
Background
딥 러닝 기반 시각 표현학습은 오랫동안 CNN과 Vision Transformer (ViT)라는 두 축을 중심으로 발전해왔습니다. CNN은 지역적인 패턴을 효율적으로 포착하는 대신 먼 거리에 있는 패치 간의 관계를 모델링하는 데에 한계가 존재한다. 반대로 ViT는 self-attention을 통해 전역적인 문맥 정보를 동적으로 통합할 수 잇지만 토큰 수에 대해 연산 복잡도 제곱으로 증가한다는 근본적인 병목 문제를 안고 있어 고해상도 입력이다 다운스트림 비전 태스크에서 계산, 메모리 효율이 크게 떨어진다. 이러한 문제를 완화하기 위해 다양한 효율형 어텐션, 계층적 ViT, ConNeXt와 같은 Transformer 스타일 CNN 등이 제안되었지만 여전히 전역적인 수용영역과 동적 가중치, 그리고 실용적인 계산 복잡도를 동시에 만족시키기는 어렵다.
최근 자연어 처리 분야에서는 State Space Model (SSM)을 딥 러닝 시퀀스 모델로 재해석한 연구가 활발히 진행되고 있다. 특히, Mamba는 시간에 따라 입력 의존적으로 변화하는 파라미터 (Selective SSM, S6)를 도입하고 이를 GPU에 친화적인 병렬 스캔 알고리즘으로 구현함으로써 긴 시퀀스를 선형 시간 복잡도로 처리하면서도 Transformer와 경쟁 사능한 성능을 보여주었다. 이때, 핵심 selective scan은 1차원 순차 데이터 (문장, 시계열)을 전제로 설계되어 있어, 이미지처럼 본질적으로 비순차적이고 2D 구조를 가진 비전 데이터에 그대로 적용하기는 어렵다는 한계를 가진다.
한편 비전 분야에서도 S4ND, Vim 등 SSM을 이미지 및 비디오에 도입하려는 시도가 있었지만 대부분은 CNN과 Transformer와 혼합된 하이브리드 구조에 머물렀으며 "순수 SSM 기반 비전 백본"은 거의 탐색되지 않았다. 특히, 1D 커널을 단순히 2D로 확장하는 식의 접근은 입력 의존적인 가중치를 활용하기 어렵기 때문에 문맥 표현력이 제한된다. 본 논문에서 제안하는 VMamba는 이러한 연구 공백을 메우기 위해 제안된 SSM 기반 비전 백본으로 self-attention 대비 훨씬 가벼운 선형 복잡도를 유지하면서 2D Selective Scan (SS2D)을 통해 1D 시퀀스 스캔과 2D 공간 트래버설의 간극을 메우고 전역 문맥 정보를 효과적으로 수집하도록 설계되었다.
Method
1) Prelimaries
VMamba를 이해하기 위해서는 먼저 SSM과 Mamba의 Selective Scan 개념을 간다하게 집고 넘어갈필요가 있다. SSM은 원래 칼만 필터에서 시작된 선형 시간-불변 (Linear Time Invariant; LTI) 시스템으로 입력 시퀀스 $u(t)$를 hidden state $h(t)$를 거쳐 출력 $y(t)$로 매핑하는 연속 시간 모델이다. 가장 기본적인 형태는 다음과 같다.
$$\begin{cases} h^{'}(t) &= Ah(t) + Bu(t) \\ y(t) &= Ch(t) + Du(t) \end{cases}$$
여기서 $A, B, C, D$는 학습되는 파라미터, $h(t)$는 길이가 $N$인 hidden state, $u(t)$와 $y(t)$는 각각 스칼라 혹은 저차원 벡터 입력 및 출력이다. 딥 러닝에서 SSM을 사용하려면 이를 시간축에 따라 샘플링하여 이산화(discretization) 해야한다. 적절한 샘플 간격 $\Delta$로 이산화하면 SSM은 다음과 같은 1D 재귀식으로 변형할 수 있다.
$$\begin{cases} h_{t} &= \overline{A}_{t}h_{t - 1} + \overline{B}_{t}x_{t} \\ y_{t} &= \overline{C}_{t}h_{t} + \overline{D}_{t}x_{t} \end{cases}$$
여기서 $x_{t}$는 입력 토큰, $h_{t}$는 시점 $t$의 hidden state이다. 이때, 재귀 계산은 시퀀스 길이 $T$에 대해 선형 복잡도 $\mathcal{O}(T)$를 가지므로 RNN 처럼 긴 시퀀스를 효율적으로 처리할 수 있다. S4, S4D, S4ND와 같은 최근 구조들은 이 공식을 안정적으로 그리고 효율적으로 계산할 수 있도록 행렬 구조를 제약한 변형들이다.
Mamba는 여기에 파라미터 $A, B, C, \Delta$를 입력 의존(time-varying, data-dependent) 만들고 이를 GPU 친화적인 selective scan 알고리즘으로 병렬화한 모델이다. 즉, 각 시점마다 다른 동적 가중치를 사용하면서도 연산을 prefix-sum 형태로 재구성해 여전히 시퀀스 길이에 선형인 시간 및 메모리 복잡도를 유지한다. Selective SSM (S6) (1) 전역 수용영역, (2) 동적 가중치, (3) 선형 복잡도라는 세 가지 중요한 특성을 동시에 제공하며 Mamba가 NLP에서 Transformer와 경쟁하는 성능을 내는 핵심요인이다.
VMamba는 바로 이 Selective SSM (S6)을 비전 도메인으로 가져오는 모델이다. 다만 S6는 본질적으로 1D 시퀀스 가정하고 설계되어있기 때문에 2D 이미지처럼 비순차적이고 공간 구조를 가진 데이터를 직접 다루기 어렵다. VMamba는 이후 Method에서 설명할 2D Selective Scan (SS2D)를 통해 1D Selective Scan의 수식을 유지하면서도 2D 공간을 네방향 스캔 경로로 쪼개어 처리할 수 있도록 확장한다. 그 결과 self-attention과 유사한 전역 문맥 수집능력을 가지면서도, 입력 해상도에 대해 선형적으로 스케일하는 순수 SSM 기반 비전 백본을 구성하였다.
2) Network Architecture

그림 3은 VMamba의 전체적인 네트워크 구조를 보여준다. VMamba는 Tiny, Small, Base 세 가지 스케일로 설계된 순수 SSM 기반 비전 백본으로 전형적인 4 스테이지 계층형 (hierarchical) 구조를 따른다. 입력 이미지는 먼저 stem 모듈에서 $4 \times$ 다운샘플링되어 $\frac{H}{4} \times \frac{W}{4}$ 해상도의 feature map으로 변환되고 이후 Stage 1 ~ 4를 거치며 해상도는 $\frac{H}{4} \times \frac{W}{4} \rightarrow \frac{H}{8} \times \frac{W}{8} \rightarrow \frac{H}{16} \times \frac{W}{16} \rightarrow \frac{H}{32} \times \frac{W}{32}$, 채널 수는 $C_{1} \rightarrow C_{2} \rightarrow C_{3} \rightarrow C_{4}$로 점진적으로 변화한다. 마지막에는 global average pooling과 선형 분류기를 통해 최종 클래스 점수를 출력한다.

각 Stage는 (1) 해상도를 절반으로 줄이는 다운샘플링 레이어와 (2) 여러 개의 Visual State Space (VSS) Block으로 구성된다. Swin Transformer, ConvNeXt와 달리 별도의 positional embedding 없이도 SS2D와 depth-wise convolution이 공간적 inductive bias와 전역 문맥 정보를 함께 제공하도록 설계된 것이 특징이다. VMamba-Tiny/Small/Base는 동일한 stage 구조를 공유하되 채널 수 $C_{i}$와 block 개수만 조정하여 파라미터 수와 FLOPs를 모델 규모에 맞추어 스케일링한다.
VSS block은 원래 Mamba block에서 핵심인 S6 모듈을 2D Selective Scan(SS2D) 모듈로 치환한 뒤, 구조를 Transformer 블록처럼 두 개의 잔차 경로로 단순화한 형태다. 첫 번째 경로는 LayerNorm → Linear 확장(ssm-ratio) → depth-wise conv → SS2D → Linear 축소로 구성된 “SS2D 경로”이고, 두 번째 경로는 표준 FFN(MLP, mlp-ratio)으로 이루어진다. Mamba 원본에 있던 multiplicative branch(게이팅 경로)는 SS2D 자체의 selectivity가 유사한 효과를 내기 때문에 제거하여 구조를 간결하게 만들었다. 이 설계 덕분에 VMamba는 CNN·ViT와 유사한 계층형 백본 프레임워크 안에서, 전역 receptive field·동적 가중치·선형 복잡도라는 selective SSM의 장점을 그대로 활용할 수 있다.
3) 2D-Selective-Scan for Vision Data (SS2D)
SS2D의 출발점은 아주 단순하다. Mamba의 핵심 연산인 Selective Scan(S6) 은 “시간축을 따라 한 방향으로 흐르는 1D 시퀀스”에 최적화되어 있는데, 이미지는 본질적으로 2D 그리드라서 어느 한 방향이 자연스럽게 정의되지 않는다. 기존 2D SSM 시도인 S4ND는 커널을 1D→2D로 외적 확장해 문제를 풀지만, 이 경우 가중치가 입력에 의존하지 않기 때문에 selective SSM이 가진 동적 가중치와 문맥 적응력을 잃게 된다.

VMamba는 이 한계를 피하기 위해, S6의 “선택적 스캔” 철학은 유지하면서도 2D 구조를 고려한 2D-Selective-Scan(SS2D) 을 제안한다. 그림 2를 보면, 입력 패치를 네 가지 스캔 경로로 펼쳐 1D 시퀀스 네 개를 만든 뒤, 각 시퀀스를 서로 다른 S6 블록으로 처리하고 다시 2D 피처 맵으로 되돌리는 흐름을 한눈에 볼 수 있다. 이러한 SS2D의 동작은 크게 세 단계로 요약할 수 있다.
STEP1. Cross-Scan (4-way unfolding)
입력 피처 맵을 네 개의 1D 시퀀스로 펼친다. 대표적으로 좌→우·상→하, 우→좌·상→하 등 네 방향(zig-zag 포함)의 경로를 사용해, 동일한 픽셀 집합을 서로 다른 순서로 스캔한다. 이렇게 하면 각 픽셀은 네 개의 서로 다른 “시간축” 상의 토큰으로 표현되며, 각 축은 다른 방향의 문맥을 담게 된다.
STEP2. Selective Scan with S6 (direction-wise sequence modeling)
각 스캔 경로마다 독립적인 S6 블록을 적용해, 길이가 $L$인 1D 시퀀스를 처리한다. 이때 각 시퀀스는 선형 시간 복잡도로 처리되며, S6의 특성상 각 위치의 hidden state는 “이전까지 지나온 모든 패치의 요약 정보”를 담게 된다. 네 방향 스캔을 병렬로 수행하므로, 구현 상으로도 GPU 친화적인 구조를 유지할 수 있다.
STEP3. Cross-Merge (2D reassembly & fusion)
네 개의 출력 시퀀스를 다시 2D 피처 맵으로 재배열한 뒤, 위치별로 네 방향 정보를 통합해 최종 출력 피처를 생성한다. 논문에서는 구체적인 결합 연산을 강조하기보다는, “네 개의 시퀀스를 2D 피처 맵으로 되돌려 병합함으로써 전역 문맥을 수집한다”는 점에 초점을 맞춘다.
이 과정을 거치면, 한 픽셀은 네 개의 스캔 경로를 통해 이미지 전체의 정보를 압축된 hidden state 형태로 전달받을 수 있다. 결과적으로 SS2D는 self-attention처럼 전역 receptive field와 동적 가중치를 가지지만, 스캔 경로를 따라 누적되는 선택적 상태 업데이트 덕분에 계산·메모리 복잡도가 토큰 수에 선형적으로 증가한다.
4) Accelerating VMamba
VMamba는 처음 설계된 vanilla VSS 블록만 썼을 때, Tiny 기준으로 22.9M 파라미터, 5.6G FLOPs에서 ImageNet‑1K Top‑1 82.2%를 달성하지만, 처리 속도가 426 img/s 수준에 그쳐 실서비스나 대형 다운스트림 태스크를 생각하면 다소 무거운 편이다. 이러한 문제를 해결하기 위해 본 논문에서는 몇 가지 가속화 기법을 제시한다.

Experiments
1) Image Classification

2) Object Detection and Semantic Segmentation

3) Discussion
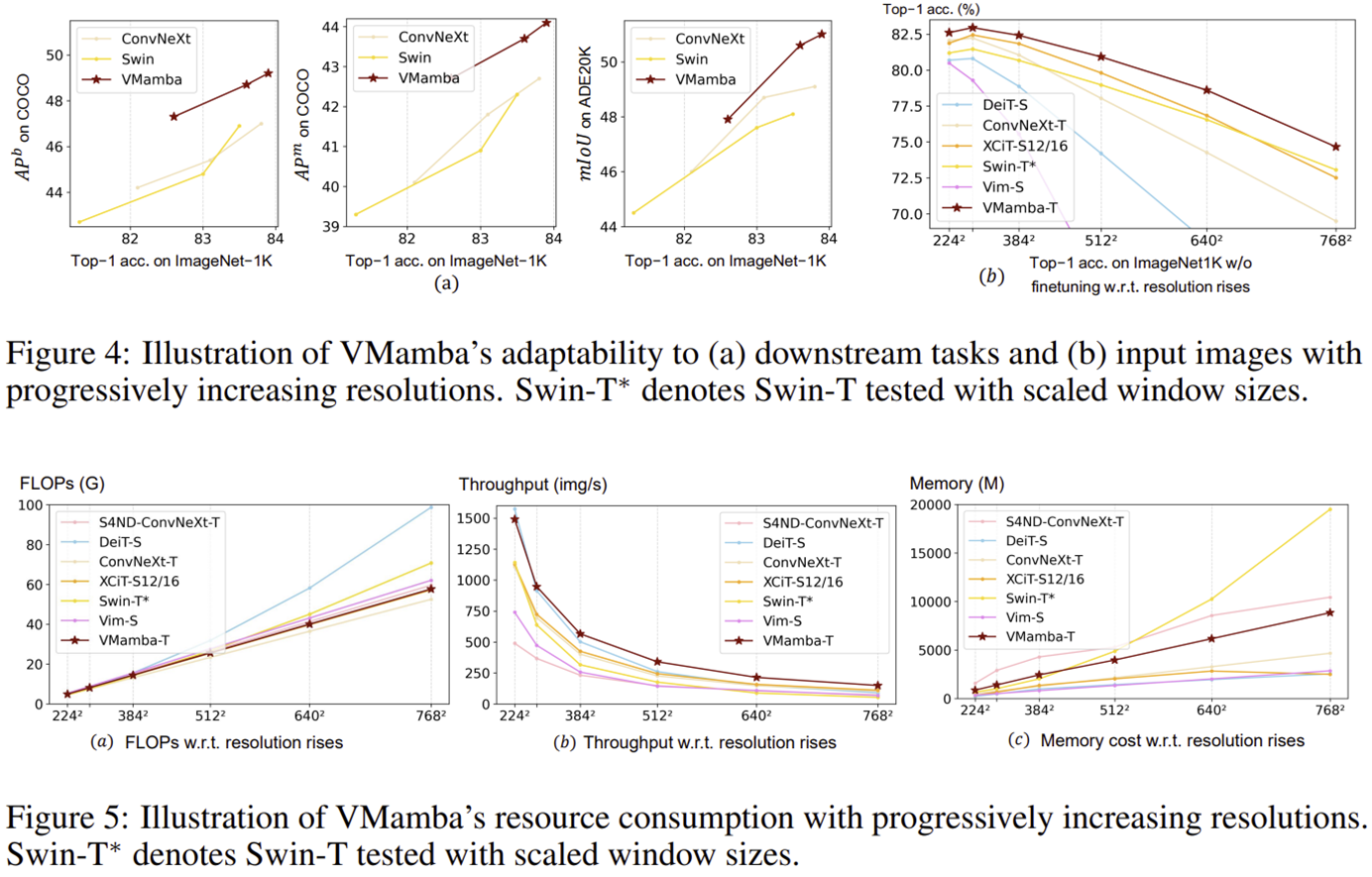
4) Anaylsis
4-1) Visualization of Activation Maps

4-2) Visualization of Effective Receptive Fields

4-3) Diagnostic Study on Selective Scan Patterns
