
안녕하세요. 지난 포스팅의 [IS2D] DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (IEEE TPAMI2017)에서는 DeepLabV2에 대해서 알아보았습니다. 오늘은 이어서 DeepLabV3에 대해서 짧게 알아보도록 하겠습니다.
Background
기본적으로 DeepLabV3 역시 DeepLabV1과 DeepLabV2와 마찬가지로 동일한 challenge를 공유합니다. 이 부분은 지난 포스팅을 참고해주시면 감사하겠습니다. 하지만, 점점 심층 신경망이 발달함에 따라서 예측 결과의 후처리 필요성에 대한 문제점이 대두되었습니다. DeepLabV2까지 사용하던 Fully Connected CRF는 전체 픽셀간 관계성을 기반으로 알고리즘이 수행되기 때문에 생각보다 많은 연산량이 필요합니다. 이러한 문제를 해결하기 위해 DeepLabV3에서는 후처리 과정을 아예 빼기로 결정합니다. 대신 ASPP 모듈을 약간 손보게 됩니다. 오늘은 이 부분을 중점적으로 보도록 하겠습니다.
Methods
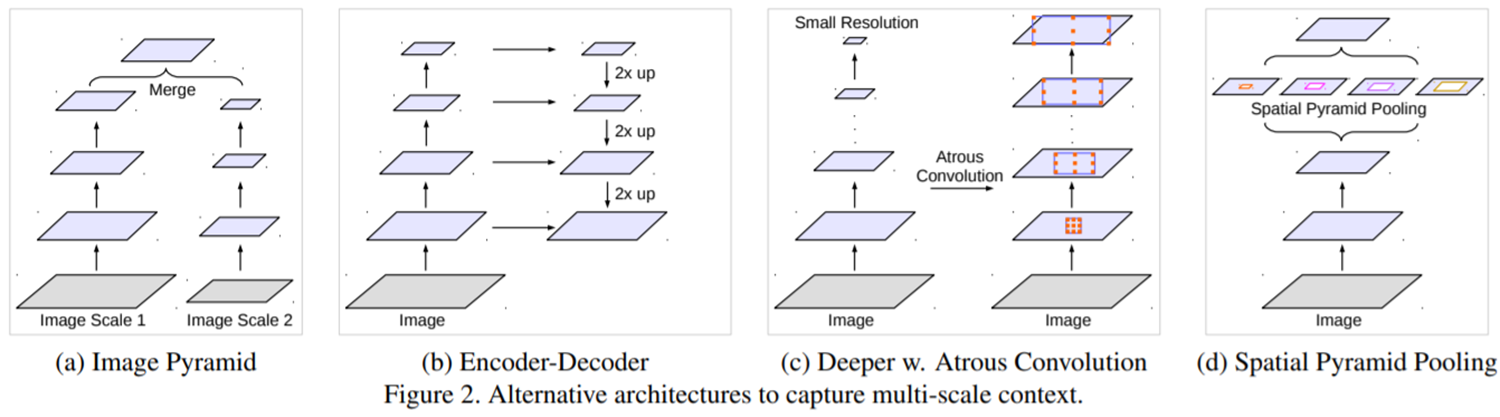
그림 2는 Multi-Scale 정보를 추출할 수 있는 4가지 방식에 대해서 설명하고 있습니다. (a)는 input level에서 서로 다른 크기의 영상을 입력하여 하나로 합칩니다. 영상 내 특징 추출의 유명한 알고리즘 중 하나인 SIFT에서도 이러한 방식을 사용합니다. (b)는 UNet 기반 심층 신경망 구조에서 자주 활용되는 encoder-decoder 구조입니다. (c)와 (d)는 DeepLabV1과 DeepLabV2에서도 이용되었던 Atrous Convolution을 사용하는 것을 볼 수 있습니다. 다만, (c)는 cascade 방식으로 단계적으로 atrous convolution의 dilation을 점차 늘리는 방식입니다. 반면에 (d)는 parallel 방식으로 가장 깊은 단계에서 서로 다른 크기의 dilation을 가지는 atrous convolution을 적용한 뒤 하나로 합치는 방식입니다. atrous convolution에 대한 자세한 내용은 지난 포스팅을 참고해주시면 감사하겠습니다.
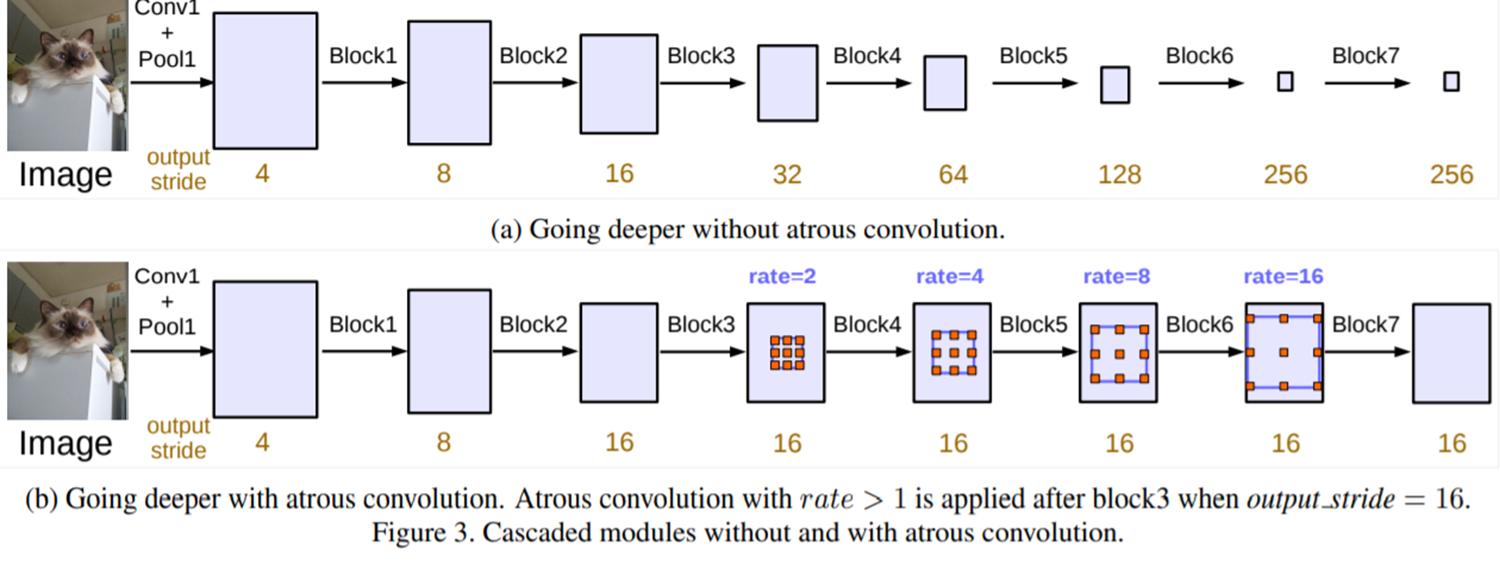
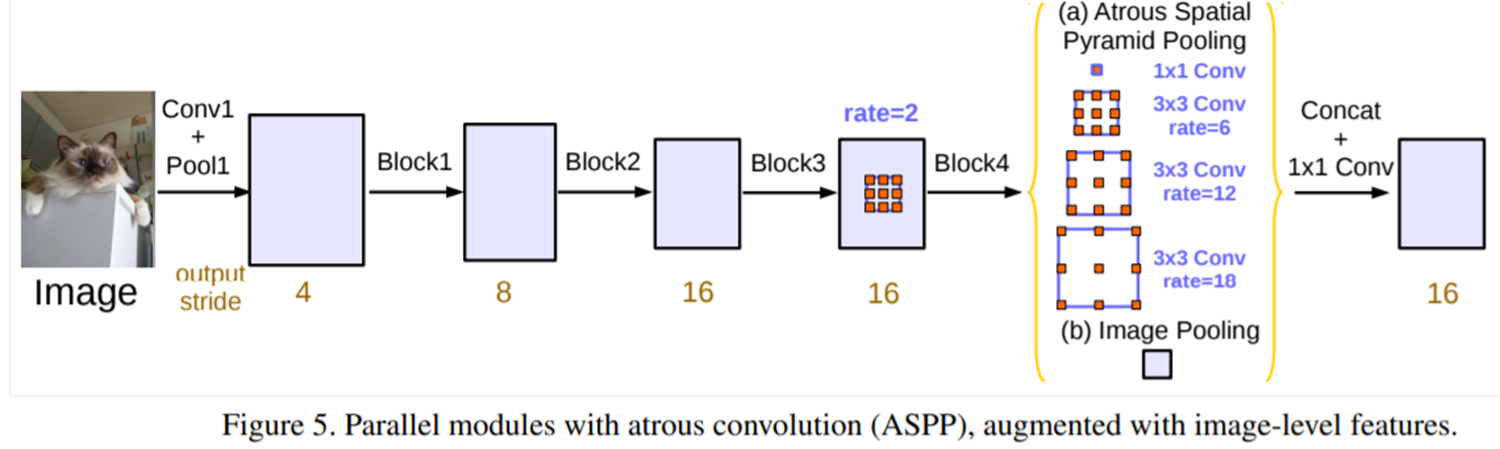
따라서, 저자들은 그림 3과 같이 cascade한 방식과 그림 5와 같이 parallel한 방식을 각각 고려해줍니다. 이때, DeepLabV3에서는 앞으로 대부분의 segmentation 논문에서 사용되는 용어인 output stride라는 개념에 대해서 언급합니다. 이는 현재 특징맵이 입력 영상에 비해 몇 배나 작은지를 의미합니다. 예를 들어, 입력 영상의 가로세로 길이가 256이고 첫번째 단계에서 특징맵의 크기가 64로 줄어들었으면 $\frac{256}{64} = 4$이므로 output stride는 4가 됩니다.
output stride는 결국 입력 영상에 비해 특징 맵이 얼마나 작아졌는 지를 수치화할 수 있는 방법이라고 볼 수 있습니다. 이는 output stride가 클수록 그만큼 입력 영상에 비해 특징 맵이 굉장히 작아졌다는 것을 의미하며 다시 upsampling을 수행 시 훨씬 많은 정보손실을 피할 수 없다는 것으로 결론을 내릴 수 없습니다. 하지만, 너무 작은 output stride는 연산량의 overhead가 심해질 수도 있기 때문에 어느정도 적절한 균형이 필요하겠죠.

본 논문에서는 표 1과 같이 실험적으로 segmentation에서는 output stride가 8인 경우와 16인 경우가 가장 적절했음을 밝혀내게 됩니다.
Experiment Results
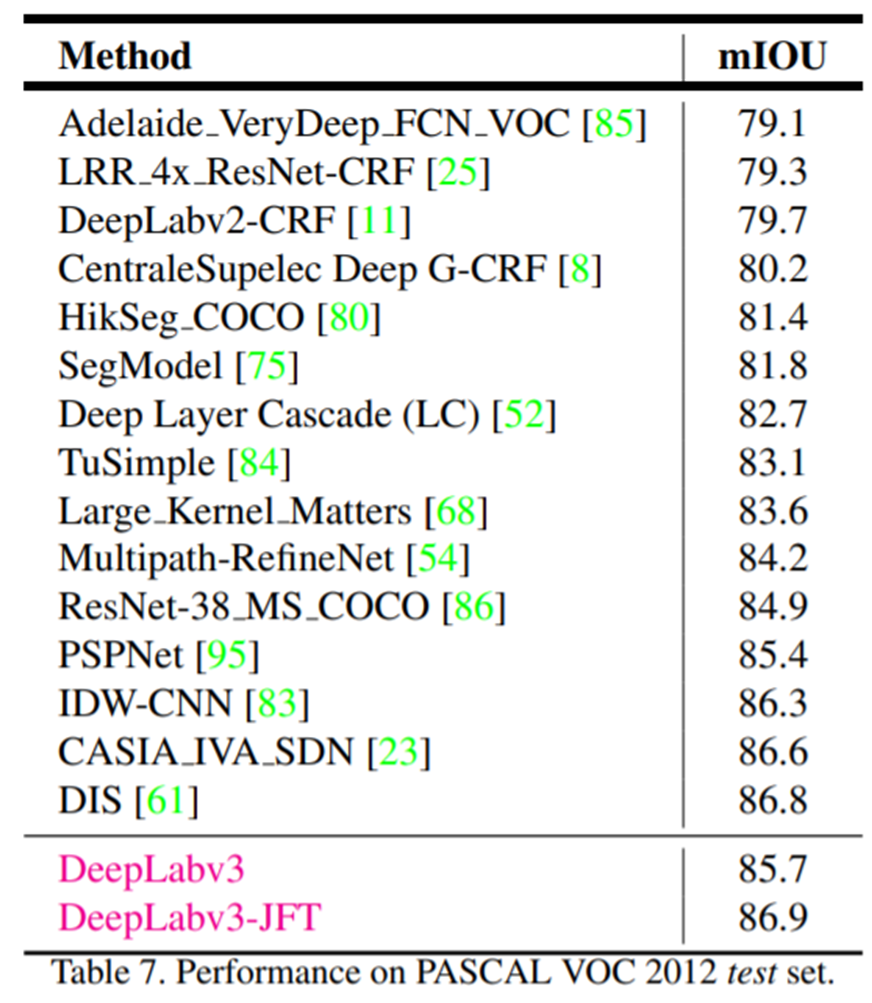
표 7은 state-of-the-art 방식들과 DeepLabV3 사이의 성능 비교를 보여주고 있습니다. 여기서 JFT라고 붙은 거는 JFT로 pre-trained된 backbone 모델을 사용했다는 것을 의미합니다. 참고로 해당 논문 역시 구글에서 냈기 때문에 저희는 JFT를 사용할 수 없습니다.
