
안녕하세요. 지난 포스팅의 [IC2D] Deep Pyramid Residual Networks (CVPR2017)에서는 피라미드와 같이 점진적으로 블럭 내의 너비를 점점 늘리는 모델인 PyramidNet을 제안하였습니다. 이때, residual path와 identity path 사이의 사이즈를 맞추기 위해 zero-padded shortcut connection이라는 방법을 도입하였죠. 오늘은 Inception 기반 모델의 변형인 Inception-v4와 residual network와 결합한 Inception-ResNet, 이 두 가지 모델에 대해서 소개해드리도록 하겠습니다.
Background
지금까지 저희가 공부했던 많은 영상 분류 모델들은 모두 ResNet을 기반으로 구성되어있음을 알 수 있습니다. 대표적으로, PreAct ResNet, WRN, ResNext, DenseNet, PyramidNet 이 있었죠. 물론, 각 모델들의 세세한 구현은 다를 수 있지만 핵심은 residual path를 도입하였다는 점 입니다. 여기서 한 가지 다른 변형이 있었죠. 바로, ResNext입니다. 이 모델은 ResNet을 기반으로 구성하였지만 가장 큰 특성은 multi-path 구조는 Inception 모델로부터 왔다고 볼 수 있습니다. 오늘 소개할 Inception 모델은 ResNext와는 다르게 각 path가 서로 다른 구조로 이루어져있으며 이를 ResNet과 결합한 모델이라고 볼 수 있겠습니다.
Architecture Choices
1). Inception Module in Inception-v1 ~ v3
일단, Inception-v4의 상세 구조를 설명하기 전에 이전에 소개해드렸던 Inception-v1 ~ v3의 구조를 설명드리도록 하겠습니다.

위 그림은 Inception-v1의 inception module입니다. 각 path는 다양한 필터 크기를 가진 합성곱 계층으로 이루어져 있으며 각 path를 통과한 특징 맵들은 하나로 합쳐져서 다음 블록으로 전달됩니다. 하지만, 깊은 모델을 사용하게 되면 특징 맵의 채널 개수가 아주 많아지기 때문에 연산량을 줄이고자 (b)와 같이 $1 \timse 1$ 합성곱 계층을 추가하여 비선형성을 늘리고 채널의 개수를 조절하는 방식을 택하게 되었죠.

위 그림은 Inception-v2 및 v3에서 사용한 inception module입니다. 기존 inception module이 multi-path 구조에서 다양한 필터의 크기를 이용하였지만 이는 연산량을 늘리는 원인이 됩니다. 따라서, 큰 필터 크기를 작은 필터 크기를 사용하는 여러 개의 합성곱 계층으로 대체함으로써 연산량을 줄이는 효과를 얻게 됩니다. 이뿐만 아니라 비대칭성 (asymmetric) 분해를 적용하여 추가적으로 연산량을 더 줄이게 되죠.
2). Inception-v4

그림9는 본 논문에서 제안하는 모델 중 하나인 Inception-v4의 전체적인 구조입니다. 모델을 보시면 Stem 블록 이후에 Inception-A, Reduction-A, Inception-B, Reduction-B, Inception-C가 순서대로 사용되고 있습니다. 이제부터는 각 모듈이 어떻게 설계되었는 지 보도록 하겠습니다.
Stem Block

Inception-A

Reduction-A

Inception-B

Reduction-B

Inception-C

위 그림들은 Inception-v4 내에서 사용된 모듈의 상세한 블록 다이어그램입니다. 아무래도 Inception의 전통대로 모델을 구성하였기 때문에 모델자체는 많이 복잡해보이는 것은 사실입니다. 하지만, 실질적으로 기존의 Inception-v1와 Inception-v3의 블록을 많이 차용하여 구성하였기 때문에 이전의 Inception 모델만 이해하신다면 구현자체는 쉽습니다.
3). Inception-ResNet-v1 and Inception-ResNet-v2

그림15는 본 논문에서 제안하는 모델 중 하나인 Inception-ResNet-v1과 Inception-ResNet-v2의 전체적인 구조입니다. 모델을 보시면 Stem 블록 이후에 Inception-resnet-A, Reduction-A, Inception-resnet-B, Reduction-B, Inception-resnet-C가 순서대로 사용되고 있습니다. 이제부터는 각 모듈이 어떻게 설계되었는 지 보도록 하겠습니다. 이때, 주의할 점은 Inception-ResNet-v1과 Inception-ResNet-v2에는 약간의 차이점이 존재하기 때문에 이 부분을 유의하면서 봐야합니다.
Inception-ResNet-v1
Stem Block (V1)

Inception-resnet-A (V1)

Reduction-A (V1)

Inception-resnet-B (V1)

Reduction-B (V1)

Inception-resnet-C (V1)

Inception-ResNet-v2
Stem Block (V2)

Inception-resnet-A (V2)

Reduction-A (V2)

Inception-resnet-B (V2)

Reduction-B (V2)

Inception-resnet-C (V2)
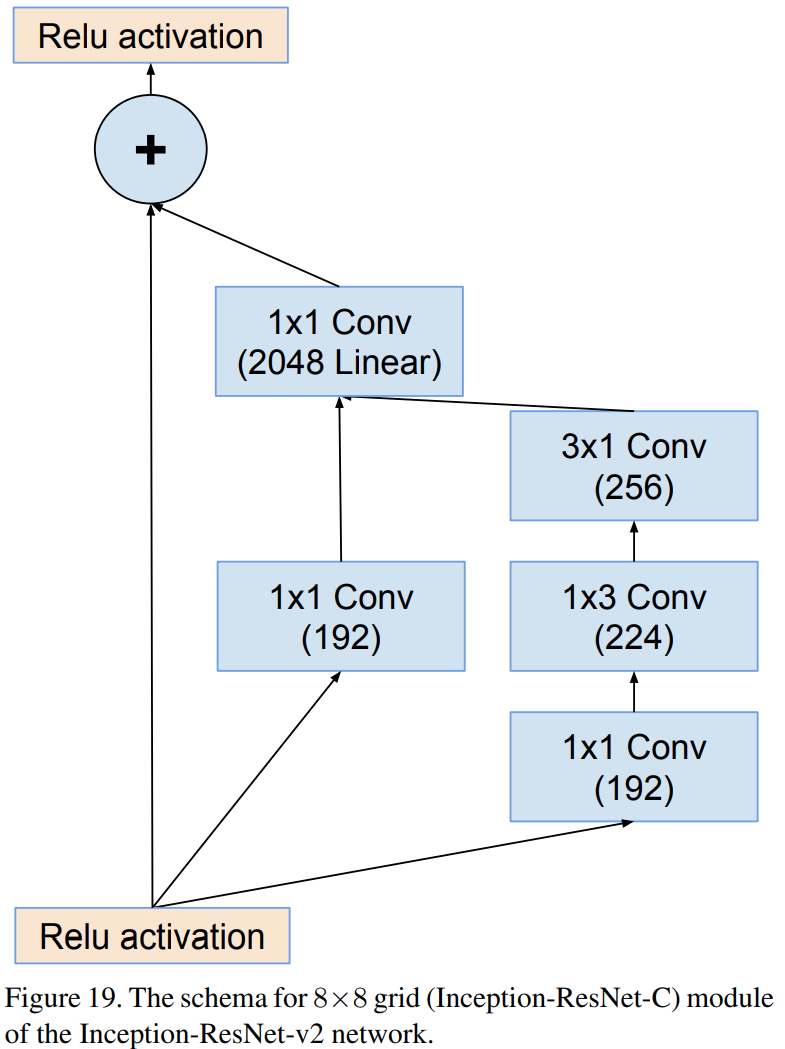
Inception-resnet-v1과 Inception-resnet-v2의 차이점은 Stem Block과 각 Inception Module에서 사용된 path 및 필터의 개수 차이입니다. 상대적으로 Inception-resnet-v2가 Inception-v4와 유사한 파라미터를 가지고 있으며 Inception-resnet-v1와 Inception-v3가 유사한 파라미터를 가지고 있기 때문에 본 논문에서는 각각 비교를 진행합니다.
Experiment Results

그림21은 Inception-resnet-v1와 Inception-v3의 학습 비교를 하고 있습니다. 보시면 Inception-resnet-v1의 학습속도가 Inception-v3에 비해 훨씬 빠른 것을 알 수 있습니다.
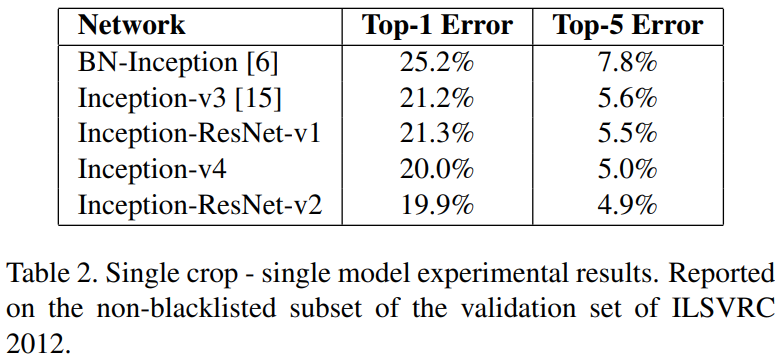
다음으로 다양한 Inception 모델 사이의 비교를 진행합니다. 결과는 본 논문에서 제안한 Inception-v4와 Inception-resnet-v2가 가장 높은 성능을 보이고 있습니다. Inception-resnet-v1와 Inception-v3은 유사한 파라미터를 가지기 떄문에 성능 차이가 낮은 것을 볼 수 있습니다.
Implementation Code
1). Inception-v4
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_block(x)
class InceptionStem(nn.Module):
def __init__(self, in_channels):
super(InceptionStem, self).__init__()
self.conv1 = BasicConv(in_channels, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv2 = BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv3 = BasicConv(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv4_1 = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv4_2 = BasicConv(64, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv5_1 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv5_2 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 64, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)),
BasicConv(64, 64, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv6_1 = BasicConv(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv6_2 = nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out1 = self.conv4_1(out)
out2 = self.conv4_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv5_1(out)
out2 = self.conv5_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv6_1(out)
out2 = self.conv6_2(out)
out = torch.cat([out1, out2], dim=1)
return out
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(in_channels, 96, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_1x1 = nn.Sequential(
BasicConv(in_channels, 96, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_3x3 = nn.Sequential(
BasicConv(in_channels, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_1x1 = self.branch_1x1(x)
branch_3x3 = self.branch_3x3(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_1x1, branch_3x3, branch_3x3_stack], dim=1)
class ReductionA(nn.Module): # k=192, l=224, m=256, n=384
def __init__(self, in_channels):
super(ReductionA, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3 = BasicConv(in_channels, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(224, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3 = self.branch_3x3(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_3x3, branch_3x3_stack], dim=1)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(in_channels, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_1x1 = nn.Sequential(
BasicConv(in_channels, 384, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_7x7 = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 224, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(224, 256, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)))
self.branch_7x7_stack = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(192, 224, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)),
BasicConv(224, 224, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(224, 256, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0))
)
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_1x1 = self.branch_1x1(x)
branch_7x7 = self.branch_7x7(x)
branch_7x7_stack = self.branch_7x7_stack(x)
return torch.cat([branch_pool, branch_1x1, branch_7x7, branch_7x7_stack], dim=1)
class ReductionB(nn.Module):
def __init__(self, in_channels):
super(ReductionB, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3 = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch_7x7_3x3 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(256, 320, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)),
BasicConv(320, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3 = self.branch_3x3(x)
branch_7x7_3x3 = self.branch_7x7_3x3(x)
return torch.cat([branch_pool, branch_3x3, branch_7x7_3x3], dim=1)
class InceptionC(nn.Module):
def __init__(self, in_channels):
super(InceptionC, self).__init__()
self.branch_pool = nn.Sequential(
nn.AvgPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_1x1 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_1x1_1 = nn.Sequential(
BasicConv(in_channels, 384, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)))
self.branch_1x1_1x3 = nn.Sequential(
BasicConv(384, 256, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)))
self.branch_1x1_3x1 = nn.Sequential(
BasicConv(384, 256, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
self.branch_3x3_stack_1 = nn.Sequential(
BasicConv(in_channels, 384, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(384, 448, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)),
BasicConv(448, 512, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
self.branch_3x3_stack_1x3 = nn.Sequential(
BasicConv(512, 256, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)))
self.branch_3x3_stack_3x1 = nn.Sequential(
BasicConv(512, 256, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_1x1 = self.branch_1x1(x)
branch_1x1_1 = self.branch_1x1_1(x)
branch_1x1_1x3 = self.branch_1x1_1x3(branch_1x1_1)
branch_1x1_3x1 = self.branch_1x1_3x1(branch_1x1_1)
branch_3x3_stack_1 = self.branch_3x3_stack_1(x)
branch_3x3_stack_1x3 = self.branch_3x3_stack_1x3(branch_3x3_stack_1)
branch_3x3_stack_3x1 = self.branch_3x3_stack_3x1(branch_3x3_stack_1)
return torch.cat([branch_pool, branch_1x1, branch_1x1_1x3, branch_1x1_3x1, branch_3x3_stack_1x3, branch_3x3_stack_3x1], dim=1)
class InceptionV4(nn.Module):
def __init__(self, num_channels, num_classes):
super(InceptionV4, self).__init__()
self.stem_block = InceptionStem(num_channels)
self.inceptionA1 = InceptionA(384)
self.inceptionA2 = InceptionA(384)
self.inceptionA3 = InceptionA(384)
self.inceptionA4 = InceptionA(384)
self.inceptionA5 = InceptionA(384)
self.reductionA = ReductionA(384)
self.inceptionB1 = InceptionB(1024)
self.inceptionB2 = InceptionB(1024)
self.inceptionB3 = InceptionB(1024)
self.inceptionB4 = InceptionB(1024)
self.inceptionB5 = InceptionB(1024)
self.inceptionB6 = InceptionB(1024)
self.inceptionB7 = InceptionB(1024)
self.reductionB = ReductionB(1024)
self.inceptionC1 = InceptionC(1536)
self.inceptionC2 = InceptionC(1536)
self.inceptionC3 = InceptionC(1536)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout2d(p=0.8)
self.linear = nn.Linear(1536, num_classes)
def forward(self, x):
out = self.stem_block(x)
out = self.inceptionA1(out)
out = self.inceptionA2(out)
out = self.inceptionA3(out)
out = self.inceptionA4(out)
out = self.inceptionA5(out)
out = self.reductionA(out)
out = self.inceptionB1(out)
out = self.inceptionB2(out)
out = self.inceptionB3(out)
out = self.inceptionB4(out)
out = self.inceptionB5(out)
out = self.inceptionB6(out)
out = self.inceptionB7(out)
out = self.reductionB(out)
out = self.inceptionC1(out)
out = self.inceptionC2(out)
out = self.inceptionC3(out)
out = self.avgpool(out)
out = self.dropout(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
if __name__=="__main__":
import torch
model = InceptionV4(num_channels=3, num_classes=1000).cuda()
inp = torch.randn((2, 3, 224, 224)).cuda()
out5 = model(inp)
print("out5 shape : ", out5.shape)
2). Inception-ResNet-v1
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_block(x)
class InceptionStem(nn.Module):
def __init__(self, in_channels):
super(InceptionStem, self).__init__()
self.conv_block = nn.Sequential(
BasicConv(in_channels, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
BasicConv(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(64, 80, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(80, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(192, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
)
def forward(self, x):
return self.conv_block(x)
class InceptionResNetA(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetA, self).__init__()
self.branch1x1 = BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch3x3 = nn.Sequential(
BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
self.branch3x3_stack = nn.Sequential(
BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
self.residual_branch = BasicConv(96, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 256, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch3x3(x), self.branch3x3_stack(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class ReductionA(nn.Module): # k=192, l=192, m=256, n=384
def __init__(self, in_channels):
super(ReductionA, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3 = BasicConv(in_channels, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(192, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3 = self.branch_3x3(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_3x3, branch_3x3_stack], dim=1)
class InceptionResNetB(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetB, self).__init__()
self.branch1x1 = BasicConv(in_channels, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch7x7 = nn.Sequential(
BasicConv(in_channels, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)))
self.residual_branch = BasicConv(256, 896, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 896, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch7x7(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class ReductionB(nn.Module): # k=192, l=192, m=256, n=384
def __init__(self, in_channels):
super(ReductionB, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3_1 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch_3x3_2 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3_1 = self.branch_3x3_1(x)
branch_3x3_2 = self.branch_3x3_2(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_3x3_1, branch_3x3_2, branch_3x3_stack], dim=1)
class InceptionResNetC(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetC, self).__init__()
self.branch1x1 = BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)),
BasicConv(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
self.residual_branch = BasicConv(384, 1792, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 1792, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch_3x3_stack(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class InceptionResNetV1(nn.Module):
def __init__(self, num_channels, num_classes):
super(InceptionResNetV1, self).__init__()
self.stem_block = InceptionStem(num_channels)
self.inception_residual_A1 = InceptionResNetA(256)
self.inception_residual_A2 = InceptionResNetA(256)
self.inception_residual_A3 = InceptionResNetA(256)
self.inception_residual_A4 = InceptionResNetA(256)
self.inception_residual_A5 = InceptionResNetA(256)
self.reductionA = ReductionA(256)
self.inception_residual_B1 = InceptionResNetB(896)
self.inception_residual_B2 = InceptionResNetB(896)
self.inception_residual_B3 = InceptionResNetB(896)
self.inception_residual_B4 = InceptionResNetB(896)
self.inception_residual_B5 = InceptionResNetB(896)
self.inception_residual_B6 = InceptionResNetB(896)
self.inception_residual_B7 = InceptionResNetB(896)
self.inception_residual_B8 = InceptionResNetB(896)
self.inception_residual_B9 = InceptionResNetB(896)
self.inception_residual_B10 = InceptionResNetB(896)
self.reductionB = ReductionB(896)
self.inception_residual_C1 = InceptionResNetC(1792)
self.inception_residual_C2 = InceptionResNetC(1792)
self.inception_residual_C3 = InceptionResNetC(1792)
self.inception_residual_C4 = InceptionResNetC(1792)
self.inception_residual_C5 = InceptionResNetC(1792)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout2d(p=0.8)
self.linear = nn.Linear(1792, num_classes)
def forward(self, x):
out = self.stem_block(x)
out = self.inception_residual_A1(out)
out = self.inception_residual_A2(out)
out = self.inception_residual_A3(out)
out = self.inception_residual_A4(out)
out = self.inception_residual_A5(out)
out = self.reductionA(out)
out = self.inception_residual_B1(out)
out = self.inception_residual_B2(out)
out = self.inception_residual_B3(out)
out = self.inception_residual_B4(out)
out = self.inception_residual_B5(out)
out = self.inception_residual_B6(out)
out = self.inception_residual_B7(out)
out = self.inception_residual_B8(out)
out = self.inception_residual_B9(out)
out = self.inception_residual_B10(out)
out = self.reductionB(out)
out = self.inception_residual_C1(out)
out = self.inception_residual_C2(out)
out = self.inception_residual_C3(out)
out = self.inception_residual_C4(out)
out = self.inception_residual_C5(out)
out = self.avgpool(out)
out = self.dropout(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
if __name__=="__main__":
import torch
model = InceptionResNetV1(num_channels=3, num_classes=1000).cuda()
inp = torch.randn((2, 3, 224, 224)).cuda()
out5 = model(inp)
print("out5 shape : ", out5.shape)
3). Inception-ResNet-v2
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv_block(x)
class InceptionStem(nn.Module):
def __init__(self, in_channels):
super(InceptionStem, self).__init__()
self.conv1 = BasicConv(in_channels, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv2 = BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv3 = BasicConv(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv4_1 = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv4_2 = BasicConv(64, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.conv5_1 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv5_2 = nn.Sequential(
BasicConv(160, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(64, 64, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)),
BasicConv(64, 64, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
self.conv6_1 = BasicConv(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.conv6_2 = nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out1 = self.conv4_1(out)
out2 = self.conv4_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv5_1(out)
out2 = self.conv5_2(out)
out = torch.cat([out1, out2], dim=1)
out1 = self.conv6_1(out)
out2 = self.conv6_2(out)
out = torch.cat([out1, out2], dim=1)
return out
class InceptionResNetA(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetA, self).__init__()
self.branch1x1 = BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch3x3 = nn.Sequential(
BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
self.branch3x3_stack = nn.Sequential(
BasicConv(in_channels, 32, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(32, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(48, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
self.residual_branch = BasicConv(128, 384, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 384, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch3x3(x), self.branch3x3_stack(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class ReductionA(nn.Module): # k=256, l=256, m=384, n=384
def __init__(self, in_channels):
super(ReductionA, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3 = BasicConv(in_channels, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(256, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3 = self.branch_3x3(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_3x3, branch_3x3_stack], dim=1)
class InceptionResNetB(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetB, self).__init__()
self.branch1x1 = BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch7x7 = nn.Sequential(
BasicConv(in_channels, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(128, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3)),
BasicConv(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0)))
self.residual_branch = BasicConv(384, 1154, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 1154, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch7x7(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class ReductionB(nn.Module): # k=192, l=192, m=256, n=384
def __init__(self, in_channels):
super(ReductionB, self).__init__()
self.branch_pool = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.branch_3x3_1 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch_3x3_2 = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 288, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 256, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(256, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
BasicConv(288, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
def forward(self, x):
branch_pool = self.branch_pool(x)
branch_3x3_1 = self.branch_3x3_1(x)
branch_3x3_2 = self.branch_3x3_2(x)
branch_3x3_stack = self.branch_3x3_stack(x)
return torch.cat([branch_pool, branch_3x3_1, branch_3x3_2, branch_3x3_stack], dim=1)
class InceptionResNetC(nn.Module):
def __init__(self, in_channels):
super(InceptionResNetC, self).__init__()
self.branch1x1 = BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch_3x3_stack = nn.Sequential(
BasicConv(in_channels, 192, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1)),
BasicConv(192, 256, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0)))
self.residual_branch = BasicConv(448, 2048, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.shortcut = nn.Conv2d(in_channels, 2048, kernel_size=1)
def forward(self, x):
residual_branch = torch.cat([self.branch1x1(x), self.branch_3x3_stack(x)], dim=1)
residual_branch = self.residual_branch(residual_branch)
x = self.shortcut(x)
return F.relu(x + residual_branch)
class InceptionResNetV2(nn.Module):
def __init__(self, num_channels, num_classes):
super(InceptionResNetV2, self).__init__()
self.stem_block = InceptionStem(num_channels)
self.inception_residual_A1 = InceptionResNetA(384)
self.inception_residual_A2 = InceptionResNetA(384)
self.inception_residual_A3 = InceptionResNetA(384)
self.inception_residual_A4 = InceptionResNetA(384)
self.inception_residual_A5 = InceptionResNetA(384)
self.reductionA = ReductionA(384)
self.inception_residual_B1 = InceptionResNetB(1152)
self.inception_residual_B2 = InceptionResNetB(1154)
self.inception_residual_B3 = InceptionResNetB(1154)
self.inception_residual_B4 = InceptionResNetB(1154)
self.inception_residual_B5 = InceptionResNetB(1154)
self.inception_residual_B6 = InceptionResNetB(1154)
self.inception_residual_B7 = InceptionResNetB(1154)
self.inception_residual_B8 = InceptionResNetB(1154)
self.inception_residual_B9 = InceptionResNetB(1154)
self.inception_residual_B10 = InceptionResNetB(1154)
self.reductionB = ReductionB(1154)
self.inception_residual_C1 = InceptionResNetC(2146)
self.inception_residual_C2 = InceptionResNetC(2048)
self.inception_residual_C3 = InceptionResNetC(2048)
self.inception_residual_C4 = InceptionResNetC(2048)
self.inception_residual_C5 = InceptionResNetC(2048)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout2d(p=0.8)
self.linear = nn.Linear(2048, num_classes)
def forward(self, x):
out = self.stem_block(x)
out = self.inception_residual_A1(out)
out = self.inception_residual_A2(out)
out = self.inception_residual_A3(out)
out = self.inception_residual_A4(out)
out = self.inception_residual_A5(out)
out = self.reductionA(out)
out = self.inception_residual_B1(out)
out = self.inception_residual_B2(out)
out = self.inception_residual_B3(out)
out = self.inception_residual_B4(out)
out = self.inception_residual_B5(out)
out = self.inception_residual_B6(out)
out = self.inception_residual_B7(out)
out = self.inception_residual_B8(out)
out = self.inception_residual_B9(out)
out = self.inception_residual_B10(out)
out = self.reductionB(out)
out = self.inception_residual_C1(out)
out = self.inception_residual_C2(out)
out = self.inception_residual_C3(out)
out = self.inception_residual_C4(out)
out = self.inception_residual_C5(out)
out = self.avgpool(out)
out = self.dropout(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
if __name__=="__main__":
import torch
model = InceptionResNetV2(num_channels=3, num_classes=1000).cuda()
inp = torch.randn((2, 3, 224, 224)).cuda()
out5 = model(inp)
print("out5 shape : ", out5.shape)