
안녕하세요. 지난 포스팅의 [IS2D] SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (IEEE TPAMI2017)에서는 고차원 특징맵을 다시 복원할 때 발생하는 연산량 및 파라미터를 감소시키기 위해 인코딩 시 수행했던 Max Pooling의 인덱스를 저장하여 디코딩 때 활용하는 SegNet에 대해서 알아보았습니다. 오늘은 영상 분할 관련 논문에서 굉장히 유명한 모델 중 하나인 DeepLabV3+의 근본 모델인 DeepLabV1에 대해서 알아보도록 하겠습니다. 이 논문은 GoogLeNet과 같이 이유 Inception 시리즈 논문이 나오는 시작 논문이라고 보시면 될 거 같습니다.
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Deep Convolutional Neural Networks (DCNNs) have recently shown state of the art performance in high level vision tasks, such as image classification and object detection. This work brings together methods from DCNNs and probabilistic graphical models for a
arxiv.org
Background
심층 학습을 활용한 영상 분할 (Image Segmentation)은 문제점이 존재합니다. 가장 먼저 입력 영상에 대한 반복적인 풀링 연산으로 인해 영상의 해상도가 낮아지고 이는 영상에 존재하는 중요한 특징들에 대한 손실을 야기할 수 있습니다. 두번째 문제는 CNN이 동일 객체를 중심으로 분할하기 위해서는 공간 변환에 대한 불변성을 확보해야합니다. 본 논문에서는 반복적인 정보 손실을 Atrous Convolution (Hole Convolution)이라는 연산을 통해 방지하고 DCNN의 객체 인지 능력을 보완하기 위해 기계학습 기반 분할 기법 중 하나인 Conditional Random Field (CRF)를 적용하여 후처리를 수행하게 됩니다. 기본적으로 이 포스팅은 심층 학습에 대한 내용을 주로 다루려고 하기 때문에 CRF는 이후 영상 처리 관련 포스팅을 참조해주시길 바랍니다.
Methology
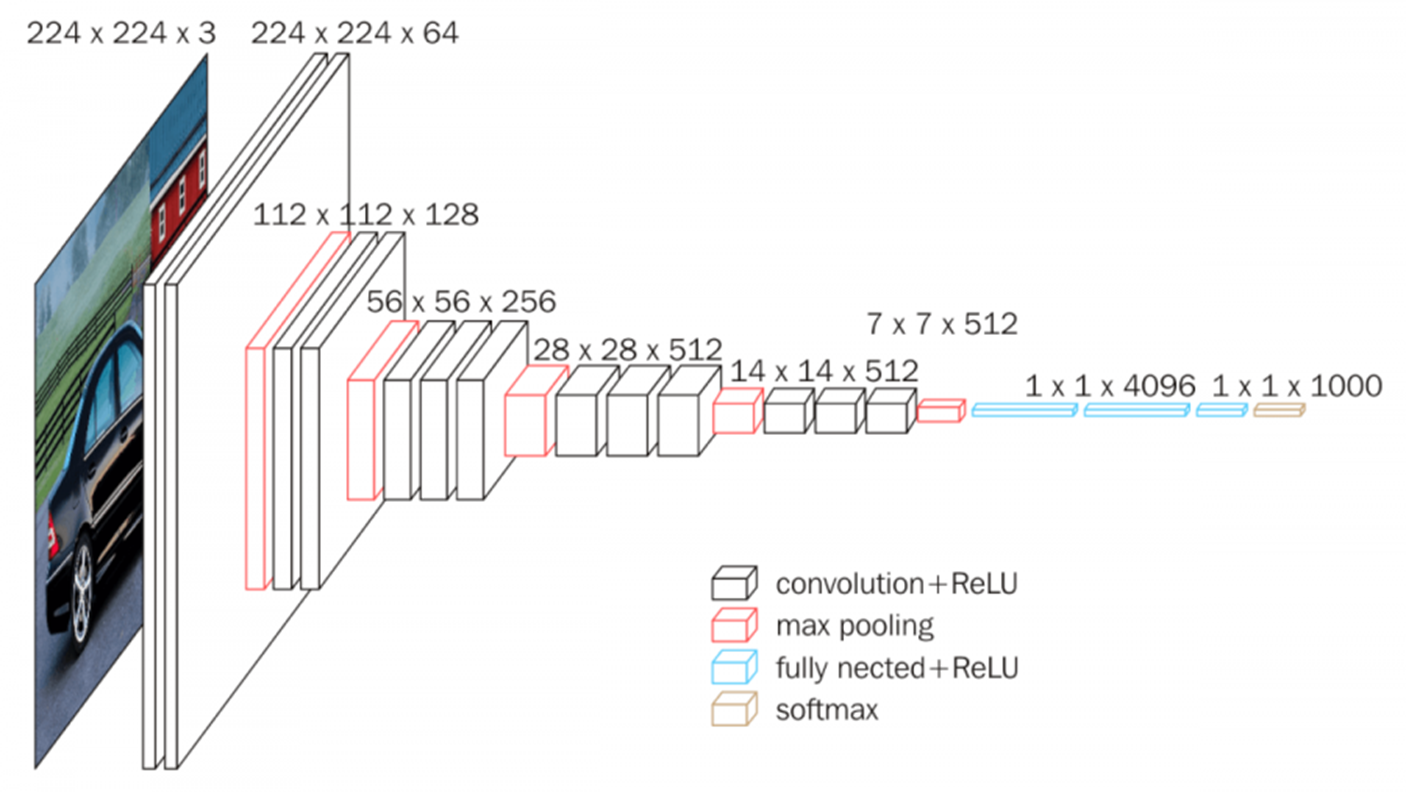
본 논문에서 제안한 DeepLabV1은 기본적으로 위 그림과 같 VGG16의 모든 계층을 합성곱 연산으로 변환한 모델을 사용합니다. 원래는 특징 맵을 추출하기 위한 feature extractor와 feature map으로부터 최종 예측을 수행하기 위한 Fully-Connected Layer (FCL)로 구성되어 있습니다. 하지만, FCL은 연산량과 파라미터가 너무 많기 때문에 이와 같은 변환과정으로 해주면 어느정도 감소할 수 있습니다. 또한, 저희는 영상 분할을 목표로 하기 때문에 FCL에 입력하기 위해 수행하는 Flatten은 정작 잘 추출한 특징맵의 중요한 공간 정보가 손실되는 것을 방지해야합니다.
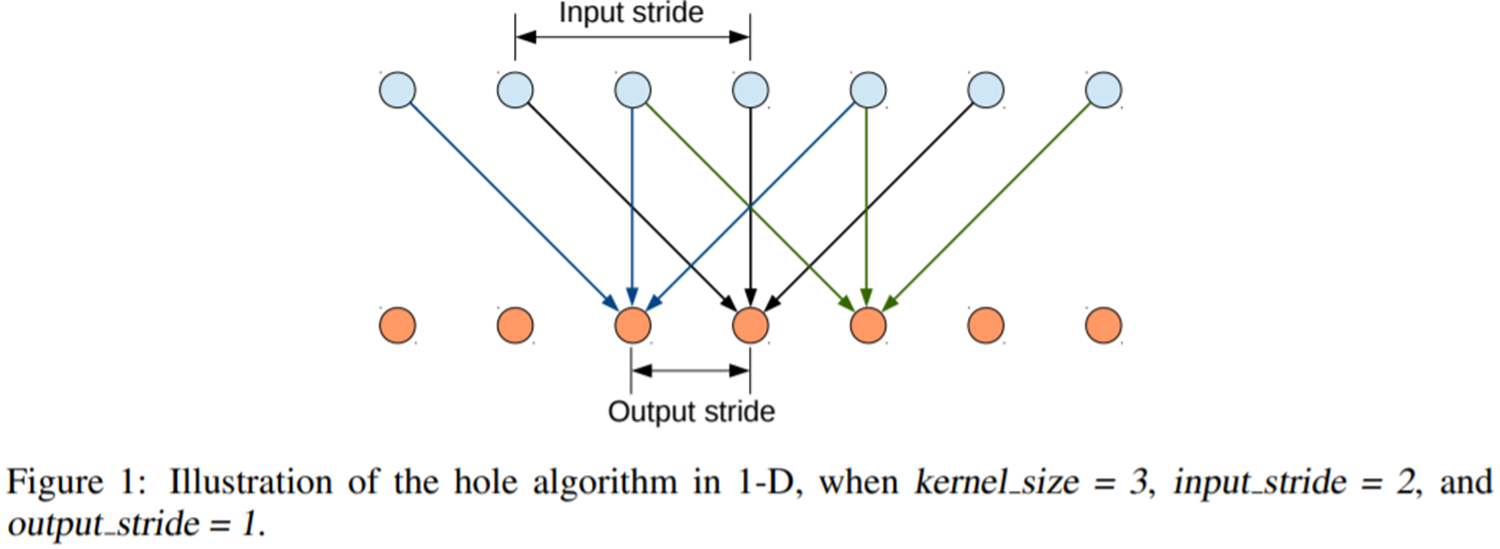
다음으로 가장 중요한 것은 DeepLabV1에 있는 합성곱 연산을 Standard Convolution에서 Atrous Convolution으로 바꾸어줍니다. Atrous Convolution을 가장 쉽게 이해하기 위해 그림 1을 보겠습니다. 일반적으로 합성곱 연산은 한 개의 출력 노드를 얻기 위해 연속된 노드를 활용하게 됩니다. 하지만, Atrous Convolution은 연속된 노드가 아닌 한 칸씩 더 띄워서 입력 노드를 활용하고 있습니다. 이때, 얼마나 띄워서 입력 노드를 선택할 지에 대한 파라미터가 PyTorch 기준으로 dilation $d$이 됩니다. 위 경우에는 $d = 2$가 되겠네요.

이를 2D로 표현하면 더욱 직관적으로 이해할 수 있습니다. 출력 특징 맵의 단일 픽셀 값을 얻기 위해 Atrous (= Hole)을 만들어 가중치를 구성하는 것을 볼 수 있습니다.
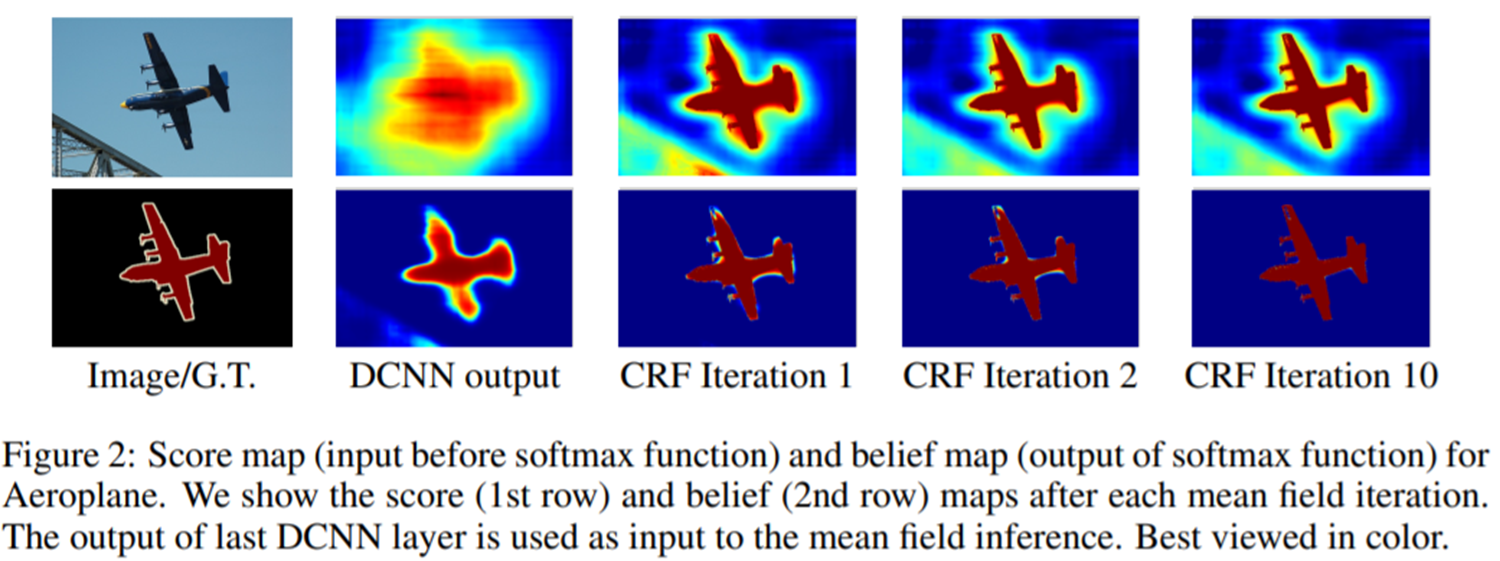
이렇게 특징 맵들을 추출하고 난 뒤 줄어든 해상도를 bilinear interpolation을 통해 입력 영상과 동일하게 맞추어준 뒤 CRF를 적용하여 후처리까지 해주면 됩니다.
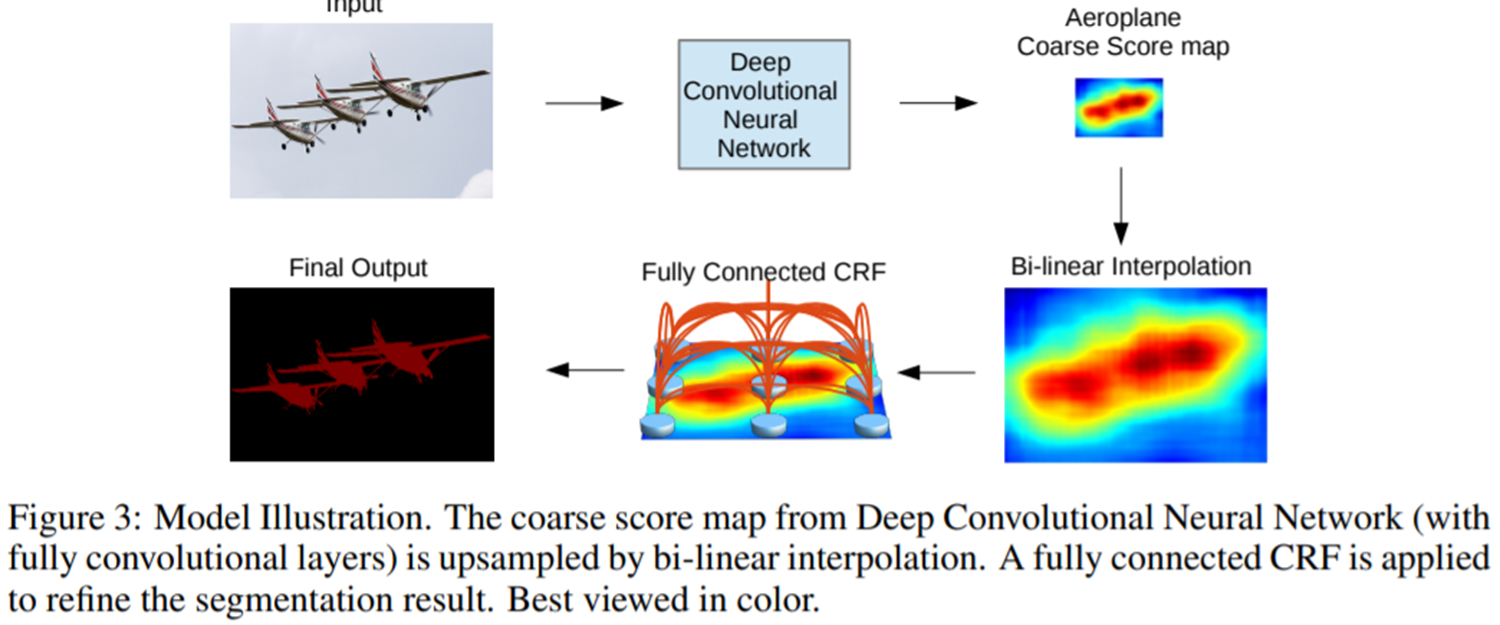
전체 과정을 정리하면 그림 3과 같습니다.
Experiment Results
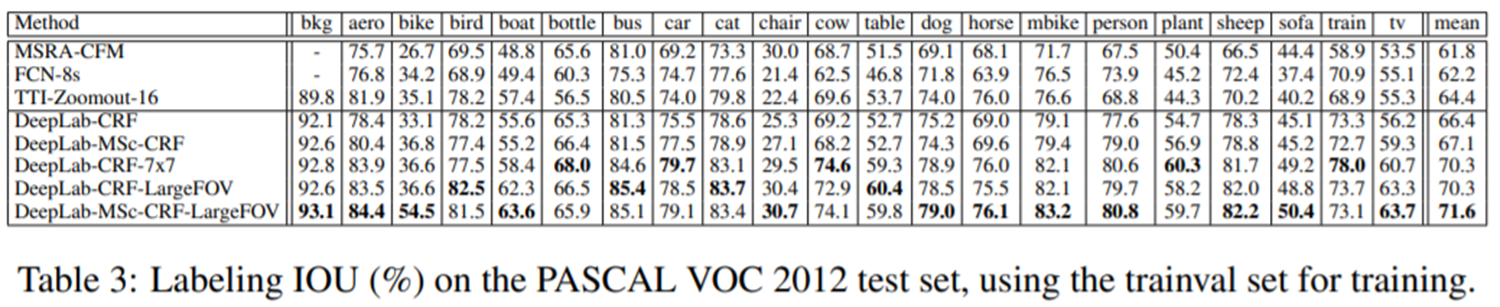
DeepLabV1은 출판된 지 굉장히 오래된 논문이기 때문에 비교할만한 대상이 그리 많지는 않았습니다. 대표적으로 FCN과 비교했을 때 모든 클래스에 대해 굉장히 높은 성능을 얻을 수 있었습니다.

그림 6은 Qualitative results를 요약하고 있습니다. 기존의 방법들보다 훨씬 디테일이 살아있는 것을 볼 수 있습니다.