안녕하세요. 지난 포스팅의 [IS2D] Rethinking Atrous Convolution for Semantic Segmentation (arxiv2017)에서는 Dilated Convolution을 활용한 DeepLabV3에 대해서 알아보았습니다. 오늘은 DeepLabV3와 유사하게 multi-branch 구조의 Pooling 모듈을 제안한 Pyramid Scene Pooling Network (PSPNet)에 대해서 알아보도록 하겠습니다.
Background
기본적으로 Semantic Segmentation은 영상 내의 각 픽셀에서 classification을 수행하는 dense prediction task라고 볼 수 있습니다. 이 때 Scene Parsing이라고 부르는 것이 Semantic Segmentation을 기반으로 수행되며 이는 하나의 장면 내의 완전한 이해를 해줄 수 있도록 도와줄 수 있습니다. 예를 들어, 자동차와 사람이 어디있는지를 알 수 있다거나 거리를 예측하여 자동차와의 차간 거리를 계산하는 등의 작업을 할 수 있는 것이죠.

하지만 Semantic Segmentation에서 가장 어려운 점은 Scene과 Label의 다양성입니다. 그림 1에서 보여주는 것과 위의 그림은 실외이고 아래 그림은 실내 사진이죠. 이러한 다양한 Scene의 특성은 조명과 같은 외부 환경에 의해 성능이 크게 달라 질 수 있습니다. 뿐만 아니라 같은 사람이라고 하더라도 카메라에 멀리 떨어져있으면 굉장히 작게 보입니다. 하지만 가까이 있으면 크게 보이죠. 이러한 label의 다양성 역시 성능을 방해하는 주요 요인입니다.
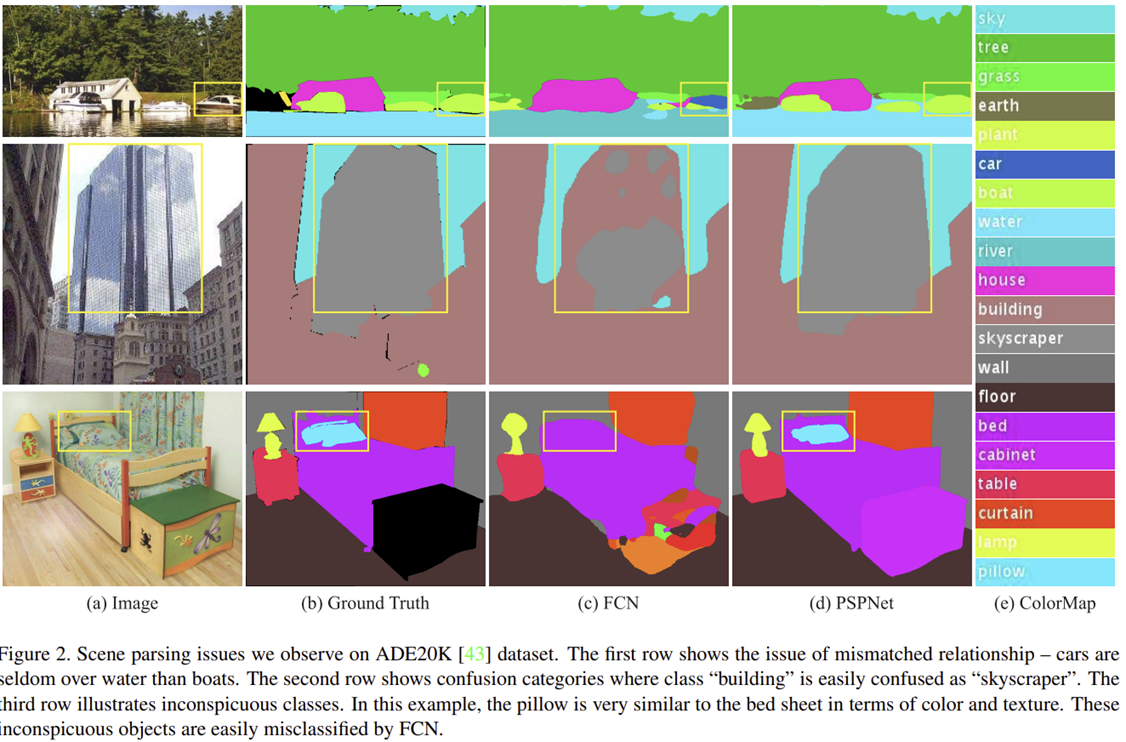
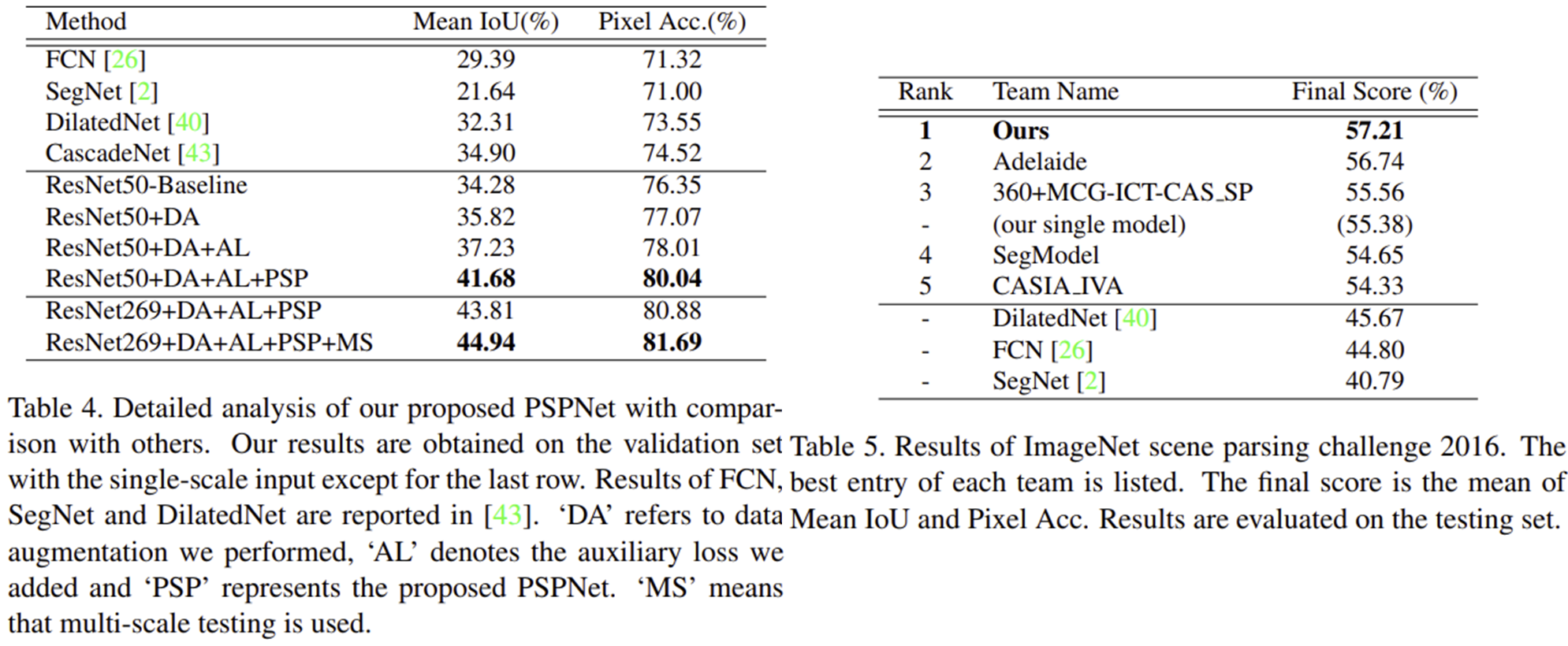
특히, Semantic Segmentation에서는 FCN (CVPR2015)을 시작으로 심층신경망을 활용하게 되었습니다. 이는 모델의 object understanding을 한 단계 상승시키는 결과를 얻었죠. 하지만 여전히 그림 2에서 보여주는 것과 같이 scene과 label 다양성 문제를 해결하지는 못했습니다. 하지만 오늘 소개하는 PSPNet에는 이러한 단점을 어느정도 보완하여 FCN에 비해 강건하게 객체들을 분할할 수 있습니다.
Pyramid Pooling Module
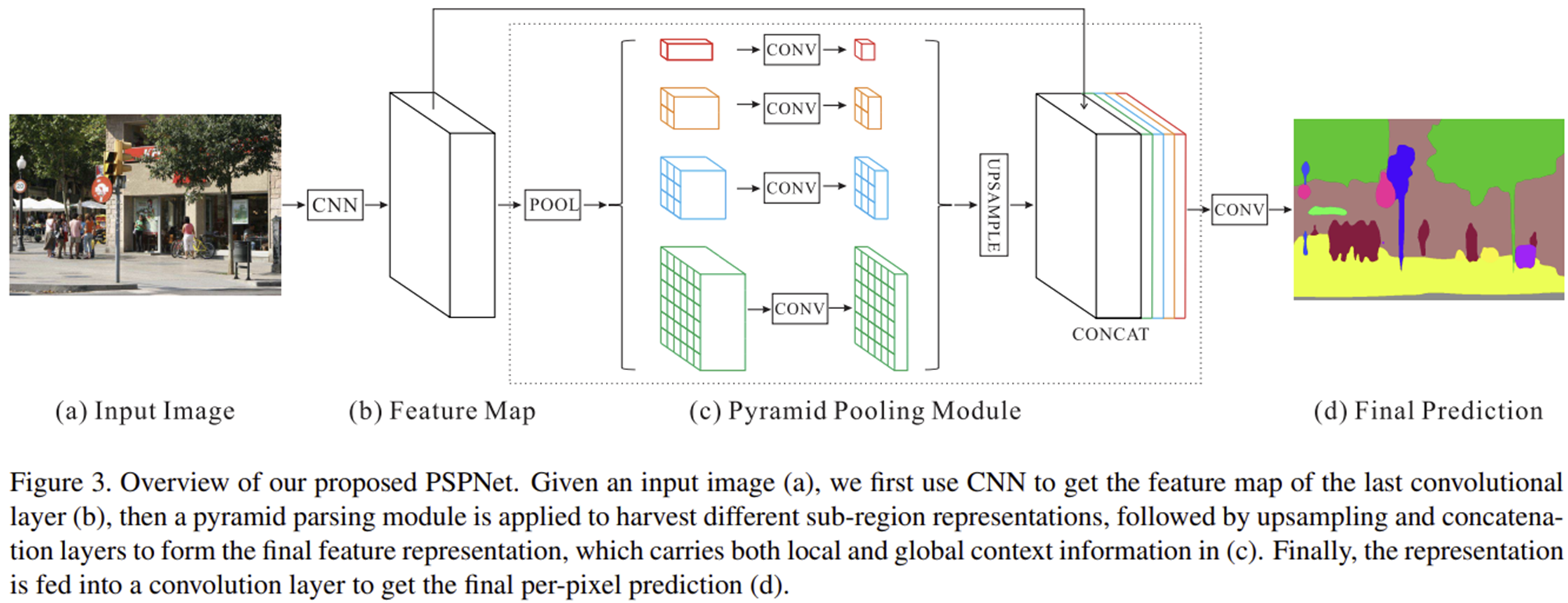
사실 모델 자체는 굉장히 단순합니다. DeepLabV3 보다도 쉬우니 쉽게 이해하실 수 있습니다. 그림 3은 PSPNet의 전체적인 블록 다이어그램을 보여주고 있습니다. 총 3단계로 구성되어 있습니다.
1) 입력 영상을 CNN에 입력하여 feature map 추출
2) 추출된 feature map에 4개의 서로 다른 pooling rate ($1 \times 1, 2 \times 2, 3 \times 3, 6 \times 6$)를 적용하여 다양한 크기의 descriptor 생성
3) $1 \times 1$ 합성곱을 통해 각 descriptor의 채널 개수를 줄여줌
4) 기존의 feature map과 각 descriptor들을 하나로 concatenate 하여 합성곱을 적용하여 final prediction 생성
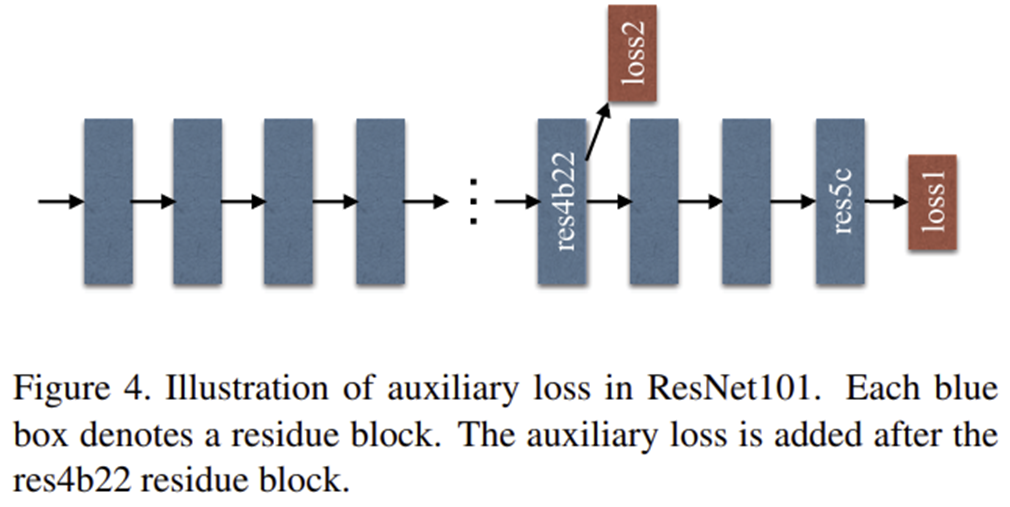
이때 PSPNet에서는 그림 4와 같이 auxiliary feature를 도입하여 "res4b22"에서 loss를 한번 더 뽑아 deep supervision을 개념도 함께 적용하였습니다.
Experimental Results