
안녕하세요. 지난 포스팅의 [IC2D] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning (AAAI2017)에서는 Inception 모델과 ResNet의 결합을 통한 새로운 SOTA 성능의 모델인 Inception-ResNet 에 대해서 알아보았습니다. 오늘은 이러한 구조를 더욱 일반화한 PolyNet에 대해서 소개해드리겠습니다.
Background
지금까지 저희가 보았던 영상 분류 모델들을 보면 대부분 ResNet 기반의 모델들이였습니다. 다른 변형구조로는 InceptionNet과 ResNet 구조를 결합한 Inception-ResNet과 cardinality를 강조한 multi-path 기반의 ResNext를 보았습니다. 특히, 기존의 ResNet 변형 모델들을 보면 깊이 (depth)와 너비 (width)를 모델의 중요한 파라미터로 보았습니다. 실제로 좋은 성능을 보이기는 했죠. 하지만, 너무 깊은 모델을 diminishing problem과 학습이 어려워진다는 문제점이 있습니다. 또한, 너무 넓은 모델은 채널의 개수가 $k$배만큼 늘어날 때 $k^{2}$배 만큼 연산량이 증가하기 때문에 성능은 좋더라도 비효율적이라는 문제점이 있습니다. 그렇다면 다른 방법이 있을까요?
본 논문에서는 Structural Diversity라는 새로운 개념을 제안합니다. 쉽게 말해, 기존의 ResNet이나 Inception-ResNet에서 사용하는 residual path는 매우 단순하기 때문에 모델의 강력한 표현력을 오히려 제한하므로 이를 복잡하게 만들어보자는 것이죠. 이러한 개념을 통해 나온 모듈이 PolyInception Module입니다. 이 모듈을 활용하여 기존의 Inception-ResNet을 바꾸어 Very Deep PolyNet이라는 새로운 모델을 제안하게 됩니다.
PolyInception and PolyNet
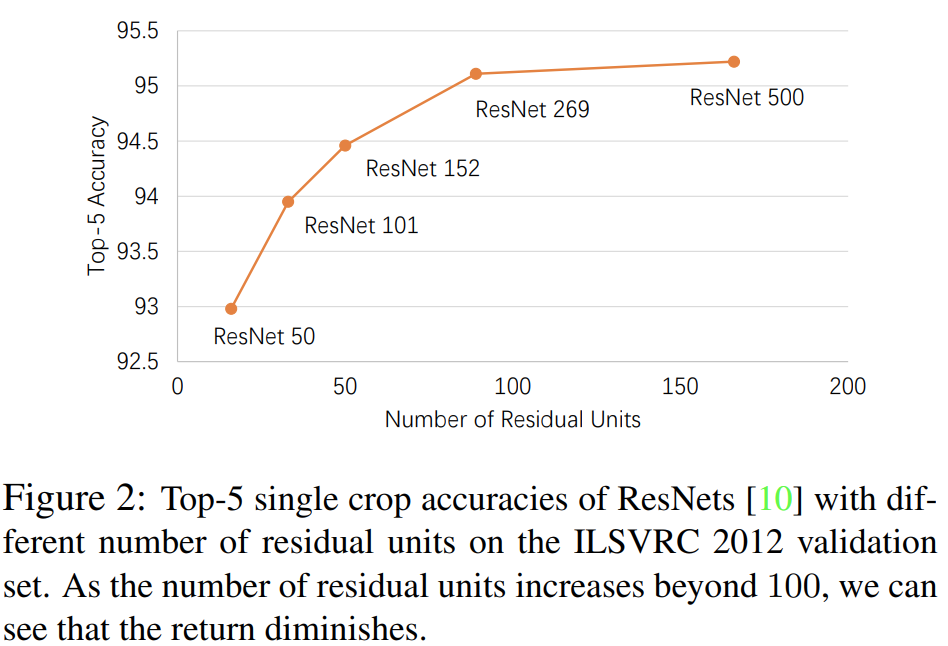
그림2는 깊이의 효율성에 대해서 언급하고 있습니다. ResNet-50 ~ ResNet-269까지는 residual unit의 개수가 많아질수록 그만큼 성능 향상 폭이 두드리지게 나타납니다. 하지만, ResNet-269에서 ResNet-500으로 약 80개 정도에 residual unit을 늘렸음에도 성능은 약 0.1% (4.8% $\rightarrow$ 4.9%)밖에 오르지 않습니다. 즉, 어느정도 깊이가 되면 깊이에 대한 성능 향상은 기대하기 어렵다는 것이죠. 그림은 없지만 이러한 현상은 너비에 대해서도 동일한 결과가 나온다고 합니다.
그렇다면, 깊이도 안되고 너비도 안되면 성능을 올릴 수 있는 다른 방법이 무엇이 있을까요? 이것이 본 논문에서 언급하는 Structural Diversity입니다. 줄여서 diversity는 다음과 같은 방법으로 늘릴 수 있습니다.
1). 서로 다른 독립된 모델 간의 앙상블
2). ResNet에 내재된 암묵적 앙상블 (implicit ensemble)
3). Inception-ResNet-v2와 같이 multi-path 구조
여기서 2)번은 2016년에 나온 논문에서 얻을 수 있는 결과로 ResNet이 skip connection 구조는 사실 앙상블의 효과를 주기 때문에 성능향상을 얻을 수 있다는 결론에서 기인합니다. 본 논문에서는 Inception-ResNet-v2를 채용하여 diversity를 늘리고자 합니다.
1) PolyInception Modules
자, 이제 본격적으로 PolyInception Module에 대해서 설명하기 전에 ResNet 블록을 수식화 해보도록 하겠습니다. 저희는 많이 보았기 때문에 ResNet 블록이 identity path와 residual path로 이루어진다는 것을 알 수 있습니다.
$$(I + F) \mathbf{x} = \mathbf{x} + F(\mathbf{x})$$
여기서, $I$가 identity path, $F$가 residual block을 의미합니다.
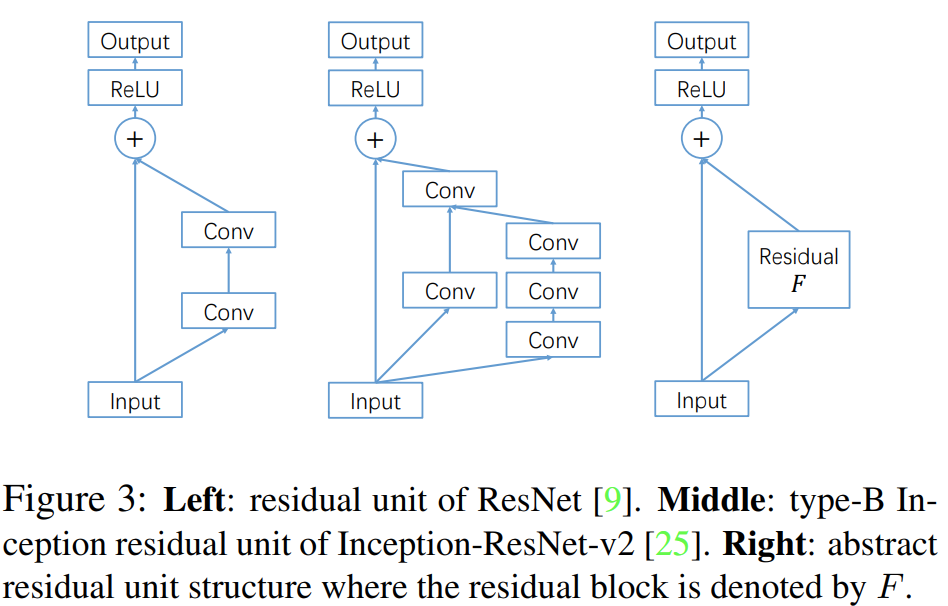
그림3은 ResNet의 블록 (왼쪽), Inception-ResNet의 블록 (가운데)를 도식화한 블록 다이어그램입니다. ResNet이든 Inception-ResNet이든 근본은 Residual Block인 $F$를 어떻게 정의하느냐에 따라서 달라진다는 것 입니다. 하지만, 두 모델 모두 residual path에서는 적으면 2개, 많으면 4개의 합성곱 계층으로밖에 이루어있지 않습니다. 이는 모델의 강력한 표현력을 오히려 제한할 수 도 있습니다. 따라서, 본 논문에서는 이 residual path 부분을 더 개선하고 싶은 것이죠.
저희는 처음봤던 residual block을 수식으로 추상화하였습니다. 그렇다면 저희가 $F$를 합성함수의 형태로 쓸 수 있지 않을까요? 예를 들어 다음과 같습니다.
$$(I + F + F^{2})(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + F^{2}(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + F(F(\mathbf{x}))$$
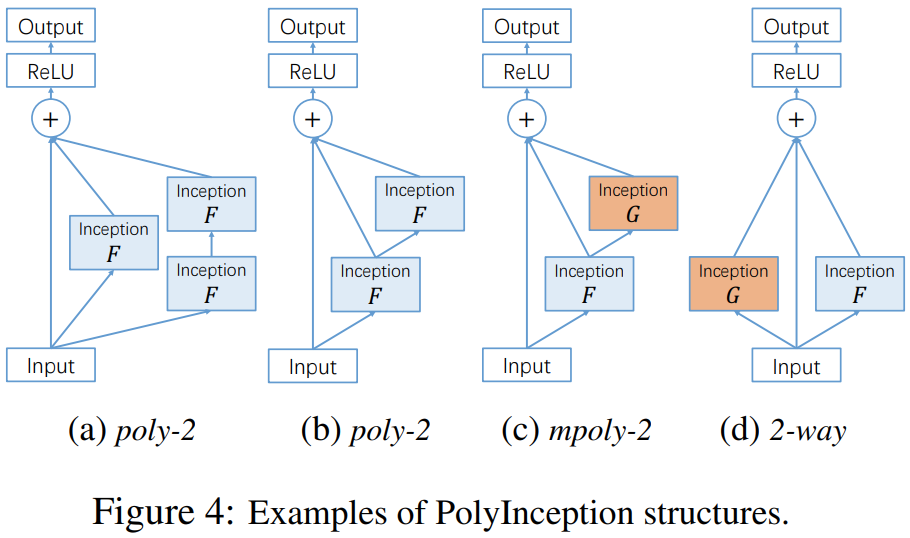
즉, 기존의 residual block을 합성함수의 형태로 사용함으로써 residual path의 복잡성을 증가시키고 이는 diversity를 늘리게 되는 결과를 얻는 것이죠. 그림4의 (a)는 위 수식을 도식화한 블록 다이어그램입니다. 3개의 path로 구성되어 있으며 각각 identity path $I$, 1차 residual block path $F$, 마지막으로 2차 residual block path $F^{2}$가 됩니다. 이와 같이 다항식 (polynomial)의 합성으로 구성하기 때문에 PolyInception이 되는 것이죠.
그림4 (b)는 (a)의 cascaded form으로 수식적으로는 완전히 동일하지만 하나의 블록을 삭제하여 파라미터의 개수를 $\frac{2}{3}$으로 줄인 형태입니다. 그림4 (c)는 (b)와 유사하지만 서로 다른 파라미터를 가지는 블록 $G$를 도입하는 것이죠. 따라서, 다음과 같이 쓸 수 있습니다.
$$(I + F + GF)(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + GF(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + G(F(\mathbf{x}))$$
이를 mixed polynomial block (mpoly-$k$)이라고 부르겠습니다. 마지막으로 그림4 (d)는 다항식 $F$와 $G$가 아예 시작부터 다른 path로 구성되어있기 때문에 다음과 같이 쓸 수 있습니다.
$$(I + F + G)(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + G(\mathbf{x})$$
이를 multi-way polynomial block ($n$-way)이라고 부르겠습니다. 위 구조들은 모두 최대 2차식을 가지기 때문에 $k = 2$가 되죠. 물론 $k=3$인 경우에도 다음과 같이 쓸 수 있습니다.
1). poly-3
$$(I + F + F^{2} + F^{3})(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + F(F(\mathbf{x})) + F(F(F(\mathbf{x})))$$
2). mpoly-3
$$(I + F + GF + HGF)(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + G(F(\mathbf{x})) + H(G(F(\mathbf{x})))$$
3). 3-way
$$(I + F + G + H)(\mathbf{x}) = \mathbf{x} + F(\mathbf{x}) + G(\mathbf{x}) + H(\mathbf{x})$$
2). An Ablation Study
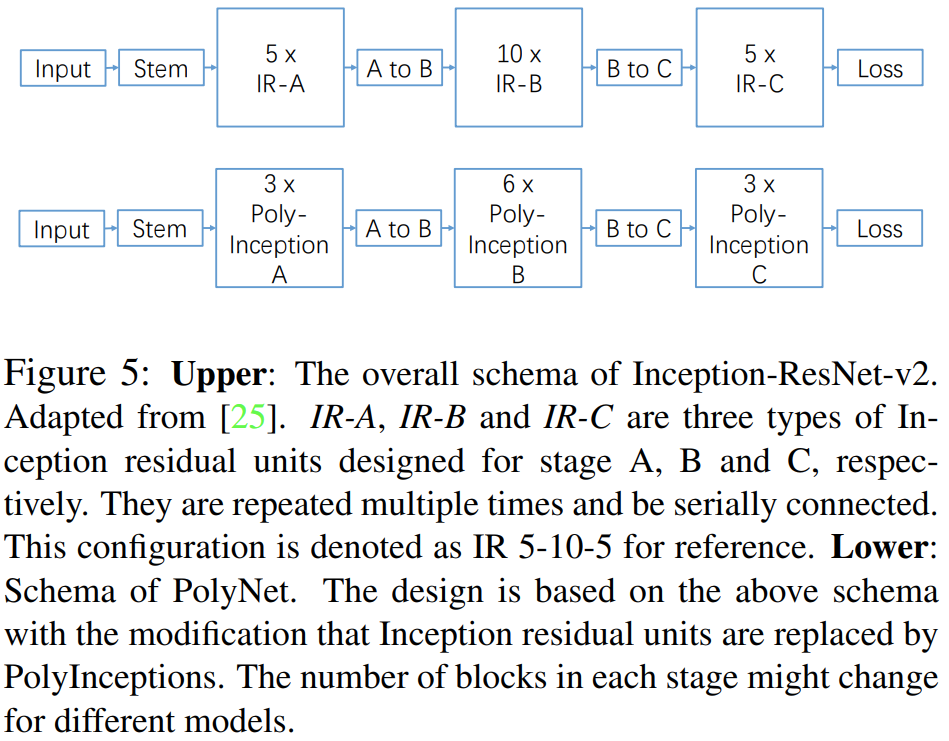
다음으로 본 논문에서는 Inception-ResNet-v2 (IR-v2)를 PolyInception Module로 바꾸기 위한 실험을 진행합니다. 그림5의 위쪽 그림은 IR-v2에서 각 스테이지 (A, B, C)를 5번, 10번, 5번 적용한 모델로 이를 표현하기 위해 IR-5-10-5라고 쓰기로 합니다. 해당 모델은 굉장히 큰 편입니다. 이를 빠르게 실험하기 위해 IR-3-6-3으로 변형한 뒤 ablation study를 수행합니다.
이 과정에서 각 스테이지를 2-way, 3-way, poly-2, poly-3, mpoly-2, mpoly-3로 교체하여 실험을 진행합니다. 예를 들어서, A 스테이지의 모든 모듈을 2-way로 변경하고 다른 스테이지는 건들지 않는 것이죠. 이 모델을 2-way A라고 부르겠습니다.
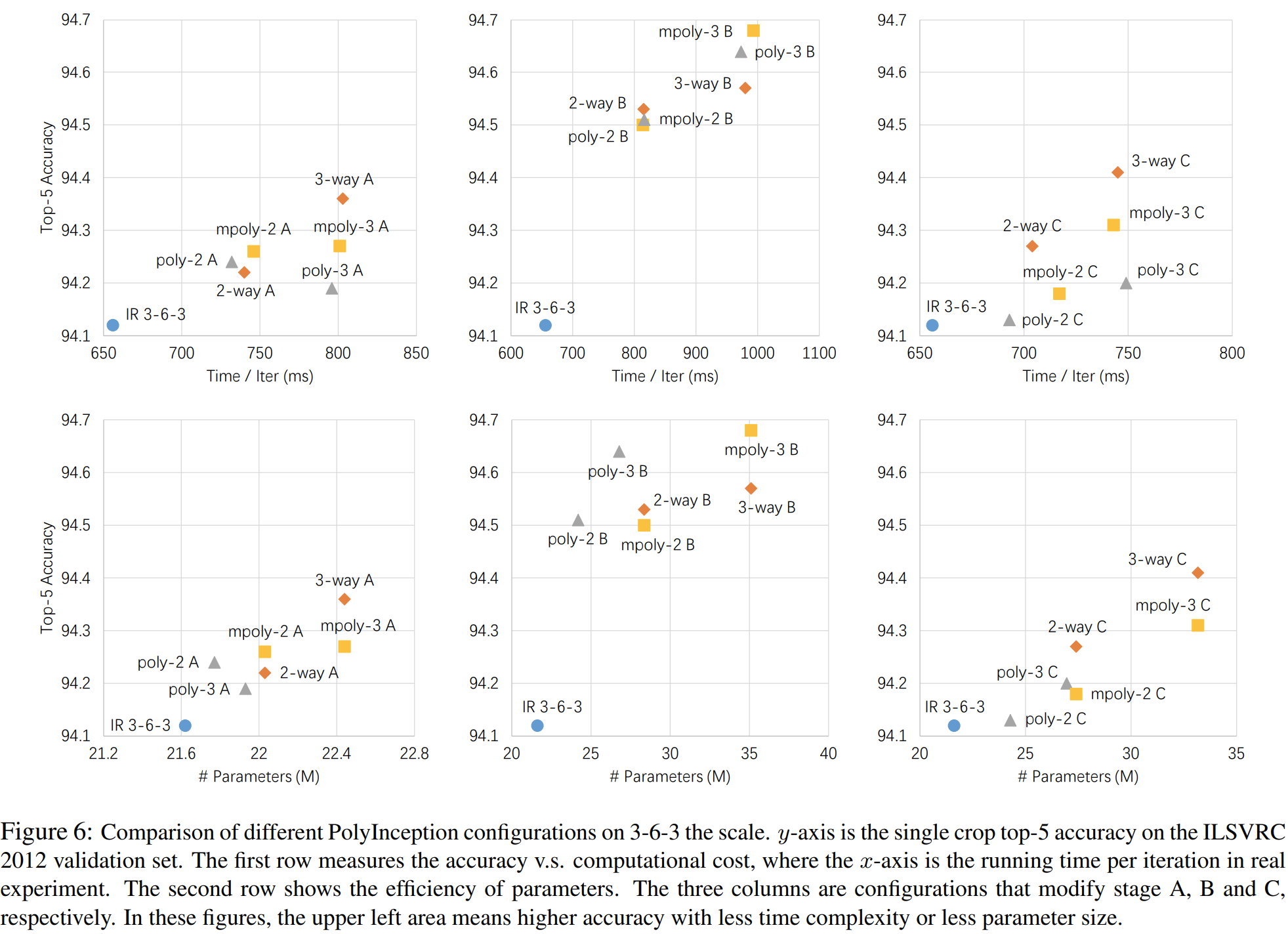
그림6은 비용 (학습 시간/파라미터 개수) vs 성능에 따른 변화를 보여주고 있습니다. 모든 결과에 대해서 IR-3-6-3 보다도 더 높은 결과를 얻을 수 있으며 특히, B stage의 모듈을 PolyInception Module로 교체했을 때 가장 높은 성능향상을 얻을 수 있습니다.
3). Mixing Different PolyInception Designs
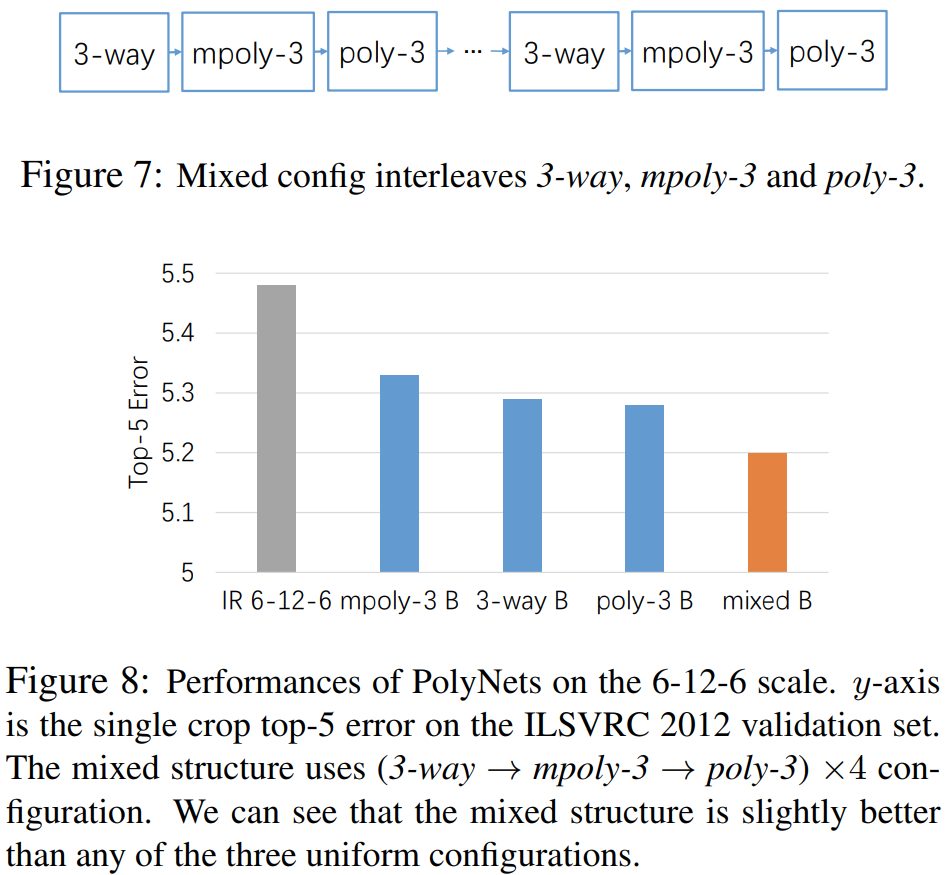
다음으로 그림7과 같은 단일 PolyInception Module을 사용하는 것이 아니라 여러 개를 함께 사용했을 때 성능을 그림8에서 볼 수 있습니다. 섞어서 썻을 때 성능이 가장 좋은 것을 볼 수 있죠.
4). Designing Very Deep PolyNet
위 실험결과들을 기반으로 더 깊은 PolyNet을 제안합니다. Stage A에서는 10개의 2-way PolyInception Module, Stage B에서는 10개씩 poly-3와 2-way PolyInception Module을 함께 사용하여 총 20개, Stage C에서는 5개씩 poly-3와 2-way PolyInception Module을 함께 사용하여 총 10개를 사용하여 PolyNet-10-20-10 구조를 제안합니다.
Experiment Results
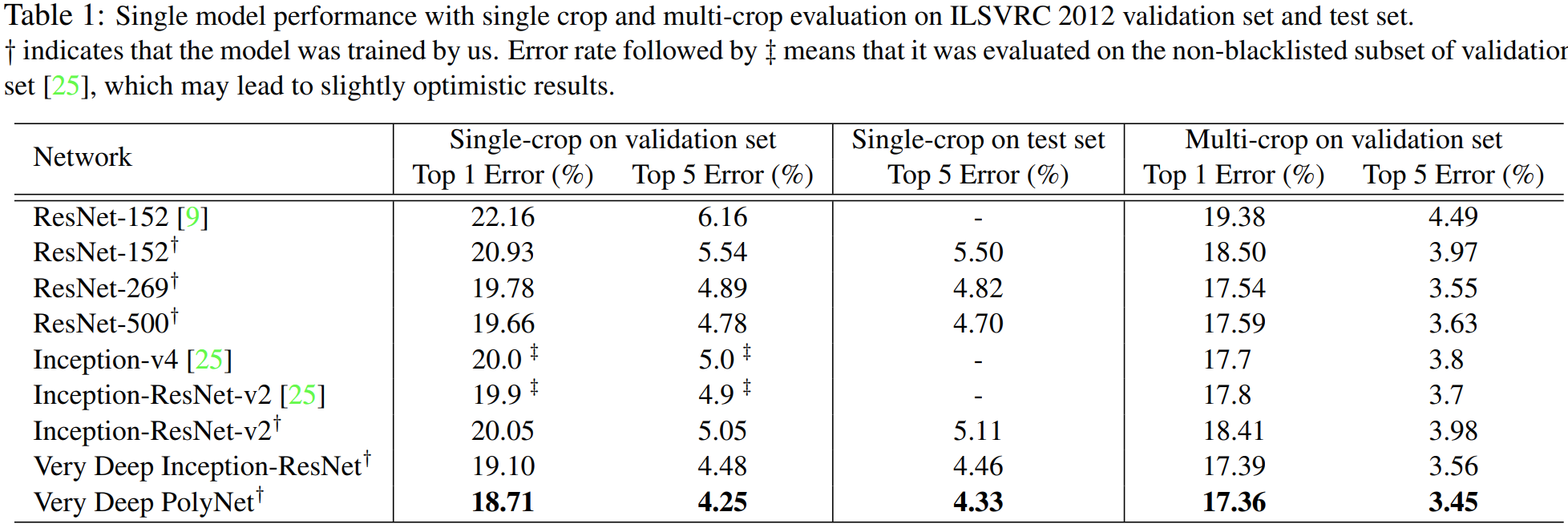
마지막으로 ImageNet 데이터셋에 대한 분류 성능을 보여주고 논문이 마무리 됩니다.
Implementation Code
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_block(x)
class PolyConv(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, kernel_size, stride, padding):
super(PolyConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.bn_blocks = nn.ModuleList([nn.BatchNorm2d(out_channels) for _ in range(num_blocks)])
self.relu = nn.ReLU(inplace=True)
def forward(self, x, block_index):
x = self.conv(x)
bn = self.bn_blocks[block_index]
x = bn(x)
x = self.relu(x)
return ximport torch
import torch.nn as nn
from .layers import BasicConv, PolyConv
class MultiWay(nn.Module):
def __init__(self, scale, block_type, num_blocks):
super(MultiWay, self).__init__()
assert num_blocks >= 1, 'num_blocks should be greater than 1 or equal to 1'
self.scale = scale
self.blocks = nn.ModuleList([block_type() for _ in range(num_blocks)])
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = x
for block in self.blocks:
out = out + block(x) * self.scale
out = self.relu(out)
return out
class PolyStem(nn.Module):
def __init__(self, in_channels):
super(PolyStem, self).__init__()
self.conv1 = BasicConv(in_channels, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv2 = BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv3 = BasicConv(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv4_1 = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv4_2 = BasicConv(64, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv5_1 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv5_2 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 64, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)),
BasicConv(64, 64, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv6_1 = BasicConv(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv6_2 = nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out1 = self.conv4_1(out)
out2 = self.conv4_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv5_1(out)
out2 = self.conv5_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv6_1(out)
out2 = self.conv6_2(out)
out = torch.cat([out1, out2], dim=1)
return out
class PolyNetBlockA(nn.Module):
def __init__(self):
super(PolyNetBlockA, self).__init__()
self.branch1 = nn.Sequential(
BasicConv(384, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(48, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.branch2 = nn.Sequential(
BasicConv(384, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.branch3 = BasicConv(384, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.out_conv = BasicConv(128, 384, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
out = torch.cat([branch1, branch2, branch3], dim=1)
out = self.out_conv(out)
return out
class PolyNetBlockB(nn.Module):
def __init__(self):
super(PolyNetBlockB, self).__init__()
self.branch1 = nn.Sequential(
BasicConv(1152, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(128, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)))
self.branch2 = BasicConv(1152, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.out_conv = BasicConv(384, 1152, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
out = torch.cat([branch1, branch2], dim=1)
out = self.out_conv(out)
return out
class PolyNetBlockC(nn.Module):
def __init__(self):
super(PolyNetBlockC, self).__init__()
self.branch1 = nn.Sequential(
BasicConv(2048, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 224, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)),
BasicConv(224, 256, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
self.branch2 = BasicConv(2048, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.out_conv = BasicConv(448, 2048, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
out = torch.cat([branch1, branch2], dim=1)
out = self.out_conv(out)
return out
class InceptionResNetBPoly(nn.Module):
def __init__(self, scale, num_blocks):
super(InceptionResNetBPoly, self).__init__()
self.scale = scale
self.num_blocks = num_blocks
self.branch1_1x1 = PolyConv(1152, 128, num_blocks=self.num_blocks, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch1_1x7 = PolyConv(128, 160, num_blocks=self.num_blocks, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3))
self.branch1_7x1 = PolyConv(160, 192, num_blocks=self.num_blocks, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0))
self.branch2_1x1 = PolyConv(1152, 192, num_blocks=self.num_blocks, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.out_conv = nn.ModuleList(BasicConv(384, 1152, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)) for _ in range(self.num_blocks))
self.relu = nn.ReLU(inplace=True)
def forward_block(self, x, block_index):
x0 = self.branch1_1x1(x, block_index)
x0 = self.branch1_1x7(x0, block_index)
x0 = self.branch1_7x1(x0, block_index)
x1 = self.branch1_1x1(x, block_index)
out = torch.cat([x0, x1], dim=1)
out = self.out_conv[block_index](out)
return out
def forward(self, x):
out = x
for block_index in range(self.num_blocks):
x = self.forward_block(x, block_index)
out = out + x * self.scale
x = self.relu(x)
out = self.relu(out)
return out
class InceptionResNetCPoly(nn.Module):
def __init__(self, scale, num_blocks):
super(InceptionResNetCPoly, self).__init__()
self.scale = scale
self.num_blocks = num_blocks
self.branch1_1x1 = PolyConv(2048, 192, num_blocks=self.num_blocks, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch1_1x3 = PolyConv(192, 224, num_blocks=self.num_blocks, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
self.branch1_3x1 = PolyConv(224, 256, num_blocks=self.num_blocks, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
self.branch2_1x1 = PolyConv(2048, 192, num_blocks=self.num_blocks, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.out_conv = nn.ModuleList(BasicConv(448, 2048, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)) for _ in range(self.num_blocks))
self.relu = nn.ReLU(inplace=True)
def forward_block(self, x, block_index):
x0 = self.branch1_1x1(x, block_index)
x0 = self.branch1_1x3(x0, block_index)
x0 = self.branch1_3x1(x0, block_index)
x1 = self.branch1_1x1(x, block_index)
out = torch.cat([x0, x1], dim=1)
out = self.out_conv[block_index](out)
return out
def forward(self, x):
out = x
for block_index in range(self.num_blocks):
x = self.forward_block(x, block_index)
out = out + x * self.scale
x = self.relu(x)
out = self.relu(out)
return out
class PolyNetReductionA(nn.Module):
def __init__(self):
super(PolyNetReductionA, self).__init__()
self.branch1 = nn.Sequential(
BasicConv(384, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(256, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
)
self.branch2 = BasicConv(384, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch3 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
out = torch.cat([branch1, branch2, branch3], dim=1)
return out
class PolyNetReductionB(nn.Module):
"""A dimensionality reduction block that is placed after stage-b
Inception-ResNet blocks.
"""
def __init__(self):
super(PolyNetReductionB, self).__init__()
self.branch1 = nn.Sequential(
BasicConv(1152, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch2 = nn.Sequential(
BasicConv(1152, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch3 = nn.Sequential(
BasicConv(1152, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),)
self.branch4 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
out = torch.cat([branch1, branch2, branch3, branch4], dim=1)
return out
class PolyInceptionA2Way(MultiWay):
def __init__(self, scale):
super(PolyInceptionA2Way, self).__init__(scale, block_type=PolyNetBlockA, num_blocks=2)
class PolyInceptionB2Way(MultiWay):
def __init__(self, scale):
super(PolyInceptionB2Way, self).__init__(scale, block_type=PolyNetBlockB, num_blocks=2)
class PolyInceptionC2Way(MultiWay):
def __init__(self, scale):
super(PolyInceptionC2Way, self).__init__(scale, block_type=PolyNetBlockC, num_blocks=2)
class InceptionResNetBPoly3(InceptionResNetBPoly):
def __init__(self, scale):
super(InceptionResNetBPoly3, self).__init__(scale, num_blocks=3)
class InceptionResNetCPoly3(InceptionResNetCPoly):
def __init__(self, scale):
super(InceptionResNetCPoly3, self).__init__(scale, num_blocks=3)
class PolyNet(nn.Module):
def __init__(self, num_channels, num_classes):
super(PolyNet, self).__init__()
self.stem = PolyStem(num_channels)
self.stage_A = nn.Sequential(
PolyInceptionA2Way(scale=1),
PolyInceptionA2Way(scale=0.992308),
PolyInceptionA2Way(scale=0.984615),
PolyInceptionA2Way(scale=0.976923),
PolyInceptionA2Way(scale=0.969231),
PolyInceptionA2Way(scale=0.961538),
PolyInceptionA2Way(scale=0.953846),
PolyInceptionA2Way(scale=0.946154),
PolyInceptionA2Way(scale=0.938462),
PolyInceptionA2Way(scale=0.930769))
self.reduction_A = PolyNetReductionA()
self.stage_B = nn.Sequential(
InceptionResNetBPoly3(scale=0.923077),
PolyInceptionB2Way(scale=0.915385),
InceptionResNetBPoly3(scale=0.907692),
PolyInceptionB2Way(scale=0.9),
InceptionResNetBPoly3(scale=0.892308),
PolyInceptionB2Way(scale=0.884615),
InceptionResNetBPoly3(scale=0.876923),
PolyInceptionB2Way(scale=0.869231),
InceptionResNetBPoly3(scale=0.861538),
PolyInceptionB2Way(scale=0.853846),
InceptionResNetBPoly3(scale=0.846154),
PolyInceptionB2Way(scale=0.838462),
InceptionResNetBPoly3(scale=0.830769),
PolyInceptionB2Way(scale=0.823077),
InceptionResNetBPoly3(scale=0.815385),
PolyInceptionB2Way(scale=0.807692),
InceptionResNetBPoly3(scale=0.8),
PolyInceptionB2Way(scale=0.792308),
InceptionResNetBPoly3(scale=0.784615),
PolyInceptionB2Way(scale=0.776923))
self.reduction_B = PolyNetReductionB()
self.stage_C = nn.Sequential(
InceptionResNetCPoly3(scale=0.769231),
PolyInceptionC2Way(scale=0.761538),
InceptionResNetCPoly3(scale=0.753846),
PolyInceptionC2Way(scale=0.746154),
InceptionResNetCPoly3(scale=0.738462),
PolyInceptionC2Way(scale=0.730769),
InceptionResNetCPoly3(scale=0.723077),
PolyInceptionC2Way(scale=0.715385),
InceptionResNetCPoly3(scale=0.707692),
PolyInceptionC2Way(scale=0.7))
self.avg_pool = nn.AvgPool2d(9, stride=1)
self.dropout = nn.Dropout(0.2)
self.last_linear = nn.Linear(2048, num_classes)
def features(self, x):
x = self.stem(x)
x = self.stage_A(x)
x = self.reduction_A(x)
x = self.stage_B(x)
x = self.reduction_B(x)
x = self.stage_C(x)
return x
def logits(self, x):
x = self.avg_pool(x)
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, x):
x = self.features(x)
x = self.logits(x)
return x