
안녕하세요. 오늘은 대표적인 Transformer 기반의 의료 영상 분할 모델 중 하나인 MISSFormer에 대해서 소개하도록 하겠습니다.
MISSFormer: An Effective Medical Image Segmentation Transformer
The CNN-based methods have achieved impressive results in medical image segmentation, but they failed to capture the long-range dependencies due to the inherent locality of the convolution operation. Transformer-based methods are recently popular in vision
arxiv.org
Background
최근 의료 영상 기술은 질병의 진단부터 수술 계획 및 치료 효과 분석까지 다양한 의료 분야에서 중요한 역할을 수행하고 있습니다. 특히 의료 이미지 분할(Medical Image Segmentation)은 의료 이미지 속 장기나 병변의 위치와 경계를 정확히 파악하여 각 픽셀 단위로 분류하는 핵심 기술입니다. 기존에는 주로 CNN(Convolutional Neural Network)을 기반으로 한 모델이 활용되어 왔습니다. 그러나 CNN은 이미지의 국지적(Local) 특징은 잘 포착하지만, 전체적인 이미지 내에서 떨어져 있는 영역 간의 관계, 즉 글로벌(Global)한 의존성(Dependencies)을 효과적으로 학습하지 못한다는 단점이 있습니다.
이러한 한계를 극복하기 위해 최근 Transformer 기반의 의료 이미지 분할 모델들(예: TransUNet, SwinUNet)이 등장했습니다. Transformer는 글로벌 의존성을 뛰어나게 모델링할 수 있는 구조를 가지고 있지만, 여전히 다음과 같은 문제점들을 가지고 있습니다.
- 입력 이미지의 해상도가 커질수록 계산량이 급격히 증가하여 현실적인 적용에 어려움이 있음 (이차적 복잡도 증가 문제)
- 글로벌 특징에 집중하면서 상대적으로 이미지의 세부적인 국지적 맥락(Local Context)을 효과적으로 다루지 못함
- 다양한 크기의 멀티스케일 특징(Multi-scale feature)들 간의 글로벌-로컬 상관관계(Global-local correlations)를 충분히 반영하지 못함
본 논문에서 제안하는 MISSFormer의 핵심 아이디어는 Transformer 구조 내의 피드포워드 네트워크(FFN)를 재설계한 ReMix-FFN과, 다양한 크기의 특징들을 통합하여 글로벌-로컬 상관관계를 효과적으로 학습하는 ReMixed Transformer Context Bridge를 통해, 기존 Transformer 모델의 글로벌 의존성뿐 아니라 국지적 맥락 정보까지 효과적으로 모델링하는 것입니다. 이를 통해 MISSFormer는 정확도와 효율성을 모두 개선하여 의료 이미지 분할 분야에서 뛰어난 성능과 견고성을 제공합니다. 본 논문의 기여는 다음과 같이 정리할 수 있습니다.
- 의료 이미지 분할에 최적화된 계층적이며 위치 임베딩(position embedding)이 필요 없는(position-free) U자형 Transformer 구조를 제안했습니다.
- 글로벌 의존성과 국지적 맥락을 효과적으로 결합하는 ReMix-FFN과, 멀티스케일 특징을 효율적으로 통합하는 ReMixed Transformer Context Bridge 모듈을 개발하여 특징 표현력을 향상시켰습니다.
- Synapse(다중 장기), ACDC(심장), DRIVE(망막 혈관) 등 다양한 의료 이미지 데이터셋에서 MISSFormer가 기존 최신 기법들보다 뛰어난 성능과 높은 일반화 성능을 가짐을 실험적으로 입증했습니다.
Proposed Method: MISSFormer
1) Overall Architecture

그림 1은 본 논문에서 제안하는 MISSFormer의 전체적인 구조입니다. 그림에서 볼 수 있는 것과 같이 MISSFormer는 의료 이미지 분할 작업에 특화된 계층적 U자형 Transformer 기반 모델입니다. MISSFormer는 크게 Encoder, ReMixed Transformer Context Bridge, 그리고 Decoder로 구성되어 있으며, 각 단계를 크게 4단계로 나누면 다음과 같은 과정을 거쳐 동작합니다.
STEP1. Overlapping Patch Embedding
먼저 입력된 의료 이미지는 국지적 연속성(Local Continuity)을 유지하기 위해 겹치는 패치(overlapping patches)로 나누어 처리됩니다. 만약, 이미지의 크기가 $H_{in} \times W_{in} \times C_{in}$ 이라면, $4 \times 4$ 픽셀 크기의 패치를, 커널 크기(kernel size)가 $7 \times 7$, 스트라이드(stride)는 4인 컨볼루션 레이어를 통해 생성합니다. 이 과정을 통해 패치를 겹치치않게 만드는 것보다 이미지의 국지적 연속성 정보를 효과적으로 유지하면서 Transformer 모델의 입력으로 활용 가능한 형태로 변환합니다.
STEP2. Hierarchical Feature Extraction
이 단계에서는 입력된 패치들을 이용하여 Transformer Block과 패치 병합(Patch Merging) 과정을 거쳐 다양한 크기(멀티스케일)의 특징을 생성합니다. Transformer Block은 ReMix-FFN 구조를 이용하여 글로벌 정보(global dependencies)와 로컬 정보(local contexts)를 동시에 학습합니다. 패치 병합(Patch Merging)은 각 스테이지가 끝난 후, 특징 맵의 크기를 줄여(Down-sampling) 계층적으로 특징을 추출하게 합니다.
STEP3. ReMixed Transformer Context Bridge
이 단계는 앞서 Encoder에서 얻어진 멀티스케일 특징들을 통합하고, 각 스케일의 글로벌 및 로컬 특징들 사이의 상관관계(correlation)를 모델링하여 더욱 정교한 특징을 추출하는 단계입니다. 먼저, 멀티스케일 특징 맵 $F_{i}$를 를 공간적(spatial) 차원에서 Flatten하여 모두 동일한 채널 차원 $C_{1}$ 으로 맞춥니다. 다음으로 변형된 특징 맵을 공간적 차원으로 서로 연결(concatenate)하여 효율적 Self-attention을 적용합니다. 이를 통해 글로벌 의존성(global dependencies)을 더욱 효과적으로 학습합니다. 다시 각 스케일로 분리(split)하여 ReMix-FFN으로 각 스케일의 글로벌-로컬 정보를 혼합하고 리파인(refine)합니다.
STEP4. Hierarchical Decoder
마지막으로 Decoder는 앞서 얻은 정교한 특징 맵과 Encoder에서의 Skip Connection을 입력으로 받습니다. 먼저, Transformer 기반 디코더 블록(Transformer Block with ReMix-FFN)을 통해 특징 맵을 업샘플링(Upsampling)합니다. 업샘플링은 패치 확장(Patch Expanding)을 통해 인접한 특징 맵을 점진적으로 원본 해상도 수준으로 복원하며, 정확한 픽셀 단위 분할 결과를 생성합니다. 최종적으로 Linear Projection 레이어를 통해 정확한 의료 이미지 분할 결과를 출력합니다.
위와 같은 구조를 통해 각 단계의 특징적인 모듈 설계를 통해 MISSFormer는 기존 Transformer 모델들의 한계였던 로컬 정보의 손실 문제와 멀티스케일 특징들의 효과적인 통합 문제를 효과적으로 극복하고, 의료 이미지 분할에서 매우 뛰어난 성능을 달성할 수 있었습니다.
이제 각 핵심모듈을 좀 더 자세하게 분석해보도록 하겠습니다.
2) Transformer Block
MISSFormer는 의료 이미지 분할 성능을 극대화하기 위해 기존 Transformer 구조를 최적화한 독창적인 Transformer 블록을 사용합니다. 이 Transformer 블록은 크게 Efficient Self-Attention, ReMix-FFN, 그리고 Recursive Feature Enhancement로 구성됩니다.
2-1) Efficient Self-Attention
기존 Transformer의 Self-Attention은 연산량이 많아 고해상도 이미지에 적용하기 어렵습니다. 이를 해결하기 위해 MISSFormer에서는 공간 축소 어텐션(Spatial Reduction Attention) 방식을 적용합니다. 이 과정은 이전에 리뷰한 PVT와 거의 유사한 방식입니다. 기본적인 Self-Attention은 아래 수식과 같습니다.
$$\text{Attention} (Q, K, V) = \text{Softmax} (\frac{QK^{T}}{\sqrt{d_{\text{head}}}})V$$
여기서 $Q, K, V$는 각각 입력된 특징을 변환한 Query, Key, Value 행렬을 의미하고 $d_{\text{head}}$는 어텐션 헤드의 차원입니다. 이때, 하지만 고해상도 입력에서 계산량이 너무 많아지는 문제를 해결하기 위해, Spatial Reduction Ratio $R$ 을 도입하여 연산량을 다음과 같이 감소시킵니다.
$$K_{\text{new}} = \text{Reshape} (\frac{N}{R}, C \cdot R) W(C \cdot R, C)$$
여기서 $\text{Reshape}(\cdot, \cdot)$은 각각 공간 차원을 축소하고 채널 수를 증가시키는 연산이고 $W$는 linear projection으로 증가된 채널 수를 다시 원래 채널 수로 압축하는 선형 변환 행렬입니다. 이 방식을 통해 연산 복잡도를 기존의 $\mathcal{O} (N^{2})$에서 $\mathcal{O} (\frac{N^{2}}{R})$ 로 줄이게 되어, 고해상도 이미지에도 효율적으로 적용할 수 있게 됩니다.
2-2) ReMix-FFN (Redesigned Feed-Forward Network)

그림 2는 SegFormer의 Mix-FFN과 MISSFormer의 ReMix-FFN 사이의 비교를 하고 있습니다. 기존 SegFormer의 Mix-FFN은 단순히 컨볼루션 연산만 추가한 구조였기 때문에 글로벌과 로컬 정보의 구분이 충분히 이루어지지 않았습니다. 이를 보완하기 위해 MISSFormer에서는 ReMix-FFN을 새롭게 설계했습니다. ReMix-FFN은 다음과 같은 수식으로 표현됩니다.
$$y_{1} = \text{LN} (\text{Conv}_{3 \times 3} (\text{FC} (x_{\text{in}})) + \text{FC} (x_{\text{in}}))$$
$$x_{\text{out}} = \text{FC} (\text{GELU}(y_{1})) + x_{\text{in}}$$
여기서, 입력된 특징 $x_{\text{in}}$ 은 먼저 FC 레이어를 거쳐 차원을 변환한 후, $3 \times 3$ Depth-wise 컨볼루션을 통해 국지적(local) 정보를 학습합니다. 이어서 이를 원본 FC 출력과 더한 후 Layer Normalization을 통해 특징 분포를 안정화합니다. 마지막으로 GELU 활성화 함수를 거쳐 다시 FC 레이어를 통과한 뒤 입력 특징과 Skip-connection으로 합쳐져 글로벌과 로컬 정보가 효과적으로 통합됩니다.
2-3) Recursive Feature Enhancement
ReMix-FFN의 특징 표현력을 더 효과적으로 개선하기 위해, MISSFormer는 재귀적(Recursive) 특징 향상 방법을 추가로 도입했습니다 (그림 2 (c)). 이는 기존 구조를 반복적으로 연결하고 Layer Normalization으로 안정화함으로써 더욱 최적화된 특징을 얻는 방법입니다. 초기값을 $y_{1} = \text{LN} (\text{Conv}_{3 \times 3} (\text{FC} (x_{\text{in}})) + \text{FC} (x_{\text{in}}))$라고 하면 재귀적 구조는 다음과 같이 표현할 수 있습니다.
$$y_{i} = \text{LN} (\text{FC}(x_{\text{in}}) + y_{i - 1})$$
그러면 최종 출력은 $x_{\text{out}} = \text{FC} (\text{GELU}(y_{i})) + x_{\text{in}}$가 됩니다. 이러한 재귀적 연결 구조를 통해 특징 표현이 더 깊고 풍부하게 학습되어 이미지 분할 성능을 크게 향상시킬 수 있었습니다.
3) ReMixed Transformer Context Bridge

그림 3은 본 논문의 skip connection에서 활용하는 ReMixed Transformer Context Bridge입니다. ReMixed Transformer Context Bridge는 MISSFormer의 핵심 모듈 중 하나로, Encoder에서 추출된 다양한 크기(multi-scale)의 특징들을 효과적으로 통합하고, 글로벌-로컬 상관관계를 명확하게 모델링하여 더욱 정확한 분할(segmentation)을 가능하게 하는 모듈입니다. 이 모듈은 다음의 네 가지 주요 단계를 통해 동작합니다.
STEP1. Multi-scale Feature Preparation
먼저 인코더에서 추출된 멀티스케일 특징 $F_{i}$ 을 다음과 같은 방법으로 변형합니다. 각 스케일에서 나온 특징 맵을 Flatten하고, 채널 차원을 모두 $C_{1}$ 로 통일합니다.
$$F_{i}: \frac{H_{\text{in}}}{2^{i + 1}} \times \frac{W_{\text{in}}}{2^{i + 1}} \times 2^{i - 1}C_{1} \rightarrow \frac{H_{\text{in}}W_{\text{in}}}{2^{i + 3}}$$
이렇게 변형된 모든 멀티스케일 특징들을 공간 차원을 기준으로 연결(concatenate)하여 하나의 특징 맵 $F_{\text{cat}}$ 을 만듭니다.
$$F_{\text{cat}} = \text{Concat} (F_{1}, F_{2}, \dots, F_{N})$$
STEP2. Global Context Modeling
이렇게 연결된 특징 맵 $F_{\text{cat}}$ 에 대해 효율적 Self-Attention(Efficient Self-Attention)을 적용하여 전체적인 글로벌 의존성(global dependency)을 학습한 $F_{\text{attn}}$을 얻습니다. 이 단계에서 학습된 글로벌 정보는 다음 단계의 특징 정제에 핵심적인 역할을 하게 됩니다.
STEP3. ReMix-FFN을 통한 글로벌-로컬 특징 통합
Self-attention으로 처리된 특징 $F_{\text{attn}}$ 을 다시 원래의 멀티스케일 형태로 분리(split)하여 각 스케일에서의 특징 맵 $F_{\text{split}, i}$ 를 얻습니다.
$$F_{\text{split}, i} = \text{Split}(F_{\text{attn}})$$
그리고 각 스케일의 특징에 ReMix-FFN을 적용하여 글로벌 및 로컬 정보를 효과적으로 결합하고 더 명확한 특징으로 재구성합니다.
$$y_{i} = \text{LN} (\text{Conv}_{3 \times 3} (\text{FC} (F_{\text{split}, i}) + \text{FC} (F_{\text{split}, i}))$$
$$F_{\text{refined}, i} = \text{FC} (\text{GELU}(y_{i})) + F_{\text{split}, i}$$
이 과정에서 각 스케일의 특징 맵은 글로벌 정보와 로컬 정보가 조화롭게 결합된 상태로 재구성됩니다.
STEP4. Iterative Feature Refinement
마지막 단계는 위의 STEP2와 STEP3을 여러 번 반복 수행하여(반복 횟수 $d$) , 특징 맵을 지속적으로 정제(refine)하고 향상시키는 과정입니다. 반복을 통해 특징은 더욱 더 구별 가능한(discriminative) 상태가 되어 최종적으로 정확한 픽셀 단위의 이미지 분할을 가능하게 합니다.
Experiment Results
1) Dataset Description
본 논문에서는 MISSFormer의 성능을 검증하기 위해 세 가지 의료 이미지 분할 데이터셋을 활용하였습니다.
- Synapse Dataset (다중 장기 분할): 30장의 복부 CT 이미지로 구성되었으며, 비장, 신장, 간 등 총 8개의 복부 장기를 분할합니다. 훈련 데이터 18장, 테스트 데이터 12장으로 구성되었고, 슬라이스 크기는 512×512입니다.
- ACDC Dataset (심장 분할): 100명의 환자로부터 얻은 심장 MRI 이미지로 구성되어 있으며, 좌심실(LV), 우심실(RV), 심근(MYO)의 세 영역을 분할합니다. 훈련 70명, 테스트 30명으로 구성되었으며, 슬라이스 크기는 224×224입니다.
- DRIVE Dataset (망막 혈관 분할): 당뇨병성 망막 질환 진단을 위한 망막 이미지 40장으로 구성되었고, 혈관 영역을 분할합니다. 훈련 데이터 20장, 테스트 데이터 20장으로 구성되었으며, 슬라이스 크기는 512×512입니다.
2) Implementation Details
모든 실험에서 이미지 크기는 각 데이터셋에 맞추어 조정되었으며, 데이터 증강(Data augmentation)은 랜덤 플립(random flip), 회전(rotation), 그리고 랜덤 크롭(random crop)을 사용했습니다. 손실 함수로는 픽셀 단위의 정확한 분할을 위해 Dice Loss와 Cross-Entropy Loss를 결합한 형태를 사용했습니다. SGD optimizer(momentum 0.9)를 사용하였고, 초기 학습률(learning rate)은 $0.05$ 로 설정되었습니다. 학습률 스케줄링은 poly learning rate decay 방식을 사용하여 훈련 동안 점진적으로 학습률을 감소시켰습니다. 모든 모델은 약 400 epoch 동안 학습되었으며, 최적 성능을 위해 가장 성능이 우수한 체크포인트를 최종 평가에 활용했습니다.
3) Ablation Studies
3-1) Architecture Selection

위 표는 Synapse(다중 장기 분할)와 ACDC(심장 분할) 데이터셋에서 기존 Transformer 기반 모델들의 성능을 나타낸 결과입니다.
- Synapse 데이터셋에서 가장 높은 DSC 점수는 U-SegFormer_B1이 76.10으로 가장 우수했고, HD는 SegFormer_B5가 21.62로 가장 우수했습니다.
- ACDC 데이터셋에서는 SegFormer_B5가 89.34로 가장 높은 DSC 성능을 보였습니다.
이를 통해 기존 모델 중에서는 Synapse에서는 U자형 Transformer 구조(U-SegFormer)가 더 좋은 성능을, ACDC에서는 SegFormer의 깊은 구조(SegFormer_B5)가 우수한 성능을 보인다는 것을 확인할 수 있습니다.
3-2) Ablation Studies on ReMix-FFN
본 실험에서는 ReMix-FFN 모듈의 효과를 명확하게 확인하기 위해 기존 모델들과의 성능 및 수렴 특성을 비교 분석하였습니다. 그 결과는 다음과 같습니다.

- ReMix-FFN을 활용한 MISSFormer_S는 Synapse 데이터셋에서 가장 높은 DSC (79.73)와 가장 낮은 HD (20.14)를 보였으며, ACDC 데이터셋에서도 DSC (90.61)가 가장 높았습니다.
- 기존 모델 대비 Skip connection과 Layer Normalization(LN)을 결합한 구조가 더욱 우수한 성능을 가져왔습니다.

- MISSFormer_S (ReMix-FFN 사용)는 U-mlpFormer, U-SegFormer에 비해 모든 층(layer 1, 3, 6, 7)에서 그래디언트 노름(Gradient Norm)이 현저히 낮았습니다.
- 이는 ReMix-FFN이 보다 효율적이고 안정적인 학습을 가능하게 하며, 모델의 훈련 안정성을 높임을 의미합니다.
- 전체적인 손실(loss)의 감소 속도와 최종 손실 값에서 ReMix-FFN이 기존의 MLP 및 Mix-FFN 모델보다 우수한 성능을 나타냈습니다.
- Dice Similarity Coefficient(DSC)의 수렴 속도와 최종 값 또한 ReMix-FFN이 가장 우수한 성능을 보였습니다.
3-3) Comparison of Different Local Modules in Transformers

본 실험은 Transformer 블록 내에 서로 다른 로컬(Local) 모듈을 사용한 모델들과 MISSFormer의 성능을 비교하기 위해 진행되었습니다. 성능 지표로는 DSC(높을수록 좋음)와 HD(낮을수록 좋음)를 사용하였으며, 결과는 다음과 같습니다.
- Synapse 데이터셋에서 MISSFormer_S가 DSC는 79.73으로 가장 높고, HD는 20.14로 가장 낮아 다른 모든 모델(U-mlpFormer, U-SegFormer, U-LocalViT)보다 우수한 성능을 보였습니다.
- ACDC 데이터셋에서 MISSFormer_S가 90.61의 DSC를 기록하며 다른 모델들보다 명확히 높은 성능을 나타냈습니다.
이러한 결과는 Transformer 블록 내에서 ReMix-FFN 모듈이 기존의 다양한 로컬 모듈(MLP, Mix-FFN, LocalViT)에 비해 글로벌과 로컬 정보를 더 효과적으로 통합하여, 의료 이미지 분할에서의 성능을 크게 향상시켰음을 보여줍니다.
3-4) Comparison of Different Local Modules in Transformers
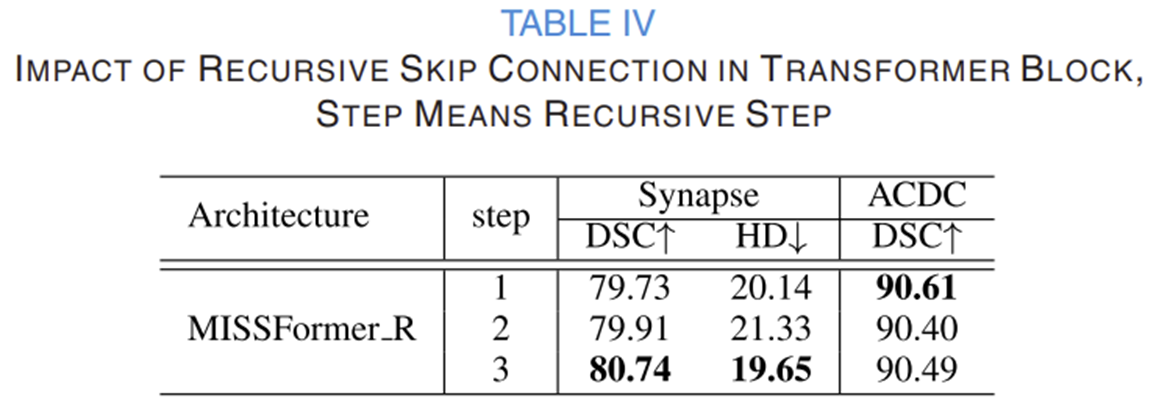
이 실험은 Transformer 블록에서 재귀적 스킵 연결(Recursive Skip Connection) 단계 수가 모델의 성능에 미치는 영향을 평가하기 위해 수행되었습니다. 주요 결과는 다음과 같습니다.
- Synapse 데이터셋에서 Recursive step이 증가할수록 성능이 지속적으로 향상되었으며, 특히 step이 3일 때 DSC는 80.74로 가장 높고, HD는 19.65로 가장 낮아 최적의 성능을 기록했습니다.
- ACDC 데이터셋에서 Recursive step이 1일 때 DSC가 90.61로 가장 좋았고, step이 증가할수록 성능이 다소 감소하는 경향을 보였습니다.
결론적으로, Recursive Skip Connection의 단계적 활용은 Synapse 데이터셋에서 특징의 재분배와 학습 효율성 증가를 통해 성능을 개선했지만, ACDC 데이터셋에서는 오히려 과적합의 가능성을 나타내며 최적 성능을 위한 적절한 Recursive step의 선택이 중요함을 보여줍니다.
3-5) Influence of ReMixed Transformer Context Bridge

이 실험에서는 MISSFormer 모델에서 ReMixed Transformer Context Bridge가 성능에 미치는 영향을 평가했습니다. 주요 결과는 다음과 같습니다.
- Synapse 데이터셋에서 Context Bridge가 추가된 MISSFormer는 DSC가 최대 81.96으로 증가했고, HD가 최소 18.20까지 감소하여 성능이 크게 개선되었습니다 (Table 5). 가장 우수한 결과는 depth=4, stage=(4/3/2/1) 구조로 구성된 경우였으며, DSC=81.96, HD=18.20을 기록했습니다 (Table 6).
- ACDC 데이터셋에서 Context Bridge 적용으로 DSC가 최대 90.98까지 증가하여 더욱 정확한 분할 성능을 나타냈습니다 (Table 5). depth=6, stage=(4/3/2/1) 구조일 때 DSC=91.19로 가장 높은 성능을 보였습니다 (Table 6).
결과적으로, ReMixed Transformer Context Bridge는 MISSFormer의 성능 향상에 필수적인 모듈이며, depth와 stage 구성에 따라 최적의 성능이 달라지므로 각 데이터셋의 특성에 맞게 구조를 조정할 필요가 있음을 확인할 수 있습니다.
3-6) The Necessity of Global-Local Information in Transformer Context Bridge

- Synapse 데이터셋에서 ReMix-FFN이 적용된 MISSFormer는 DSC가 81.96으로 가장 높았으며, mlp-FFN은 HD (17.26)가 가장 낮아 국지적인 정보만으로는 특정 부분에서 효과적일 수 있음을 보였습니다.
- ACDC 데이터셋에서 ReMix-FFN을 사용한 MISSFormer가 DSC 91.19로 모든 비교 모델 중 가장 뛰어난 성능을 보였습니다.
3-7) The Qualitative Analysis of Proposed Method

4) Results
4-1) Quantative Results



4-2) Qualtiative Results



Conclusion
본 논문에서는 의료 이미지 분할을 위해 Transformer 기반의 새로운 모델인 MISSFormer를 제안했습니다. 기존 Transformer 모델들은 글로벌 의존성은 잘 학습하지만 로컬 정보를 효과적으로 다루지 못한다는 한계점이 있었습니다. 이를 해결하기 위해 본 연구에서는 ReMix-FFN과 ReMixed Transformer Context Bridge라는 두 가지 핵심 모듈을 도입하여 글로벌 및 로컬 특징을 효과적으로 통합하였습니다.
실험을 통해 MISSFormer는 Synapse, ACDC, DRIVE 등 다양한 의료 데이터셋에서 기존 Transformer 기반 모델 대비 뛰어난 성능을 보였으며, 특히 ReMix-FFN 모듈은 모델의 수렴성, 안정성 및 정확도를 크게 향상시키는 것으로 확인되었습니다. 또한, ReMixed Transformer Context Bridge를 통해 멀티스케일 특징 간 글로벌-로컬 상관관계를 더욱 효과적으로 학습하여 일반화 성능을 개선하였습니다.
결론적으로, 본 논문에서 제안한 MISSFormer 모델은 글로벌 및 로컬 특징의 균형 잡힌 통합을 통해 의료 이미지 분할 분야의 성능을 한 단계 끌어올렸으며, 향후 다양한 의료 영상 분석 과제에서 더욱 폭넓게 활용될 수 있을 것으로 기대됩니다.
'Paper Review' 카테고리의 다른 글
| ThiNet: Pruning CNN Filters for a Tinner Net (IEEE TPAMI2018) (0) | 2025.04.08 |
|---|---|
| Deformable Convolutional Networks (ICCV2017) (0) | 2025.04.05 |
| Unet++: A Nested U-net Architecture for Medical Image Segmentation (DLMIA2018) (0) | 2025.04.01 |
| Multiscale Vision Transformers (ICCV2021) (0) | 2025.03.28 |
| Segmenter: Transformer for Semantic Segmentation (ICCV2021) (0) | 2025.03.25 |