Background
블라인드 얼굴 복원(Blind Face Restoration)은 다운샘플링, 블러, 노이즈, 압축 아티팩트 등 현실 세계에서 원인을 특정하기 어려운(unknown) 복합 열화가 섞인 입력으로부터, 고품질의 얼굴 이미지를 복원하는 과제다. 열화가 사전에 알려지지 않기 때문에 복원 자체가 매우 까다롭고, 단순히 손상된 입력만으로는 고품질 디테일을 안정적으로 되살리기 어렵다는 점이 반복적으로 지적되어 왔다. 그래서 기존 연구들은 복원 성능을 끌어올리기 위해 다양한 prior(사전 지식/프라이어)를 활용해 왔고, 대표적으로 기하(landmark·parsing map·component heatmap 등), 참조(reference exemplar·dictionary), 생성(generative model) 기반 프라이어로 큰 갈래가 정리된다. 다만 프라이어 기반 접근에는 구조적인 한계가 있다.
- 기하학적 프라이어는 대개 저품질 입력에서 추정되므로, 입력이 심하게 손상될수록 프라이어 품질이 같이 무너져 복원 성능이 제한된다.
- 참조 기반 방법은 이상적으로는 동일 인물의 고해상도 참조가 필요하지만 현실적으로 항상 구하기 어렵고, 이를 완화하려는 컴포넌트 딕셔너리 계열도 눈·코·입 등 일부 부위 중심으로 프라이어가 제한되거나(또는 인식 목적의 오프라인 특징 추출에 의존해) 디테일 다양성이 충분치 않을 수 있다.
- 생성 프라이어는 고품질 “그럴듯함(realness)”을 만들 잠재력이 있지만, 잠재공간 탐색을 위한 비용이 크거나(최적화 기반) 혹은 학습 과정에서 입력 얼굴의 identity 정보를 충분히 반영하지 못해 복원 결과의 충실도(fidelity)가 떨어질 수 있다는 문제가 지적된다.
결국 블라인드 얼굴 복원에서는 (1) 손상 입력이 주는 정체성 단서와 (2) 프라이어가 제공하는 고품질 디테일이라는 “두 정보원”을 잘 결합하는 것이 핵심인데, 단순 concat이나 픽셀 단위 결합(SFT 등)은 얼굴의 풍부한 전역 문맥을 충분히 활용하지 못해 서브옵티멀한 결과로 이어질 수 있다.
이런 맥락에서 최근 비전 분야로 확장된 Transformer 계열은, 이미지 내 전역 컨텍스트를 모델링하는 데 강점이 있어(인식·검출·분할뿐 아니라 저수준 비전 과제에도 활용) 얼굴 복원에도 매력적인 선택지로 부상했다. 하지만 일반적인 ViT는 단일 입력(여기서는 손상 얼굴)만을 self-attention으로 처리하는 경우가 많아, “손상 입력 + 프라이어”처럼 서로 다른 두 정보원을 결합해야 하는 얼굴 복원 문제에 그대로 적용하기는 어렵다. 본 논문에서 제안하는 RestoreFormer는 이 결합 문제를 “완전 공간(fully-spatial) 상호작용” 관점에서 재정의하고, 손상 특징을 query로 두고 고품질 프라이어를 key-value로 두는 cross-attention을 통해 두 정보원을 전역적으로 융합하는 방향을 제안한다. 또한 프라이어 자체도 단순한 인식 지향 특징이 아니라, 다수의 정상(undegraded) 얼굴로부터 벡터 양자화 아이디어를 활용해 학습한 복원 지향(reconstruction-oriented) HQ Dictionary에서 샘플링함으로써, 특정 부위에 국한되지 않고 얼굴 전 영역에서 풍부한 디테일을 제공하도록 설계했다는 점이 배경으로 제시된다.
Method
1) RestoreFormer
RestoreFormer의 핵심은 손상된 얼굴(degraded face)에서 얻은 정체성(Identity) 단서와 고품질 얼굴 priors가 제공하는 디테일을, 픽셀 단위가 아니라 전역 컨텍스트를 고려하는 fully-spatial attention으로 결합하는 데 있다. 전체 파이프라인은 (1) 인코더로 손상 입력을 특징 공간으로 투영하고, (2) HQ Dictionary에서 해당 위치에 맞는 고품질 priors를 가져온 뒤, (3) 두 개의 cross-attention 기반 Transformer 블록으로 둘을 융합하고, (4) 디코더로 최종 복원 이미지를 생성하는 흐름으로 구성된다.

1-1) Multi-Head Self-Attention (MHSA)
기존의 ViT에서 사용하는 Multi-Head Self-Attention (MHSA)난 단일 정보원에 대해 self-attention을 수행한다. 본 논문에서는 그 단일 정보원이 손상된 얼굴 영상으로부터 얻은 특징인 $Z_{d}$이며 queries/keys/values가 모두 $Z_{d}$에서 만들어져 전역 상호작용을 학습한다. 이후 attention 출력과 $Z_{d}$를 residual로 더한 뒤 정규화와 FFN을 통과시켜 최종 특징을 얻는다. 이 과정을 좀 더 자세히 설명하면 다음과 같다.
먼저 queries/keys/values가 모두 $Z_{d}$에서 추출하여 $\mathbf{Q} = \mathbf{Z}_{d}\mathbf{W}_{q} + \mathbf{b}_{q}, \mathbf{K} = \mathbf{Z}_{d}\mathbf{W}_{k} + \mathbf{b}_{k}, \mathbf{V} = \mathbf{Z}_{d}\mathbf{W}_{v} + \mathbf{b}_{v}$를 얻게 된다. 이때, $\mathbf{W}_{q/k/v} \in \mathbb{R}^{C \times C}$와 $\mathbf{b}_{q/k/v} \in \mathbb{R}^{C}$는 학습 가능한 파라미터로 정의된다.
이때, 더 강한 표현력을 위해서 multi-head를 도입할 수 있다. 쉽게 보면 처음에 얻은 queries/keys/values를 채널 단위로 쪼개어 $N_{h}$개의 블록으로 나누어 $\{ \mathbf{Q}_{1}, \dots, \mathbf{Q}_{N_{h}} \}, \{ \mathbf{K}_{1}, \dots, \mathbf{K}_{N_{h}} \}, \{ \mathbf{V}_{1}, \dots, \mathbf{V}_{N_{h}} \} $를 얻는다. 이때, 각 블록의 채널 개수는 $C_{h} = \frac{C}{N_{h}}$가 된다. 그리고 다음 단계는 각 블록에 대해서 self-attention을 수행해주면 된다.
$$\mathbf{Z}_{i} = \text{Softmax} \left( \frac{\mathbf{Q}_{i}\mathbf{K}_{i}^{\top}}{\sqrt{C_{h}}} \right) \mathbf{V}_{i}$$
여기서 $i$는 head의 index를 의미한다. 다음으로 각 head의 output들을 하나로 concat하여 다음과 같이 결과를 얻는다.
$$\mathbf{Z}_{mh} = \text{concat}_{i = 1, \dots, N_{h}} \mathbf{Z}_{i}$$
이때, 기존의 ViT에서는 학습 안정성과 추가적인 표현력 향상을 위해 다음과 같이 최종 결과를 얻게 된다.
$$\mathbf{Z}_{a} = \text{FFN} (\text{LN} (\mathbf{Z}_{mh} + \mathbf{Z}_{d}))$$
1-2) Multi-Head Cross-Attention (MHCA)
반면 RestoreFormer의 Multi-Head Cross-Attention (MHCA)는 얼굴 복원에 필요한 두 정보원을 명시적으로 분리한다. Query는 손상 특징 $\mathbf{Z}_{d}$에서 얻고 Key/Value는 HQ Dictionary로부터 얻은 priors $\mathbf{Z}_{p}$에서 얻는다. 이를 통해, 손상 정보(정체성)와 고품질 디테일을 공간적으로(fully-spatial) 결합한다. 또한, $\mathbf{Z}_{mh}$를 residual connection으로 연결할 때 $\mathbf{Z}_{d}$가 아닌 $\mathbf{Z}_{p}$를 더하도록 설계가 되었다. 이 과정은 결국 MHSA와 거의 유사하게 수행될 수 있다.
먼저, queries는 $\mathbf{Z}_{d}$에서 추출하고 keys/values는 $\mathbf{Z}_{p}$에서 얻는다. 이를 수식으로 표현하면 $\mathbf{Q} = \mathbf{Z}_{d}\mathbf{W}_{q} + \mathbf{b}_{q}, \mathbf{K} = \mathbf{Z}_{p}\mathbf{W}_{k} + \mathbf{b}_{k}, \mathbf{V} = \mathbf{Z}_{p}\mathbf{W}_{v} + \mathbf{b}_{v}$가 된다. 다음 단계는 MHSA와 동일하게 multi-head로 쪼개준 뒤 각 head 별로 cross-attention을 수행하고 하나로 concat한다. 마지막으로 residual connection과 FFN을 통해 다음과 같이 최종 결과를 얻는다.
$$\mathbf{Z}_{f} = \text{FFN} (\text{LN} (\mathbf{Z}_{mh} + \mathbf{Z}_{p}))$$
1-3) RestoreFormer
따라서, 핵심은 고품질의 HQ Dictionary를 어떻게 설계할 것이며 어떻게 활용할 것 인지가 핵심적으로 다른 부분이 될 것이다. 본 논문에서는 이를 위해 다음과 같이 인코더에서 얻은 특징 $\mathbf{Z}_{d}$와 HQ Dictionary에 포함된 vector들 중 가장 의미론적으로 가까운 것을 선택한다.
$$\mathbf{Z}_{p}^{(i, j)} = \text{argmin}_{d_{m} \in \mathbb{D}} ||\mathbf{Z}_{d}^{(i, j)} - d_{m}||^{2}_{2}$$
그리고 RestoreFormer에서는 다음과 같이 두 번의 연속된 MHCA를 적용하여 특징을 추출합니다.
$$\mathbf{Z}_{f}^{'} = \text{MHCA} (\mathbf{Z}_{d}, \text{MHCA}(\mathbf{Z}_{d}, \mathbf{Z}_{p}))$$
그리고 $\mathbf{Z}_{f}^{'}$는 디코더에 입력되어 고품질의 얼굴영상 $\hat{\mathbf{I}}_{d} \in \mathbb{R}^{H \times W \times 3}$을 얻는다.
1-4) Learning
본 논문에서는 RestoreFormer를 학습하기 위해 총 3가지의 다른 관점에서의 손실함수를 사용한다. 각각 1) Pixel-level Loss, 2) Component-level Loss, 그리고 3) Image-level Loss이다. 이를 각각 정리하면 다음과 같다.
1-4-1) Pixel-level Loss
$$\begin{cases} \mathcal{L}_{l1} &= ||\mathbf{I}_{h} - \hat{\mathbf{I}}_{d}||_{1} \\ \mathcal{L}_{\text{per}} &= ||\phi(\mathbf{I}_{h} - \hat{\mathbf{I}}_{d})||_{2}^{2} \\ \mathcal{L}_{p} &= ||\mathbf{Z}_{d} - \mathbf{Z}_{p}||_{2}^{2} \end{cases}$$
1-4-2) Component-level Loss
$$\begin{cases} \mathcal{L}_{\text{disc}} &= \sum_{r} \left[ \log D_{r} (R_{r} (\mathbf{I}_{h})) + \log \left( 1 - D_{r}(R_{r} (\hat{\mathbf{I}}_{d})) \right) \right] \\ \mathcal{L}_{\text{style}} &= \sum_{r} ||\text{Gram}(\phi(R_{r}(\mathbf{I}_{h}))) - \text{Gram}(\phi(R_{r} (\hat{\mathbf{I}}_{d})))|| \end{cases}$$
여기서 $r \in \{ \text{left eye}, \text{right eye}, \text{mouth} \}$이고 $R_{r}(\cdot)$는 $r$을 기준으로 추출한 RoI이다. 그리고 $\phi$는 region $r$로 학습된 판별기 $D_{r}$의 다중-해상도 특징이다. 그리고 $\text{Gram}(\cdot)$은 Gram Matrix로 스타일의 correlation을 계산하기 위해 사용된다.
1-4-3) Image-level Loss
$$\begin{cases} \mathcal{L}_{\text{adv}} &= \left[ \log D_{r} (\mathbf{I}_{h}) + \log (1 - D_{r}(\hat{\mathbf{I}}_{d})) \right] \\ \mathcal{L}_{\text{id}} &= ||\eta (\mathbf{I}_{h}) - \eta (\hat{\mathbf{I}}_{d})|| \end{cases}$$
2) HQ Dictionary
HQ Dictionary는 RestoreFormer에서 고품질 얼굴 사전(prior) 역할을 수행하는 핵심 구성 요소로, 심하게 열화된 입력 영상만으로는 복원하기 어려운 세밀한 얼굴 디테일을 보완하기 위해 설계되었다. 이 사전은 다수의 고해상도 얼굴 이미지로부터 추출된 특징들을 저장하고 있으며, 네트워크가 복원 과정에서 참조할 수 있는 고품질 key–value 쌍을 제공한다. 이를 통해 모델은 입력 영상에 부족한 질감, 윤곽, 국소 구조 정보를 외부 지식 형태로 활용할 수 있다.

그림 3과 같이 기존 얼굴 복원 연구에서 사용되던 사전(dictionary)은 주로 인식(recognition) 지향적 특징을 기반으로 구성되어, 신원(identity) 구분에는 유리하지만 실제 시각적 복원 품질에는 한계가 있었다. 반면 RestoreFormer의 HQ Dictionary는 재구성(reconstruction) 지향적으로 학습된 인코더를 통해 구축된다. 즉, 얼굴 인식용 사전과 달리, 픽셀 수준의 복원과 시각적 사실성을 극대화하는 데 초점을 둔 특징들을 담고 있어, 보다 자연스럽고 세밀한 복원 결과를 유도한다는 점이 차별점이다.
이를 위해 그림 3 (b)에서 보이는 얼굴 생성 네트워크를 활용한다. 첫번째 단계로 인코더로부터 고품질 얼굴 영상 $\mathbf{I}_{h} \in \mathbb{R}^{H \times W \times 3}$ 에 대한 representation $\mathbf{Z}_{h} \in \mathbb{R}^{H^{'} \times W^{'} \times C}$를 얻는다. 다음 단계로 $\mathbf{Z}_{h}$의 feature vector를 양자화 (quantization)을 수행하여 HQ Dictionary $\mathbb{D}$내의 벡터들 중 가장 가까운 prior $\mathbf{Z}_{p} \in \mathbb{R}^{H^{'} \times W^{'} \times C}$를 얻는다.
$$\mathbf{Z}_{p}^{(i, j)} = \text{argmin}_{d_{m} \in \mathbb{D}} ||\mathbf{Z}_{h}^{(i, j)} - d_{m}||^{2}_{2}$$
그리고 $\mathbf{Z}_{p}$를 를 그대로 디코더에 입력하여 영상을 복원하게 된다.
2-1) Learning
처음에 HQ Dictionary 내의 모든 vector들은 uniform distribution에 따라 randomly initialized된다. 그리고 각 vector들의 update를 위해서 Vector Quantization (VQ) 기법을 도입하여 아래의 두 가지 손실함수를 활용한다.
$$\begin{cases} \mathcal{L}^{'}_{d} &= ||\text{sg} (\mathbf{Z}_{h}) - \mathbf{Z}_{p}||_{2}^{2} \\ \mathcal{L}_{c}^{'} &= ||\mathbf{Z}_{h} - \text{sg} (\mathbf{Z}_{g})||_{2}^{2} \end{cases}$$
또한, $\mathbf{Z}_{p}$만으로도 복원력을 향상시켜야 하기 때문에 복원 관련 손실함수들도 여기에서 그대로 학습을 진행한다.
Experiment Results
1) Comparison with State-of-the-Art Methods
1-1) Synthetic Dataset


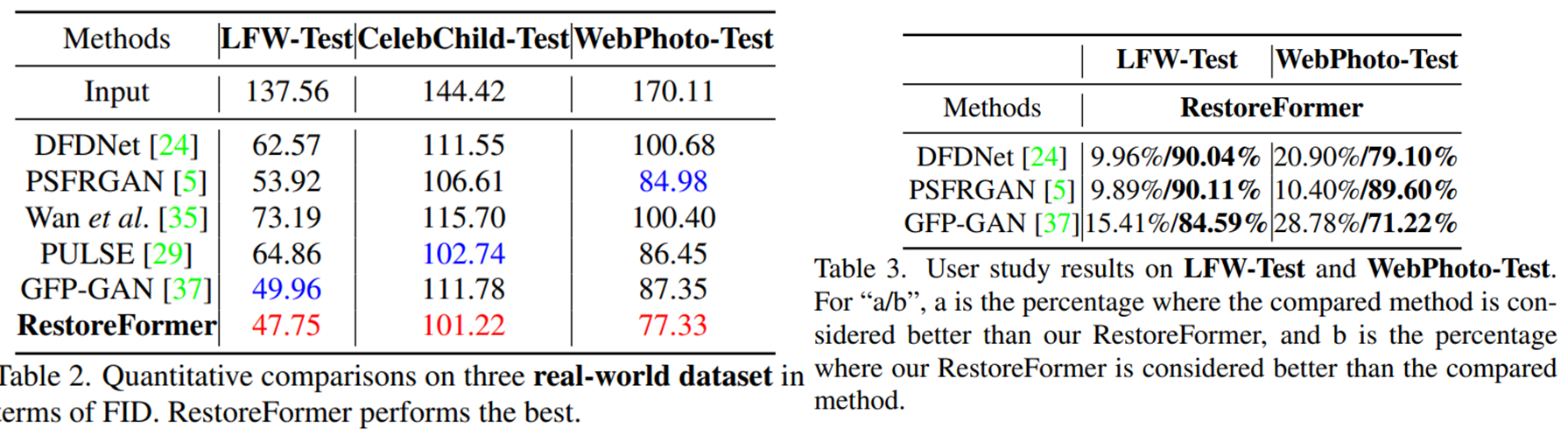
1-2) Real-world Dataset

2) Ablation Study

