
안녕하세요. 지난 포스팅의 [IS2D] U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI2016)에서는 현재 수많은 영상 분할 영상의 기초가 되는 UNet에 대해서 알아보았습니다. 오늘은 이를 좀 더 효율적으로 구현한 SegNet에 대해서 소개해드리도록 하겠습니다.
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a
arxiv.org
Background
현재, 수많은 컴퓨터 비전 작업 (영상 분류, 음성 분류, 객체 감지 등)에서 심층 신경망을 적극적으로 활용하고 있습니다. 특히, CNN 기반의 모델에서는 합성곱을 적용한 뒤 특징 맵의 크기를 줄이기 위해 풀링 연산을 적용하게 됩니다. 이러한, 연산 방식은 영상 분할과 같이 픽셀 단위로 예측을 해야하는 경우에 성능을 낮춘다는 문제점이 있습니다. 이때, 다시 업-샘플링을 하기 위해 Transposed Convolution을 쓰거나 다양한 보간법을 적용하게 됩니다. 이는 중요한 특징 정보가 사라진 상황에서 적용하는 것이기 때문에 오히려 방해가 된다는 것이죠. 본 논문에서는 이러한 문제점을 지적하고 효율적으로 의미론적 영상 분할을 수행할 수 있는 SegNet을 제안합니다.
SegNet Architecture
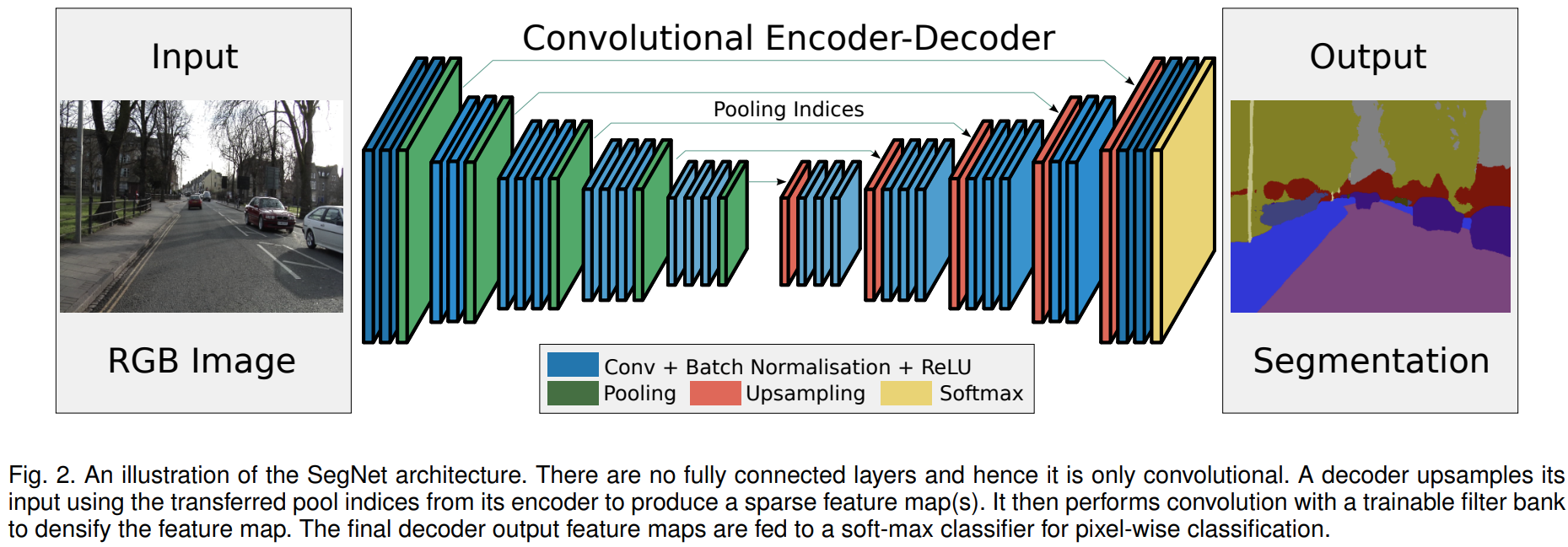
그림2는 SegNet 구조의 블록 다이어그램을 나타냅니다. 지난 포스팅의 UNet과 비교해보면 사실 큰 차이가 없다는 것을 알 수 있습니다. 실제로 인코더는 크게 다르지 않지만 핵심은 디코더에서 업샘플링을 수행하는 과정이 가장 큰 차이가 있습니다. 이 부분을 중점적으로 이해하시면 될 거 같습니다.
1) Encoder
SegNet의 인코더는 VGG16에서 사용한 완전 연결 계층 (fully-connected layer)를 제외한 13개의 합성곱 계층을 사용하였습니다. 일반적으로 파라미터가 많은 부분은 완전 연결 계층이기 때문에 파라미터의 개수가 굉장히 많이 줄어들게 됩니다 (134M $\rightarrow$ 14.7M). SegNet이 인코더-디코더 구조를 가지고 있기 때문에 인코더의 블록 개수와 디코더의 블록 개수가 동일해야합니다. 따라서, 디코더의 블록 개수 역시 13개의 합성곱 블록을 가지게 되죠.
각 인코더 블록은 $\text{Conv}_{3 \times 3} \rightarrow \text{BN} \rightarrow \text{ReLU} \rightarrow \text{MaxPool}_{2 \times 2, 2}$의 순서로 구성되어 있습니다. $\text{Conv}_{3 \times 3}$은 $3 \times 3$ 크기의 합성곱, $\text{BN}$은 배치 정규화 (Batch Normalization), $\text{ReLU}$는 Rectified Linear Unit, $\text{MaxPool}_{2 \times 2, 2}$는 $2 \times 2$ 크기의 필터로 stride를 2로 가지는 풀링 계층을 의미합니다. 이때, 풀링 계층은 입력 영상에서 약간의 이동 (translation)에 대한 불변성을 부여하기 위해 적용되는 연산입니다.
영상 분할에서 핵심은 바로 객체의 boundary를 얼마나 디테일하게 예측하느냐에 싸움입니다. 하지만, 풀링 연산은 필연적으로 이러한 디테일을 제거하기 때문에 성능 하락의 원인이 됩니다. 이때, SegNet에서는 삭제되는 boundary 정보를 저장하기 위해 sub-sampling 과정에서 max 값의 인덱스를 저장하는 방식을 선택하고 이를 디코딩 과정에서 활용하기로 합니다.
2). Decoder
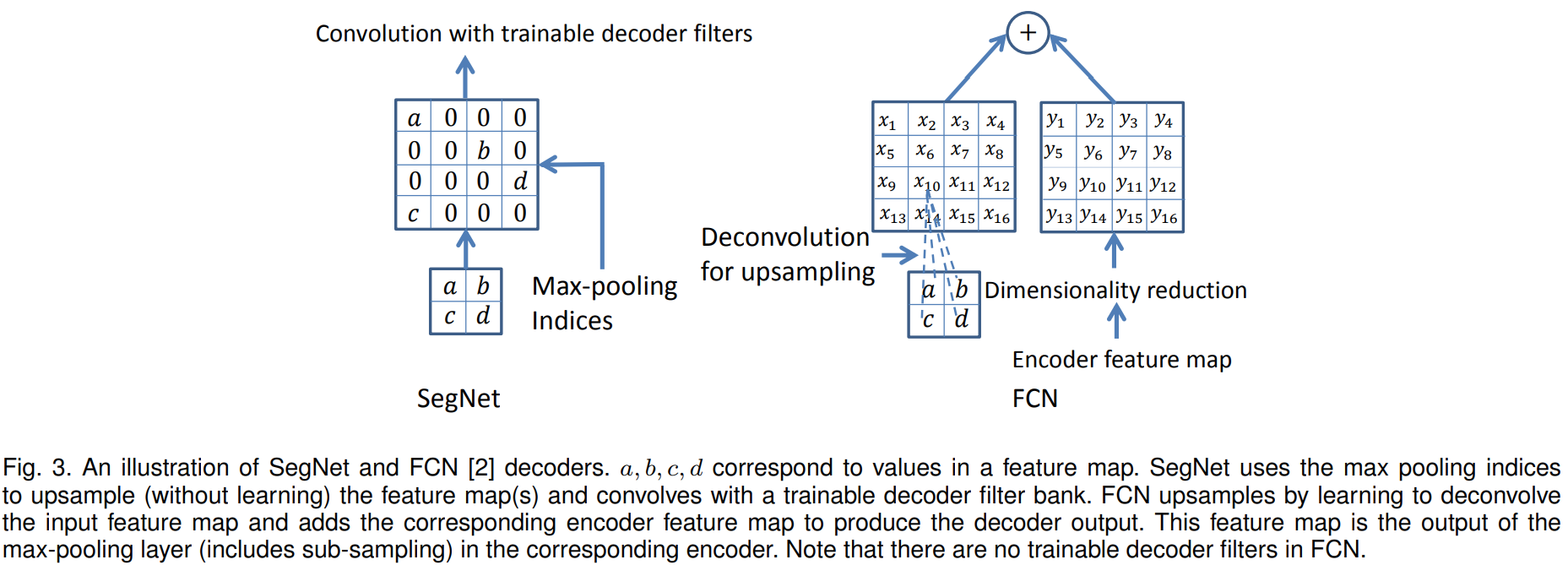
그림3의 왼쪽 그림은 SegNet의 디코딩 과정을 핵심적으로 보여주고 있습니다. 현재 수많은 영상 분할을 위한 모델들은 오른쪽 그림과 같이 FCN에서 사용한 Deconvolution 계층을 사용하고 있습니다. 하지만, SegNet에서는 이와는 완전히 다른 새로운 디코딩 방식을 제안합니다. 저희는 인코딩 과정에서 Maxpooing을 적용할 때 최대값의 위치정보를 저장하였습니다. 이제 디코딩 과정에서 최대값의 위치정보에 따라서 그대로 복사붙여넣기를 해주는 것이죠. 이때, 나머지 영역은 0으로 채우게 됩니다. 이런식의 디코딩의 가장 큰 장점은 추가적인 파라미터가 필요하지 않기 때문에 효율적이라는 것입니다. 실제로 제가 영상 분할 관련 논문을 썻을 때 SegNet은 굉장히 빠른축에 속하는 모델이였습니다. 본 논문에서는 이에 대한 정확한 비교를 위해 몇 가지 디코더 변형에 따른 다양한 모델을 구성하고 비교합니다.
- SegNet-Basic: $7 \times 7$ 크기의 필터를 사용한 4개의 인코더 + 4개의 디코더
- FCN-Basic: SegNet-Basic과 동일한 인코더와 디코더를 가지지만 디코딩 방식이 deconvolution 방식을 사용
- SegNet-Basic-SingleChannelDecoder: SegNet-Basic과 동일한 인코더와 디코더 구조 및 과정을 거침. 차이점은 depthwise convolution을 적용하여 1개의 필터가 1개의 특징 맵에 대한 연산을 하게 함으로써 연산량 및 파라미터의 개수를 줄이는 것이 목표
- FCN-Basic-NoAddition: FCN-Basic과 동일한 인코더와 디코더 구조 및 과정을 거침. 차이점은 skip connection을 제거
- Bilinear-Interpolation: FCN-Basic-NoAddition 구조에서 업-샘플링을 bilinear interpolation으로 변경
- SegNet-Basic-EncoderAddition: SegNet-Basic과 동일한 인코더와 디코더 구조 및 과정을 거침. 차이점은 skip connection을 추가하는 것인데 64개의 채널을 가져와서 디코더의 특징 맵과 더함
- FCN-Basic-NoDimReduction: 인코더의 차원축소 제거
3). Training
본 논문에서는 CamVid road scenes 데이터셋을 이용해서 다양한 디코더를 가지는 모델들을 비교합니다. CamVid는 상대적으로 작은 데이터셋으로 367개의 훈련 데이터, 233개의 시험 데이터로 $360 \times 480$ 크기의 해상도를 가지는 RGB 영상으로 이루어져 있습니다. 총 11개의 클래스를 포함하고 있습니다.
각 모델을 CamVid 데이터셋에 학습하기 위해 He 초기화를 사용하여 모델의 파라미터들을 초기화하였으며 stochastic gradient descent를 로 0.1의 학습률과 0.9의 모멘텀을 기반으로 파라미터들을 업데이트 하였습니다. 손실함수는 cross entropy를 사용하였으며 배치사이즈는 12로 고정하였습니다. 이때, 클래스 별로 하나의 영상에 포함된 비율이 다르기 때문에 median frequency balancing이라는 방법을 이용하여 손실함수를 계산할 때 클래스별 비율을 조절하여 학습을 진행하였습니다.
Experiment Results
1). Comparison of decoder variant
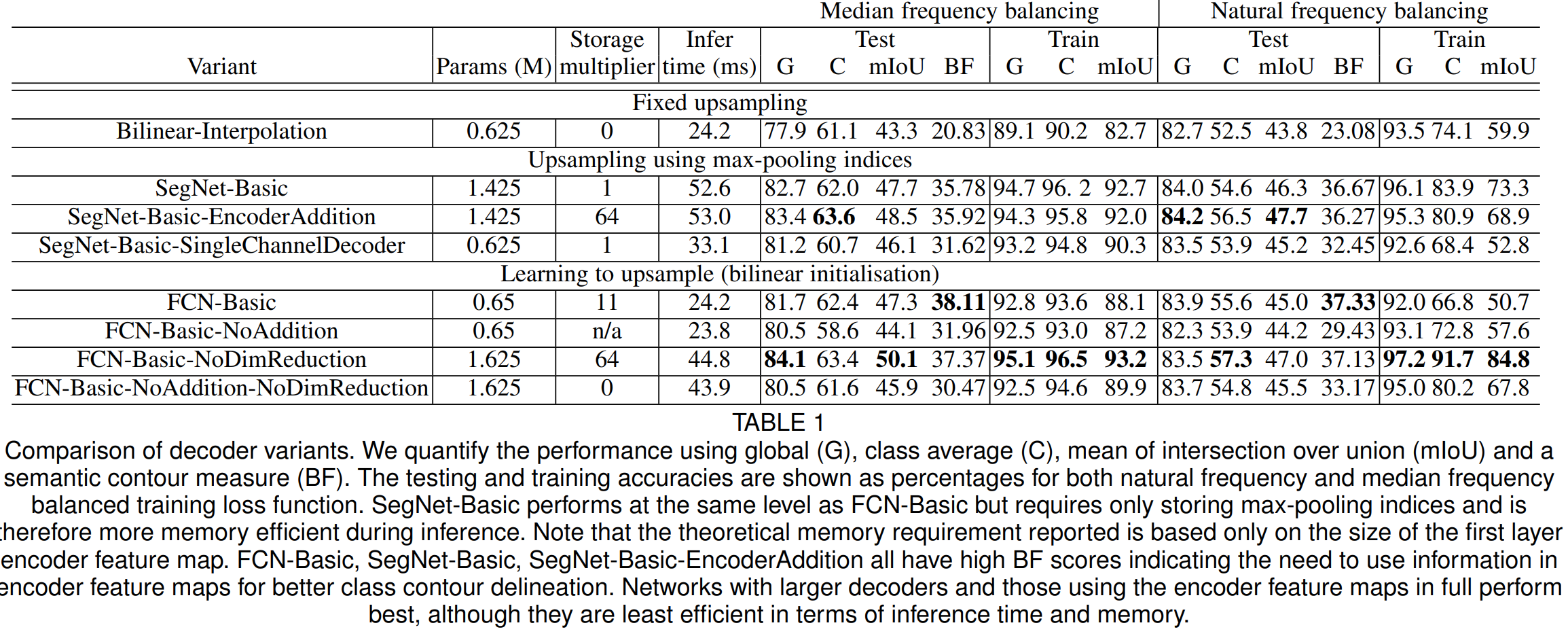
표1은 이전에 설명드린 다양한 디코더 변형에 따른 실험 결과를 보여주고 있습니다. 일단, 성능을 비교해보면 성능 자체는 FCN과 SegNet과 같은 학습 기반의 모델이 Bilinear-Interpolation보다 훨씬 좋다는 것을 알 수 있습니다. 이때, 메모리 사용량 (storage multiplier)는 FCN-Basic이 SegNet-Basic보다 약 11배 더 높은 것을 볼 수 있습니다.
2). Qualitative comparisons of traditional methods and SegNet
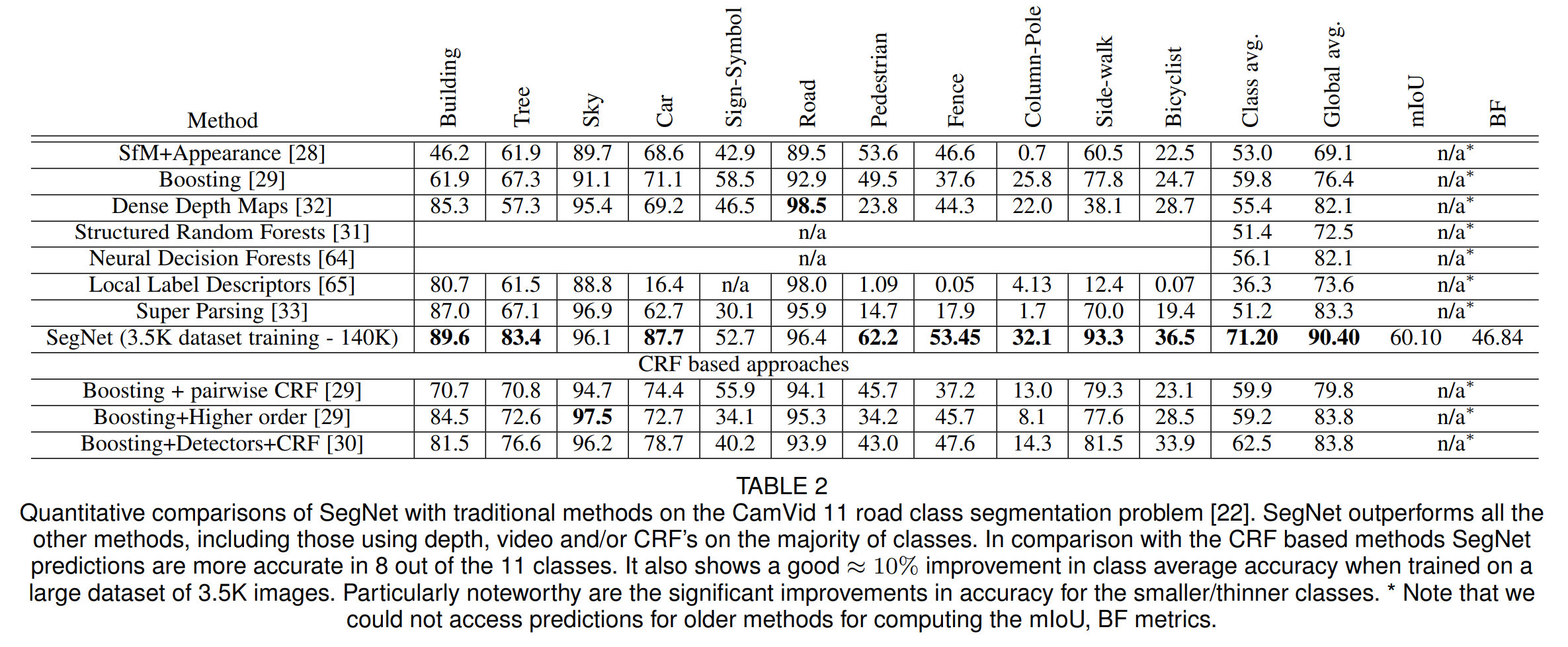
당연하지만, 전통적인 ML 기반의 방법보다 SegNet이 성능이 훨씬 좋다는 것을 보여주고 있습니다.
3). Qualitative comparisons of deep learning model and SegNet
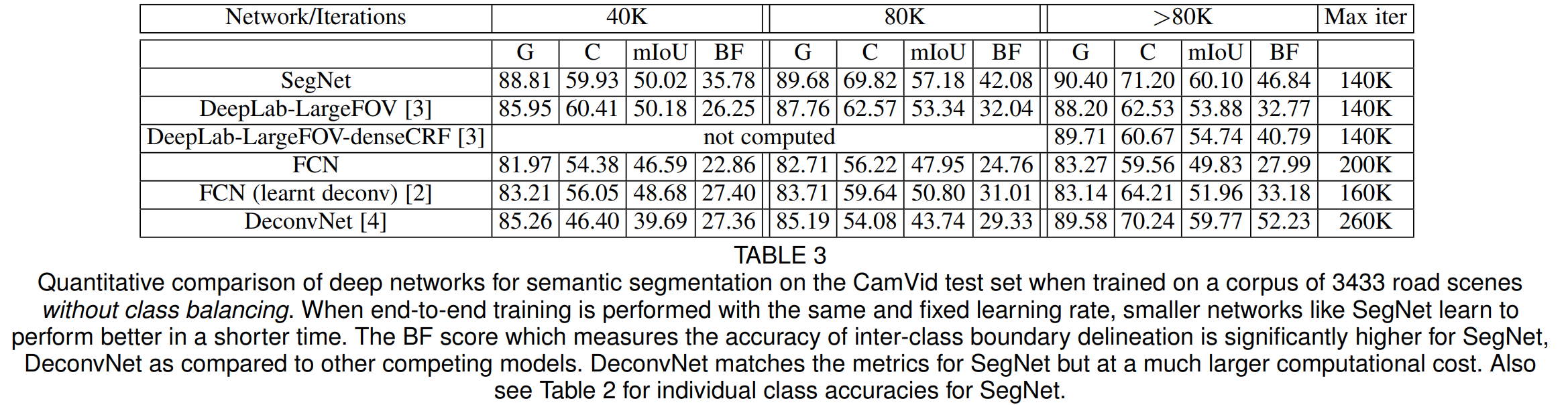
이번에는 다른 딥 러닝 모델들과 성능을 비교해봅니다. 성능이 가장 좋은 것을 볼 수 있습니다.
Implementation Code
import torch.nn as nn
import torch.nn.functional as F
class SegNet(nn.Module) :
def __init__(self, num_classes, n_init_features, drop_rate=0.5,
filter_config=(64, 128, 256, 512, 512)):
super(SegNet, self).__init__()
self.encoders = nn.ModuleList()
self.decoders = nn.ModuleList()
# setup number of conv-bn-relu blocks per module and number of filters
encoder_n_layers = (2, 2, 3, 3, 3)
decoder_n_layers = (3, 3, 3, 2, 1)
encoder_filter_config = (n_init_features, ) + filter_config
decoder_filter_config = filter_config[::-1] + (filter_config[0], )
for i in range(0, 5) :
# encoder architecture
self.encoders.append(_Encoder(encoder_filter_config[i],
encoder_filter_config[i+1],
encoder_n_layers[i], drop_rate))
# decoder architecture
self.decoders.append(_Decoder(decoder_filter_config[i],
decoder_filter_config[i+1],
decoder_n_layers[i], drop_rate))
# final classifier (equivalent to a fully connected layer)
self.classifier = nn.Conv2d(filter_config[0], num_classes, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
def forward(self, x, mode):
indices = []
unpool_sizes = []
feat = x
# encoder path, keep track of pooling indices and features size
for i in range(0, 5) :
(feat, ind), size = self.encoders[i](feat)
indices.append(ind)
unpool_sizes.append(size)
# decoder path, upsampling with corresponding indices and size
for i in range(0, 5) :
feat = self.decoders[i](feat, indices[4 - i], unpool_sizes[4 - i])
return self.classifier(feat)
def _calculate_criterion(self, criterion, y_pred, y_true, mode='train'):
loss = criterion(y_pred, y_true)
return loss
class _Encoder(nn.Module) :
def __init__(self, n_in_feat, n_out_feat,
n_block=2, drop_rate=0.5):
super(_Encoder, self).__init__()
layers = [nn.Conv2d(n_in_feat, n_out_feat, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(n_out_feat), nn.ReLU(inplace=True)]
if n_block > 1 :
layers += [nn.Conv2d(n_out_feat, n_out_feat, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(n_out_feat), nn.ReLU(inplace=True)]
if n_block == 3 :
layers += [nn.Dropout(drop_rate)]
self.features = nn.Sequential(*layers)
def forward(self, x):
output = self.features(x)
return F.max_pool2d(output, 2, 2, return_indices=True), output.size()
class _Decoder(nn.Module) :
def __init__(self, n_in_feat, n_out_feat,
n_block=2, drop_rate=0.5):
super(_Decoder, self).__init__()
layers = [nn.Conv2d(n_in_feat, n_out_feat, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(n_out_feat), nn.ReLU(inplace=True)]
if n_block > 1 :
layers += [nn.Conv2d(n_out_feat, n_out_feat, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(n_out_feat), nn.ReLU(inplace=True)]
if n_block == 3 :
layers += [nn.Dropout(drop_rate)]
self.features = nn.Sequential(*layers)
def forward(self, x, indices, size):
unpooled = F.max_unpool2d(x, indices, 2, 2, 0, size)
return self.features(unpooled)
if __name__=="__main__":
model = SegNet(num_classes=1, n_init_features=3)
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("number of trainable parameter : {}".format(total_params))
핵심은 _Decoder Class의 forward 메서드에서 max_unpool2d를 적용할 때, indices 인자를 받아서 업-샘플링을 수행하는 것 입니다.