
안녕하세요. 지난 포스팅의 [IC2D] Deep Networks with Stochastic Depth (ECCV2016)에서는 ResNet에서 Stochastic Depth를 적용하여 학습의 효율성과 정규화 효과까지 동시에 얻은 방법에 대해서 설명하였습니다. 지난 포스팅에서는 새로운 네트워크 구조에 대한 설명은 없었습니다. 오늘은 지난 포스팅의 [IC2D] Going Deeper with Convolutions (CVPR2015)에서 제안된 GoogLeNet에서 한 단계 더 발전된 구조인 InceptionNet-V2와 InceptionNet-V3에 대해서 소개해드리도록 하겠습니다.
Rethinking the Inception Architecture for Computer Vision
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although incr
arxiv.org
Background
ILSVRC2014에서 굉장히 높은 성능을 보였던 VGGNet과 GoogLeNet의 인기에 힘입어 많은 연구자들이 심층 신경망을 다양한 작업에 적용하기 시작하였습니다. 대표적으로 객체 탐지 (object detection), 영상 분할 (image segmentation), 동영상 분류 (video classification), 객체 추적 (object tracking) 등이 있죠. 이러한 작업들을 해결하기 위해 심층 신경망을 적용할 수 있었던 가장 큰 이유는 더 깊고 (#layer) 더 넓은 (#channel) 네트워크의 성능이 향상된다는 것입니다. 이를 기반으로 ImageNet 데이터셋에 학습된 네트워크를 다른 작업으로 전이 학습 (transfer learning)을 적용할 수 있게 되었죠.
하지만, VGGNet은 생각보다 높은 연산량을 가지게 됩니다. 이를 해결하기 위해 GoogLeNet은 여러 개의 필터 크기를 가지는 합성곱 계층을 병렬적으로 적용하여 마치 multi-scale의 효과를 얻을 수 있도록 만들었습니다. 이로 인해 상대적으로 낮은 파라미터 개수로도 성능이 높은 것을 확인할 수 있었죠. 하지만 여전히 GoogLeNet도 파라미터의 개수와 계산 복잡도가 높다고 판단됩니다. 본 논문에서는 이를 줄이기 위한 몇 가지 방법을 제시합니다.
Inception-V2
Strategy1. Factorization into Smaller Convolution
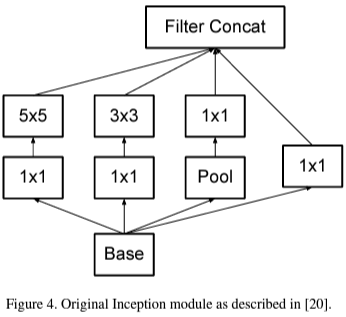
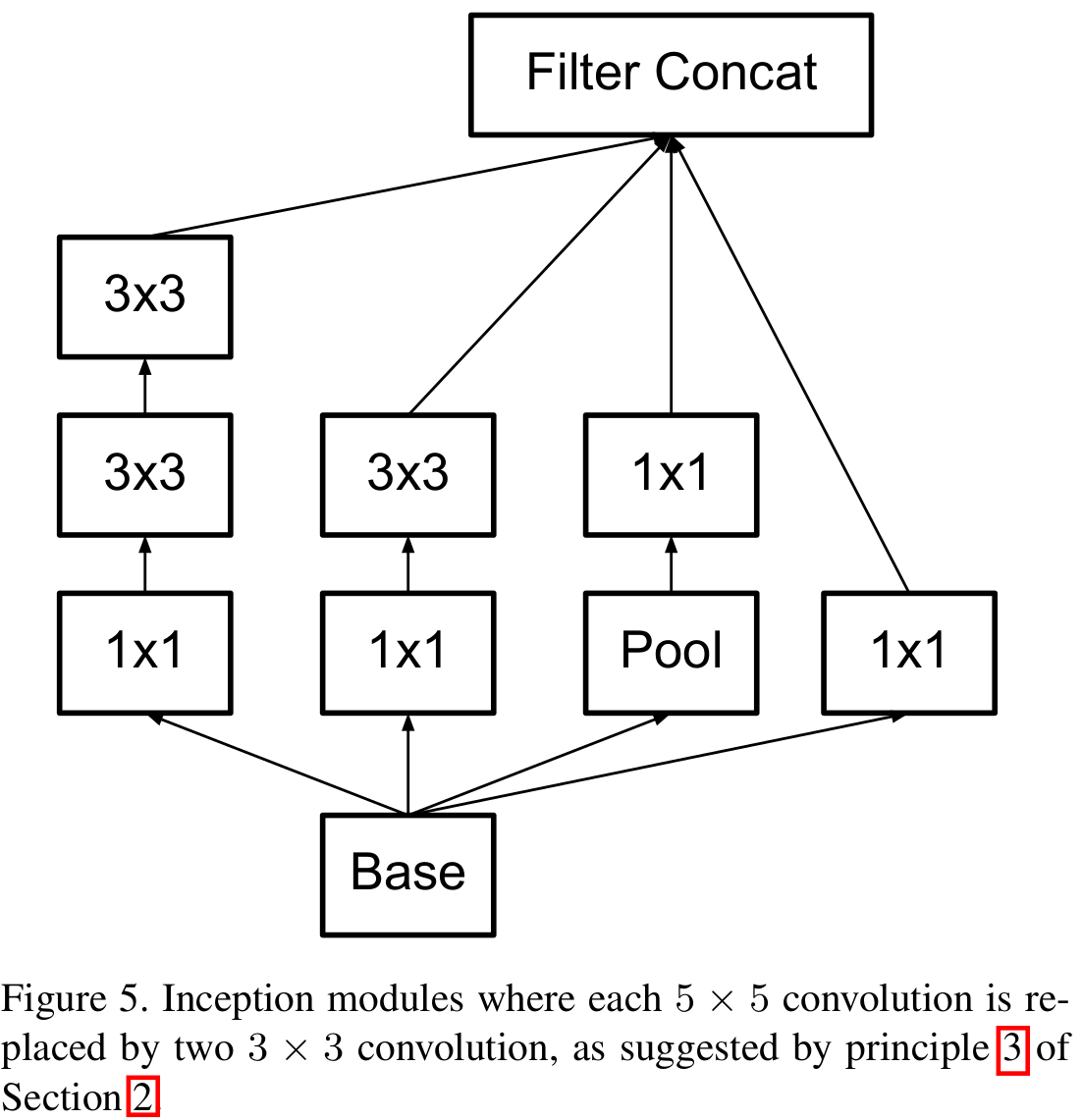
위 그림은 기존의 GoogLeNet에서 사용한 Inception Module입니다. 풀링을 제외하고 $1 \times 1, 3 \times 3, 5 \times 5$ 크기의 필터를 사용하였죠. Inception-V2에서는 이를 더 작은 크기의 필터로 분해할 것을 제안합니다.
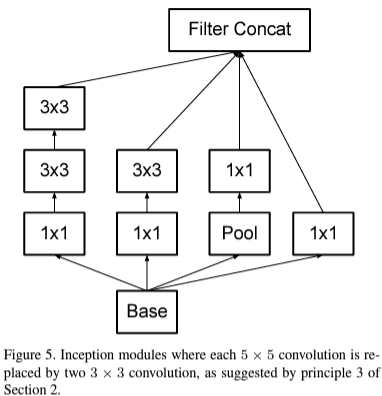
기존의 $5 \times 5$ 크기의 합성곱 계층은 $3 \times 3$ 크기의 합성곱 계층을 2개를 쌓아 구성하였습니다. 이렇게 되면 기존 모듈보다 $\frac {25}{9} \approx 2.78$배 정도 파라미터의 개수를 줄일 수 있습니다.
Strategy2. Spatial Factorization into Asymmetric Convolution
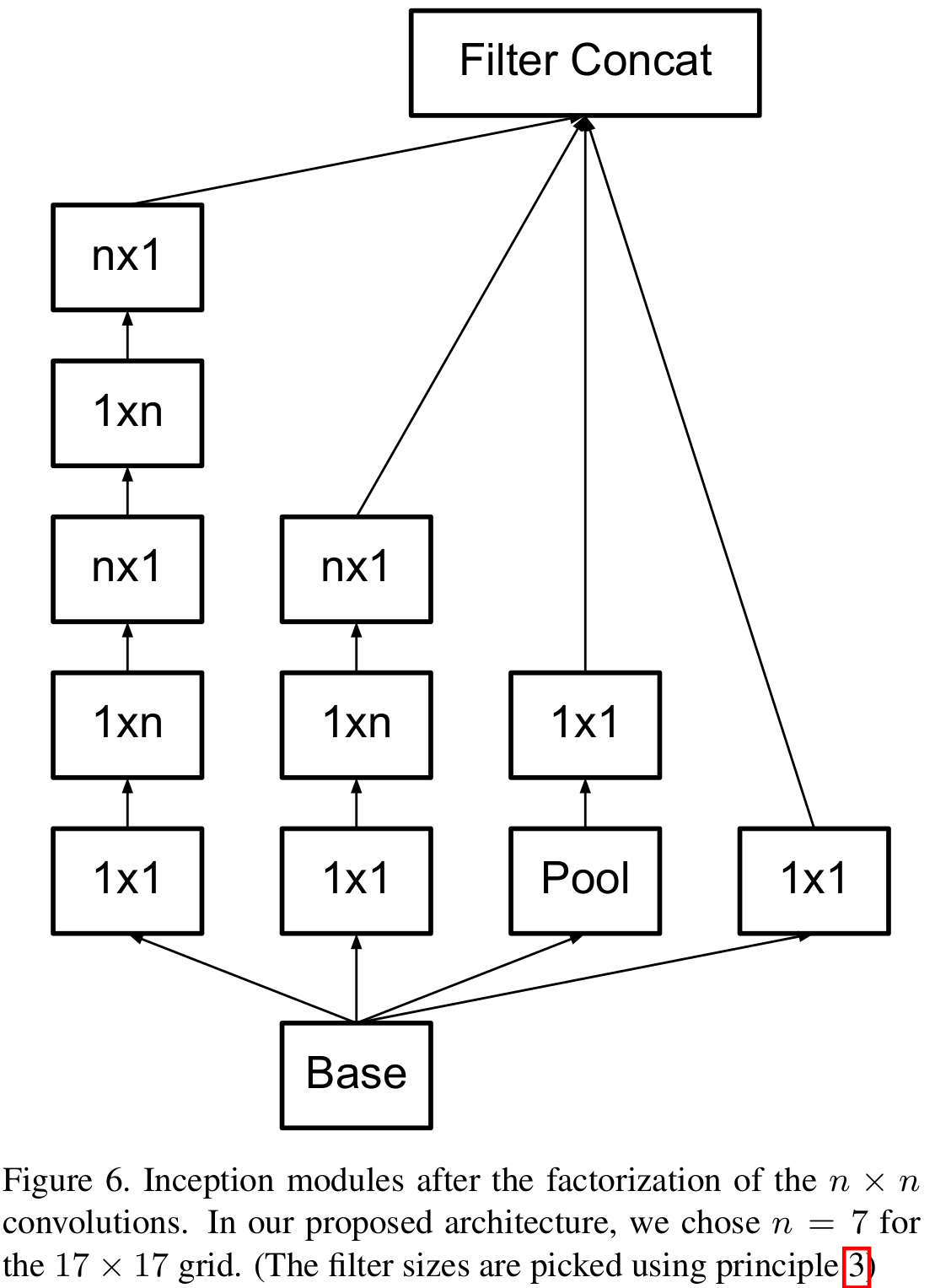
본 논문에서는 여기서 한 번 분해하는 것을 제안합니다. $3 \times 3$ 크기는 사실 VGGNet에서도 설명했다싶이 대칭성을 가지는 필터 크기 중에서는 가장 작습니다. 하지만, 비대칭성을 도입한다면 어떻게 될까요? 그러면 $1 \times 3$ 크기의 합성곱을 적용한 뒤 $3 \times 1$ 크기의 합성곱을 적용하면 되지 않을까요? 맞습니다. 본 논문에서는 이와 같이 비대칭성을 가지는 필터를 도입함으로써 파라미터의 개수와 연산량을 한번 더 줄이게 되죠.
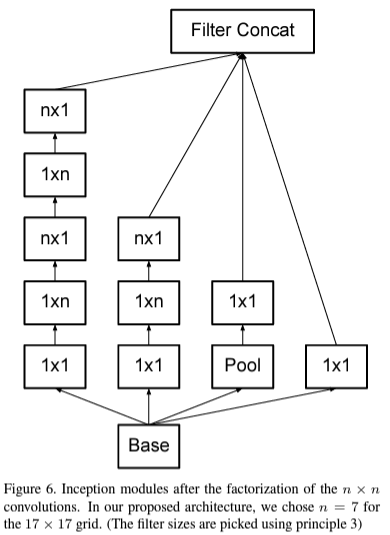
위 그림은 $n \times n$ 크기의 합성곱 계층을 분해했을 때 얻을 수 있는 Inception module입니다. 이를 통해 본 논문에서는 33%의 추가적인 연산량 감소를 얻게 됩니다.
Strategy3. Auxiliary Classifier
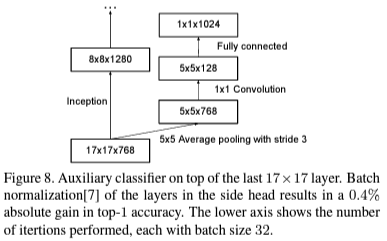
마지막으로 깊은 네트워크를 설계하면 되면 항상 발생하는 문제인 gradient vanishing problem을 해결하기 위해서 위 그림과 같은 보조 분류기를 추가하여 학습을 진행하였습니다.
Strategy4. Efficient Grid Size Reduction
일반적으로 심층 신경망 안에는 풀링 연산이 포함되어 입력 특징맵의 해상도를 절반으로 줄여줍니다. 이를 통해, 연산량의 이점을 얻을 수 있으나 표현력 (representation power)가 감소한다는 문제점이 있죠. 본 논문에서는 이를 해결하기 위한 방법을 제시합니다.

예를 들어 위 그림에서 왼쪽과 같이 풀링 연산을 한 뒤 Inception Module을 적용하면 표현력이 이미 감소하였기 때문에 Inception Module에서 장점을 발휘할 수 없습니다. 이번에는 Inception Module을 먼저 적용하게 되면 해상도가 크기 때문에 상대적으로 연산량이 많아질 수밖에 없습니다.
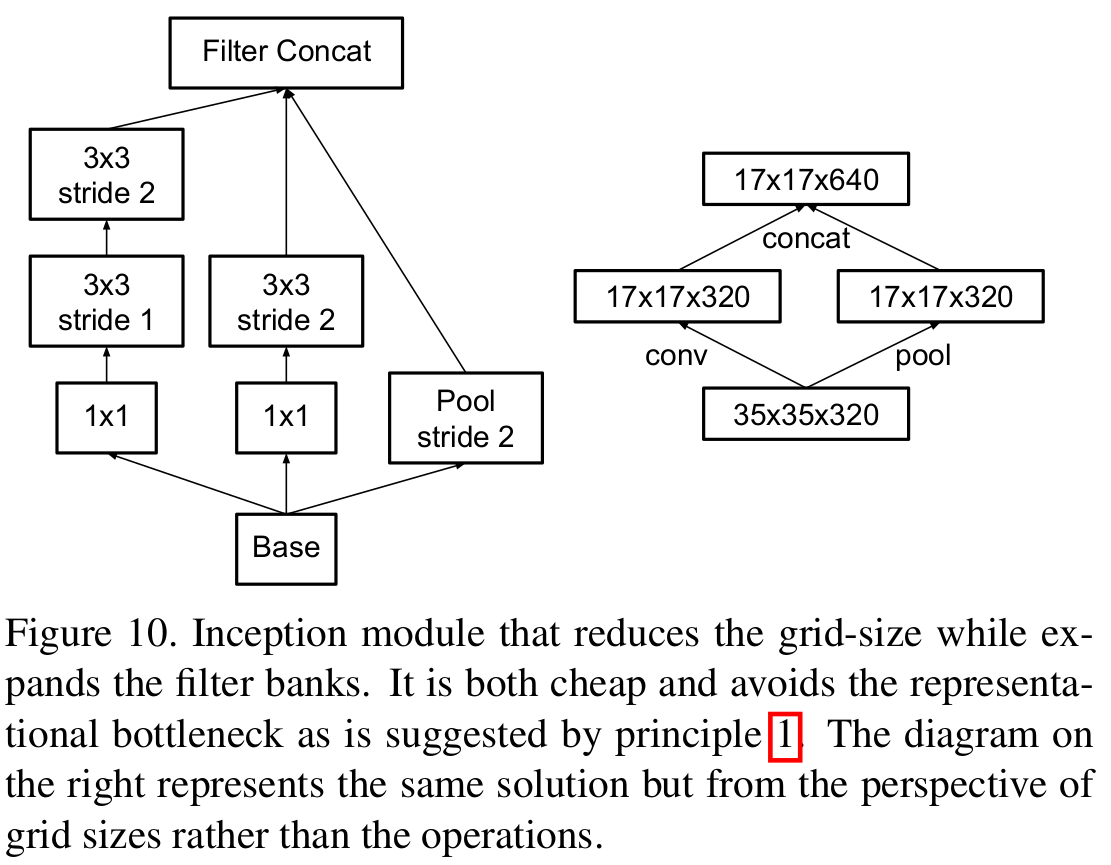
본 논문에서는 이러한 딜레마를 해결하기 위해 stride를 2로 가지는 필터를 정의하여 특징 맵의 해상도를 줄였습니다. 이와 같은 방법으로 표현력을 유지시키면서 연산량은 감소시킬 수 있습니다.
Inception-V2
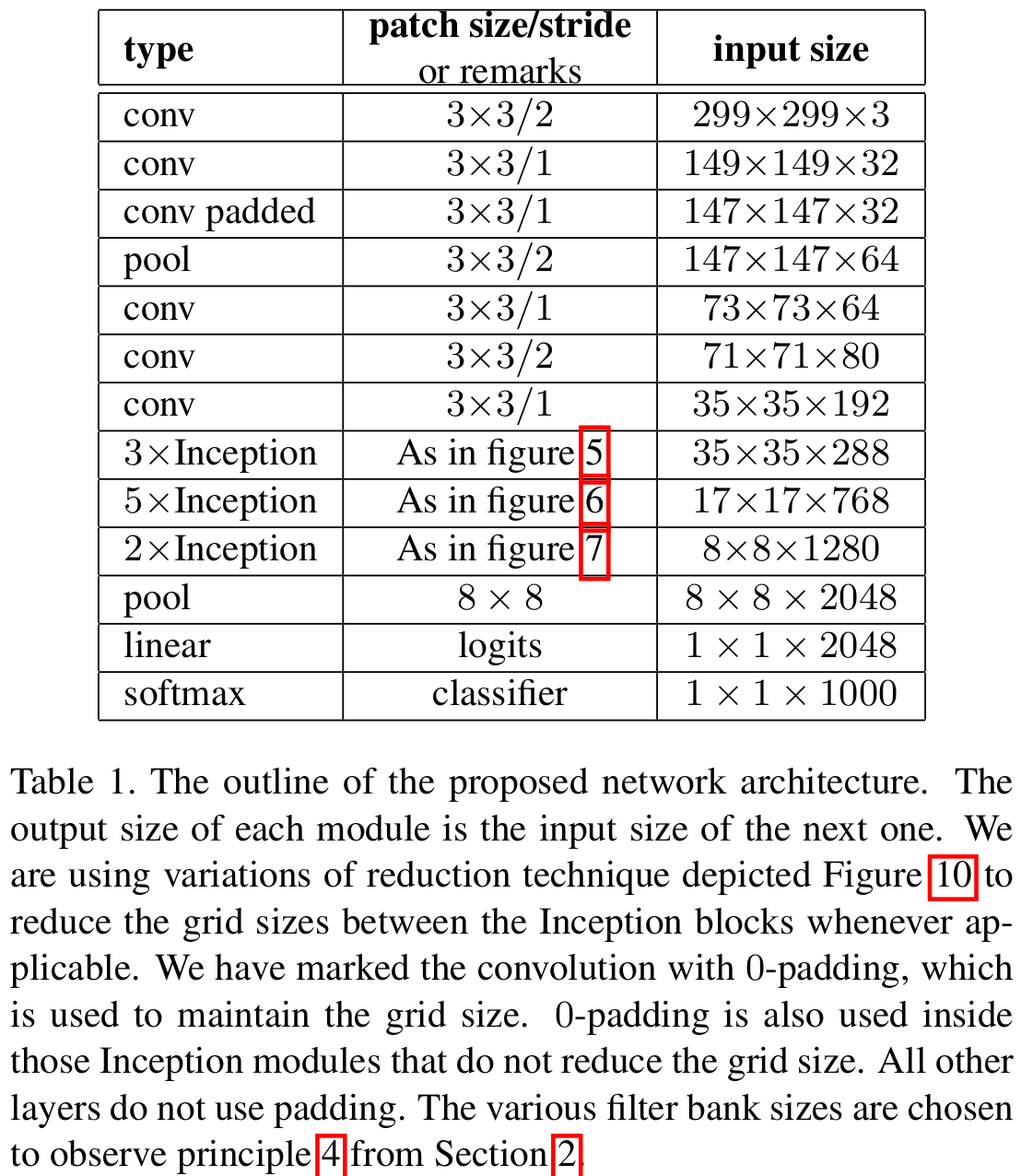
지금까지 설명한 Strategy1 ~ Strategy4까지 결합하여 하나의 모델로 구성한 것이 Table1입니다. 그리고 본 논문에서는 위와 같은 구조를 InceptionNet-V2라고 정의하였습니다. 여기서 중요한적은 Inception Module은 3가지로 각각 다르게 정의되어 사용되었다는 점을 유의하시면 쉽게 구현하실 수 있습니다.
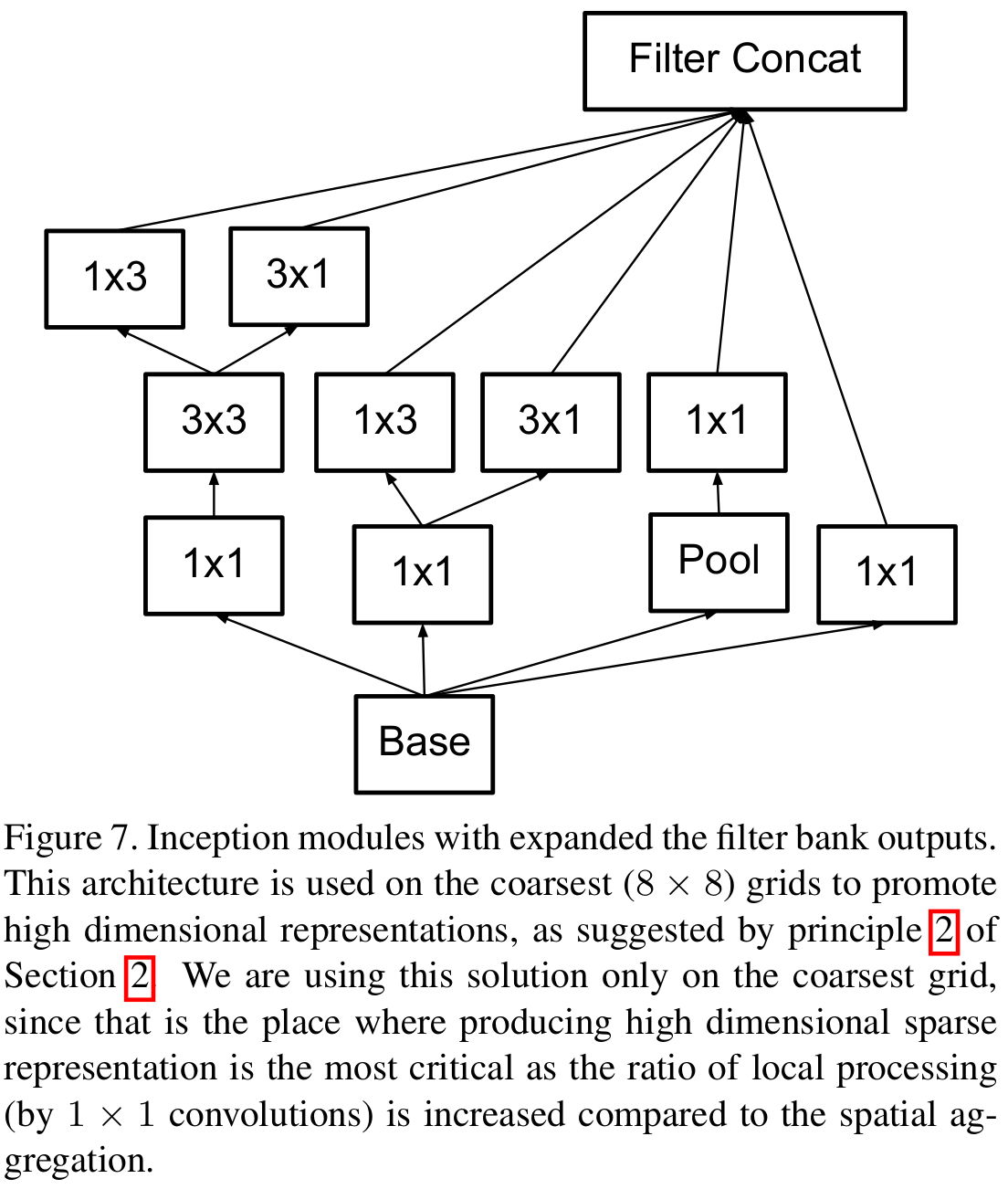
하지만, 아직 InceptionNet-V3에 대해서는 설명해드리지 않았습니다. 사실 구조적으로는 InceptionNet-V2와 InceptionNet-V3는 동일하지만 학습 방법에 따른 차이이기 때문에 추가적인 설명은 드리지 않겠습니다.
Label Smoothing
마지막으로 본 논문에서는 Label Smoothing을 적용하여 정규화 효과를 추가하였습니다. Label Smoothing을 $[0, 1, 0, 0, 0]$에 적용한다고 가정해 보겠습니다. 그러면 smoothing parameter $\epsilon$에 따라서 $[0.1, 0.6, 0.1, 0.1, 0.1]$과 같이 레이블에 스무딩을 적용하는 방법입니다. 이러한 학습 방식은 꽤나 이전부터 존재해 왔는데 제안한 논문에 따르면 학습하는 모델이 과신용 (overconfidence) 상태에 빠지지 않도록 도와준다고 합니다. 이러한 맥락은 마치 MixUp과도 어느 정도 유사한 거 같네요.
Experiment Results
본 논문에서는 InceptionNet-V2 + Auxiliary Classifier + RMSProp + Label Smoothing + Factorized $7 \times 7$을 적용하여 InceptionNet-V3를 정의하였습니다.
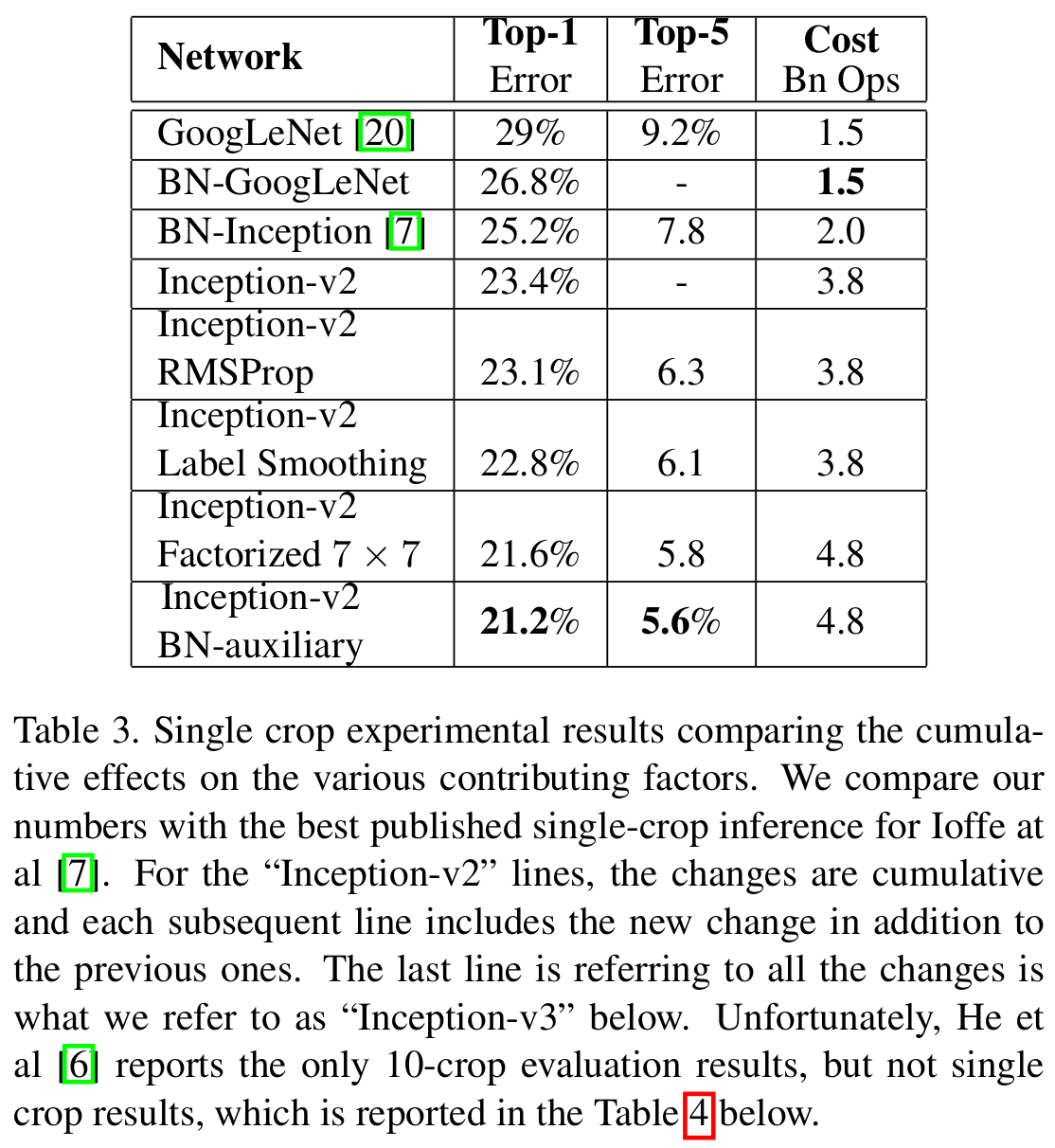
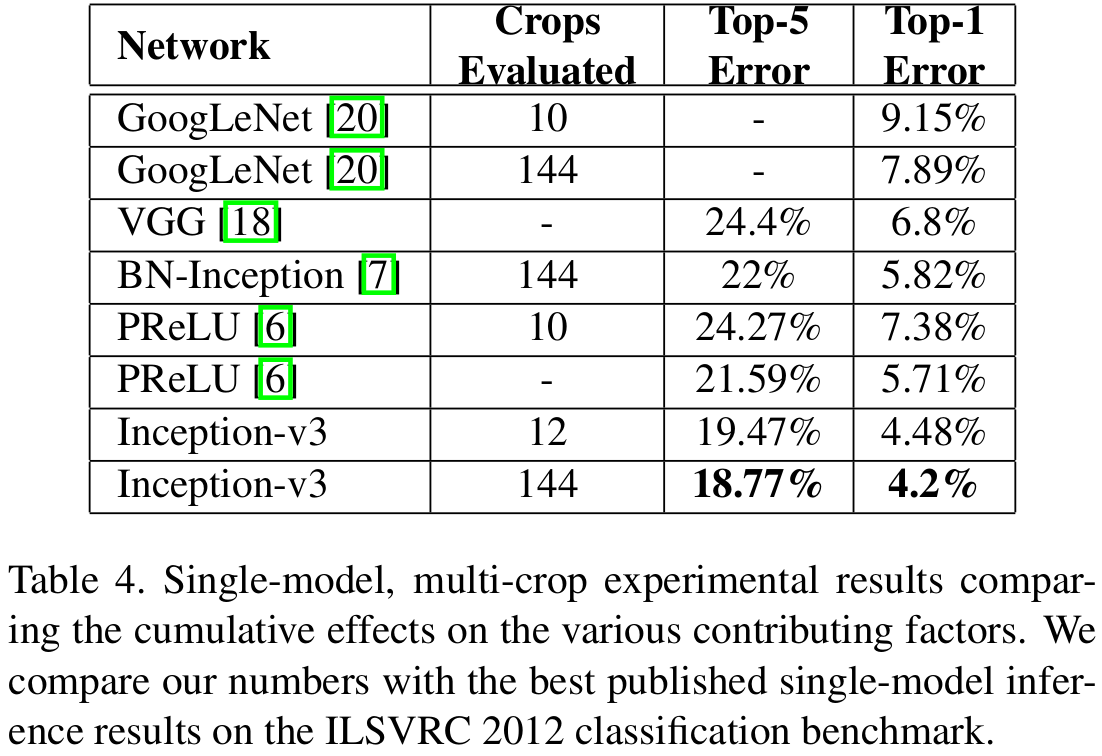
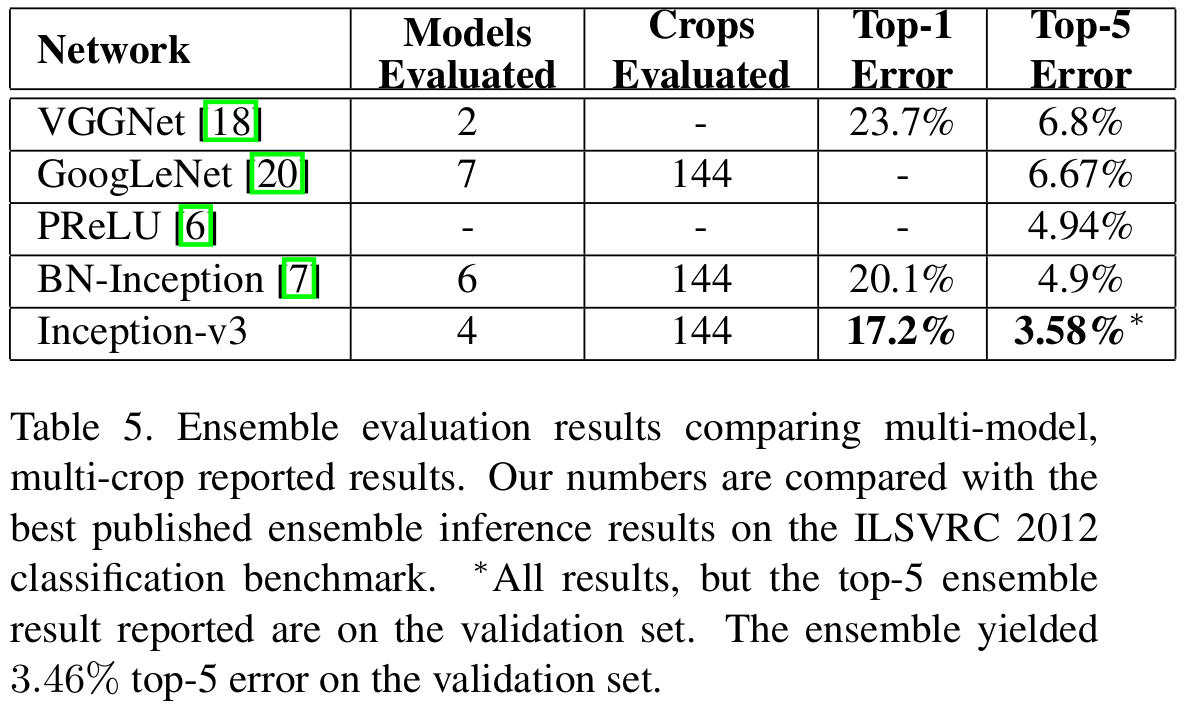
기본적으로 GoogLeNet (InceptionNet-V1)과 VGGNet보다는 훨씬 높은 성능을 보이고 잇습니다.