
안녕하세요. 오늘은 생체신호 중 가장 대표적인 EEG (Electroencephalography)을 CNN과 Vision Transformer를 결합하여 회귀 (regression) 성능을 향상시킨 EEGViT에 대해서 소개하도록 하겠습니다.
Background
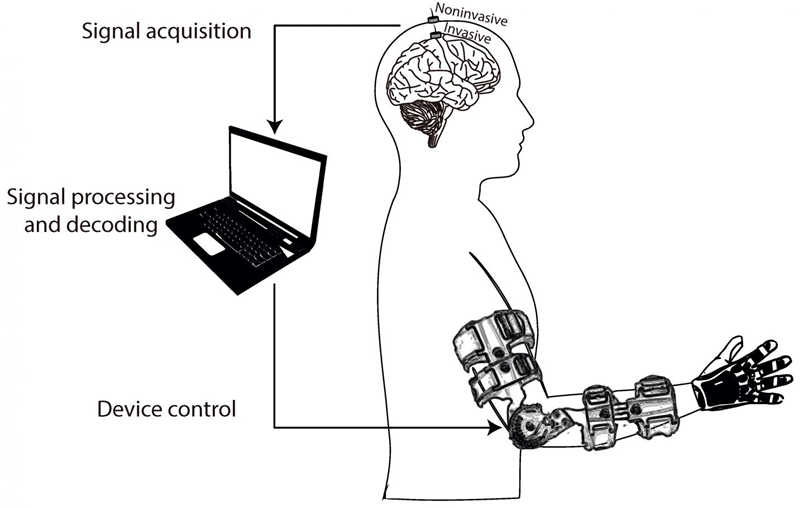
Brain-Computer Interface (BCI)는 위 그림과 같이 뇌와 외부 장비를 직접적으로 연결하여 인간과의 상호작용을 돕는 연구입니다. 위 그림과 같이 운동 재활 (Motor Reabiliation), 감정 인식 (Emotion Recognition), 그리고 인간-기계 상호작용 (Human-Machine Interaction; HMI)가 대표적으로 활용되는 분야입니다.

BCI 연구에서 가장 핵심이 되는 데이터가 바로 EEG (Electroencephalography)로 쉽게 생각하면 뇌의 전기적 신호라고 볼 수 있습니다. 보통 뇌의 전기적 신호를 얻기위해 가장 정확한 방법은 외과적 수술을 통해 뇌에 칩을 직접 심는 방법을 생각해볼 수 있습니다. 하지만, 이는 인간의 면역반응 및 이후 건강상태 악화 등의 이유로 좀 더 안전한 방법으로 뇌의 전기적 신호를 얻는 방법을 고려하였습니다. 이 방법이 바로 EEG이죠. 위 그림과 같이 뇌에 직접 심는 게 아니라 두개골의 겉에서 전기적 신호를 얻는 방법입니다. 하지만, 높은 임피던스로 인해 신호의 퀄리티가 떨어지거나 심리적인 요소로 인해 저희가 실험한 시뮬레이션에 해당하는 뇌파 정보가 제대로 추출되지 않을 가능성도 있기 때문에 이 EEG 신호를 정확하게 디코딩하고 분류하는 것은 굉장히 어려운 문제입니다.
그래도 CSP (Common Spatial Pattern), Filter Bank, CWT (Continuous Wavelet Transform), EWT (Empirical Wavelet Transform) 등 다양한 전통적인 기법을 활용하여 추출하고 SVM (Support Vector Machine) 또는 MLP (Multi-layer Perceptron)과 같은 분류기에 입력하는 방식은 적극적으로 활용되어 왔습니다. 하지만, 이러한 방법들은 task-dependent한 feature를 얻기 때문에 prior 정보가 필요하죠. 이러한 문제를 해결하기 위해 CNN 기반으로 제안된 ConvNet, EEGNet 등이 제안되어 지역적인 세부정보를 잘 추출함에도 불구하고 전체 시간에 걸쳐 전역적인 문맥 정보를 추출하지 못한다는 문제점이 있었습니다.
이러한 문제를 해결하기 위해 본 논문에서는 CNN으로부터 token을 추출한 뒤 ImageNet에 사전학습된 Vision Transformer (ViT)에 연결하는 EEGViT를 제안합니다. CNN을 통해 지역적인 디테일을 추출하고 ViT을 통해 전역적인 문맥 정보를 추출하는 것이죠. 이때, CNN으로는 2D 합성곱이 아니라 2개의 1D 합성곱으로 설계하여 시간축과 공간축에 대해 각각 합성곱을 적용하여 토큰을 추출합니다. 이렇게 얻은 토큰은 ViT에 입력되어 전역적인 문맥 정보를 활용하게 됩니다. 본 논문의 핵심적인 기여도 중 하나는 영상 분류를 위해 학습된 ViT를 생체신호 데이터는 EEG의 회귀문제에 사용하더라도 충분히 좋은 성능을 달성할 수 있다는 것을 실험적으로 보여주었다는 것 입니다.
Proposed Method: EEGViT
1) Structuring Images from EEG Time Series Data

본 논문에서는 EEG 데이터를 이용해서 시선 추적 (Eye Tracking)을 위한 네트워크를 제안하고자 하였습니다. 이는 결국 현재 EEG 신호가 화면 상에서 어떤 $x$ 축과 $y$ 축 좌표에 대응하는 지에 대한 회귀 문제를 푸는 것과 동일합니다. 이러한 데이터셋은 이미 EEGEyeNet이라는 논문에서 제시되었으며 그림 1은 이를 얻은 방법에 대해서 설명하고 표 1은 데이터셋의 전체 개수를 보여주고 있습니다.
2) Overall Architecture of EEGViT

2-1) Two-Step Convolution Block

이전에도 설명드렸다 싶이 본 논문에서 사용하는 CNN 파트는 두 단계로 구성된 합성곱 계층을 활용합니다. 이는 이전에 제가 설명드렸던 EEG Conformer와 거의 동일합니다. 표 2는 이를 설계하기 위한 상세한 하이퍼파라미터를 보여주고 있습니다. 이 과정을 간단하게 요약하면 다음과 같습니다.
STEP1. [Temporal 1D Convolution] 시간축에 대해 1D 합성곱 적용
STEP2. [Spatial 1D Convolution] 서로 다른 채널 사이의 상호작용을 이해하기 위해 공간축에 대해 1D 합성곱 적용
2-2) Transformer Block
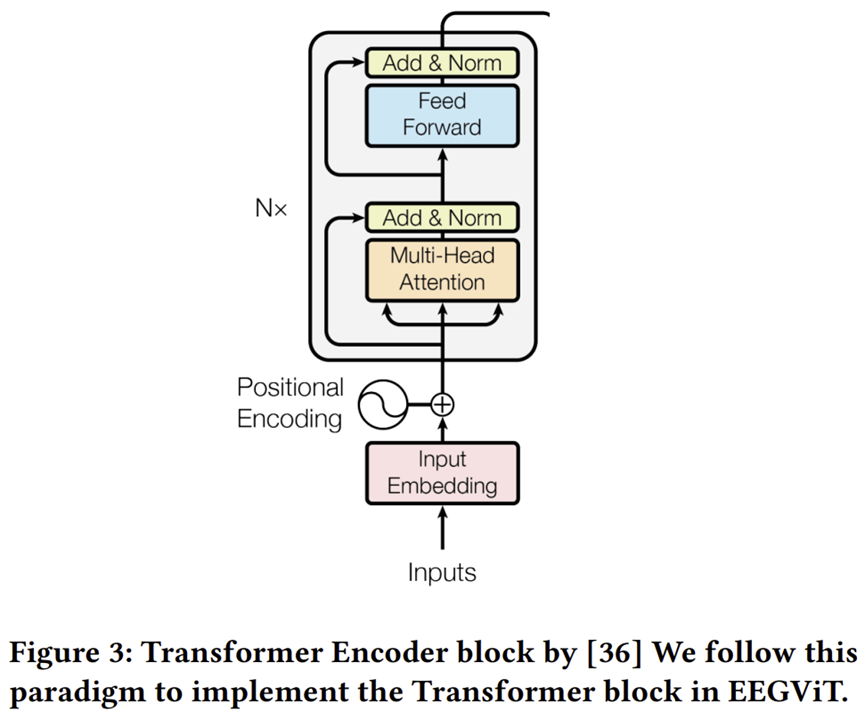

그림 3은 본 논문에서 사용하는 Transformer Block의 모습으로 기존의 ViT와 완전히 동일하게 구성되어 있습니다. 조금 더 자세히 설명하자면 표 3과 같은 셋팅으로 ViT-Base를 이용하였습니다.
3) Training
본 논문에서는 위와 같이 구성된 EEGViT를 학습하기 위해 MSE를 사용하였으며 RMSE를 performace metric으로 사용하였습니다. 그리고 총 15개의 에폭으로 매 iteration마다 64개의 배치 샘플을 무작위로 샘플링하여 학습을 진행하였습니다. 그리고 ImageNet-pretrained ViT를 사용하는 경우 학습률을 1e-4에서 시작하여 6번의 에폭마다 0.9씩 줄였습니다. 만약 ImageNet-non-pretrained ViT를 사용하는 경우 학습률을 1e-4로 고정하여 학습을 진행하였습니다.

표 5는 본 논문에서 비교한 모델들의 더 자세한 학습 하이퍼파라미터 표를 보여주고 있습니다.
Experiment Results
