년부터 제안된 학습 방법론 중 하나로 새로운 개념이 아닙니다. 기본적인 아이디어는 2개의 모델을 정의합니다. 각각 Teacher Model 그리고 Student Model이라고 하죠. 일반적으로 Teacher Model은 Student Model보다 더 복잡하고 좋은 성능을 가지는 모델로 결정됩니다. 각 모델의 이름에서도 느껴지다 싶이 Teacher Model이 가지고 있는 복잡한 지식을 Student Model에게 넘겨주는 방식이 지식 증류입니다. 이를 통해, 단순한 Student Model임에도 불구하고 학습이 끝나고 나면 Teacher Model과 거의 유사한 성능을 가질 수 있기 때문에 효율적인 학습 방법이라고 할 수 있죠.
이를 위해, 일반적으로 사용되는 방식은 두 모델의 예측 결과 사이에서 Kullback-Leibler Divergence라고 하는 확률분포 사이의 거리를 측정하는 방법을 이용해 줄여주게 됩니다. DeiT에서는 Teacher Model로 CNN 모델을 선택하였습니다. 왜 하필 CNN을 사용했을까요? 아무래도 ViT 계열의 가장 큰 문제점인 Inductive Bias가 부족한 문제를 해결하기 위해서일 겁니다. 즉, Student Model인 DeiT는 Teacher Model인 CNN으로부터 지식 증류를 통해 Inductive Bias를 얻어 Global Context와 함께 입력 영상을 보다 상세하게 이해하고 추론할 수 있는 것이죠. 따라서, 지식 증류를 적용했을 때 전체 손실함수는 다음과 같이 정의됩니다.
$$\mathcal{L}_{\text{global}} = (1 - \lambda) \mathcal{L}_{CE} (\psi (Z_{s}), y) + \lambda \tau^{2} \text{KD} \left( \psi (Z_{s} / \tau), \psi (Z_{t} / \tau) \right)$$
여기서, $Z_{s}$와 $Z_{t}$는 각각 Student Model과 Teacher Model의 출력값을 의미합니다. 그리고 $\tau$와 $\lambda$는 각각 지식 증류를 위한 temperture parameter 그리고 CE 손실함수와 KL 손실함수 사이의 균형 parameter이죠. 마지막으로, $y$와 $\psi$는 각각 ground truth와 softmax 함수를 의미합니다. 이와 같이 출력의 확률 분포를 기반으로 지식 증류를 수행하는 방식을 Soft Distillation이라고 합니다. 본 논문에서는 Hard Distillation을 사용하죠.
$$\mathcal{L}_{\text{global}}^{\text{hardDistill}} = \frac{1}{2} \mathcal{L}_{CE} (\psi (Z_{s}), y) + \frac{1}{2} \mathcal{L}_{CE} (\psi(Z_{s}), y_{t})$$
기존의 Soft Distillation과 다른 점은 KL 손실함수를 CE 손실함수로 변경하고 예측값의 확률 분포를 이용하는 것이 아닌 $y_{t}$의 최종 예측값을 ground truth로 삼아 학습한다는 점이죠. 이와 같이 했을 때 기존 Soft Distillation이 가지고 있던 두 개의 하이퍼파라미터인 $\tau$와 $\lambda$에 자유로워집니다. 또한, 본 논문에 따르면 실제 학습할 때는 $y_{t}$에 $\epsilon = 0.1$로 두고 label smoothing을 적용하였다고 하네요.
2). Distillation Token
본 논문에서는 지식 증류와 함께 증류 토큰이라는 것도 함께 추가하였습니다. 기존의 ViT에서 클래스 토큰을 추가하여 Self-Attention 과정에서 다른 패치들 사이의 관계성을 이해하여 해당 토큰에 정보를 모아 마지막 계층에서 MLP를 통과해 최종 예측을 수행하였던 것을 기억하실 겁니다. 이 과정에서 클래스 토큰에서는 학습 데이터셋에 대한 사전 지식을 학습하게 되죠. 이와 마찬가지로 증류 토큰도 동일한 과정을 거치게 됩니다. 다만, 마지막 계층에서 ground truth와 비교하는 것이 아닌 Teacher Model과의 지식 증류를 위해 사용되죠. 즉, $Z_{S}$를 추출하기 위해 사용됩니다. 사실, 클래스 토큰과 증류 토큰 비슷해보이지만 논문에 따르면 학습 시 서로 다른 벡터로 수렴했다고 하네요. 실제로 두 벡터 사이의 cosine similarity가 0.06으로 유사도가 많이 떨어지는 것을 볼 수 있습니다.
DeiT Variants
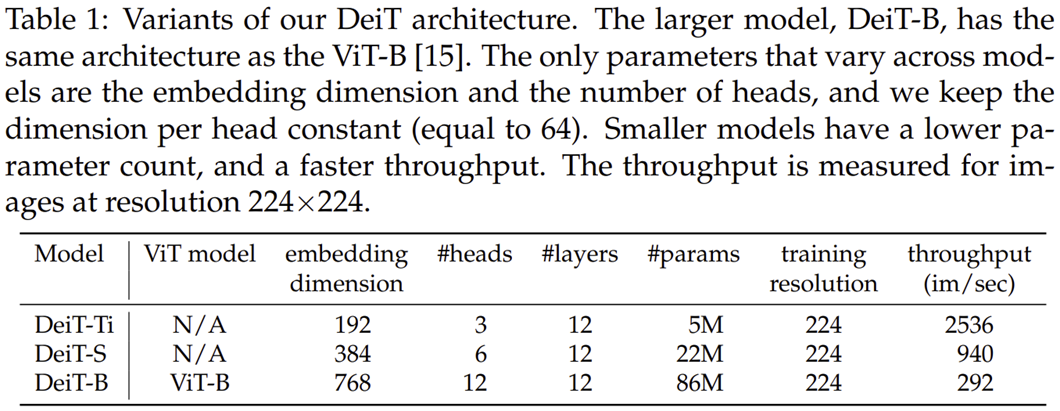
본 논문에서는 총 3개의 파라미터 개수에 따른 DeiT 모델의 변형 구조들을 제시합니다. 이는 표1에 나와있죠.
Experiment Results
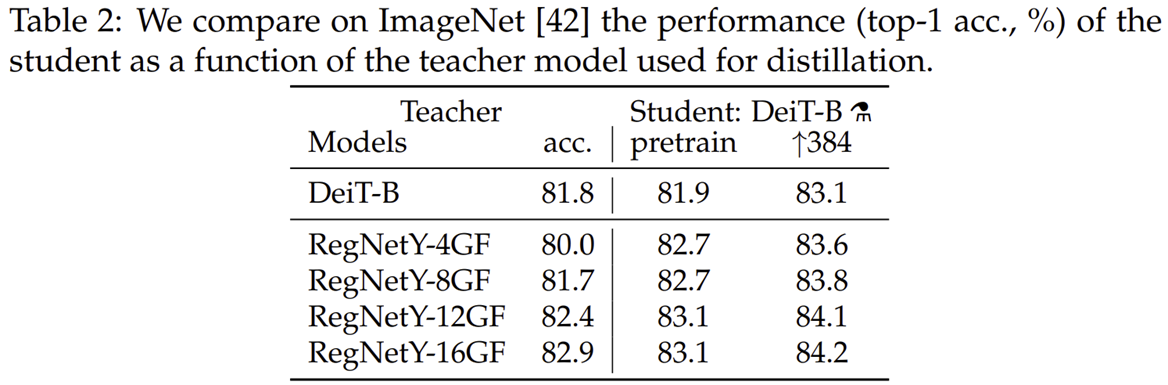
표2는 Teacher Model을 선택하기 위해 RegNetY 모델의 변형 구조들을 ImageNet-1K에 학습했을 때 성능을 보여주고 있습니다. 결과적으로 RegNetY-16GF가 가장 좋은 성능을 내어 해당 모델을 Teacher Model로 채택하였습니다.
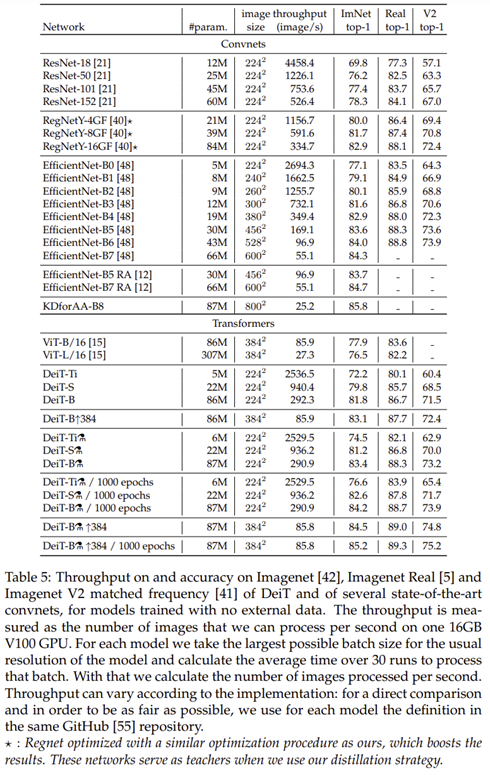
표5는 전체 실험 결과를 보여주고 있습니다.
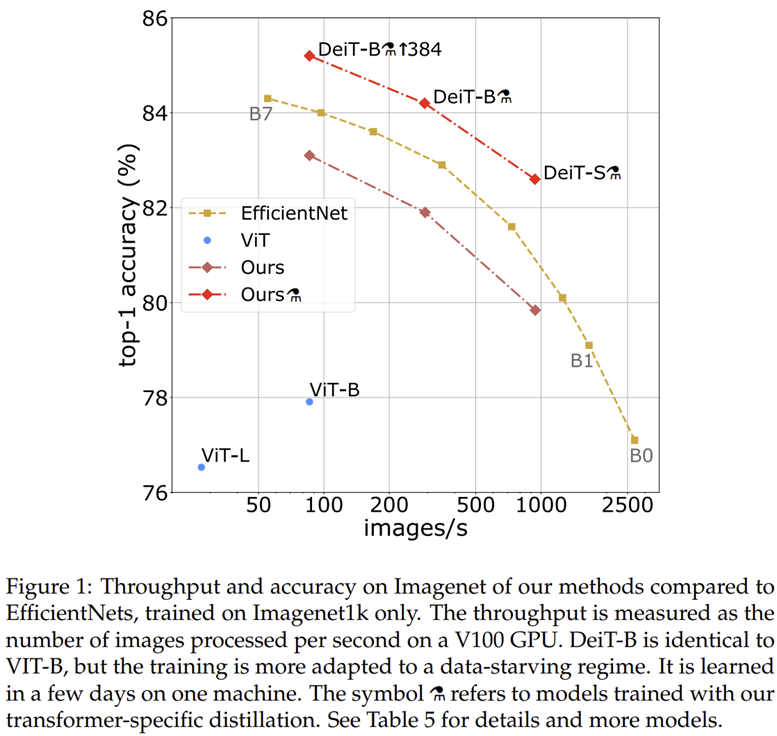
그림 1은 EfficientNet, ViT, DeiT 모델 사이의 성능을 비교하고 있습니다. 실제로 기존의 CNN 모델이나 ViT에 비해 훨씬 높은 성능을 보이고 있습니다. 여기서 중요한 점은 오직 ImageNet-1K에만 학습했음에도 Transformer가 성능이 높다는 점 입니다.