
안녕하세요. 지난 포스팅의 [IS2D] Non-local Neural Networks (CVPR2018)에서는 semantic segmentation을 해결하기 위한 non-local network에 대해서 알아보았습니다. 이러한 개념은 향후 WACV2021에 게재된 Attentional Feature Fusion에 활용됩니다. 오늘은 기존의 InceptionNet과 ResNeXt와 같은 모델 등에서 제안한 multi-branch network를 semantic segmentation에 적용한 SegNeXt에 대해서 소개하도록 하겠습니다.
Background
기본적으로 의미론적 영상 분할 (Semantic Segmentation)은 영상 내의 각 픽셀에 대해 어떤 카테고리 레이블에 속하는 지 예측하는 dense prediction 문제라고 볼 수 있습니다. 이를 통해 사용자는 전체 영상 내에 완벽한 이해 (complete understanding)를 제공해주죠. 이러한 문제는 자율주행, 이상탐지, 그리고 의료영상 등과 같은 정말 다양한 도메인에서 필수 기술로서 자리매김하고 있습니다.
이를 위해 제안된 다양한 모델들이 있습니다. 대표적으로 CNN-based 모델들은 inductive bias를 기반으로 설계되어 상대적으로 적은 양의 데이터로도 충분히 좋은 성능을 얻을 수 있다는 장점은 있으나 global information을 활용하지 못합니다. 대표적으로 FCN (CVPR2016)과 DeepLab Series (ICLR2015, TPAMI2017, arxiv2017, ECCV2018) 등이 있습니다. 그와 대척점인 Transformer-based 모델들은 대용량의 데이터 (ImageNet 또는 JFT-300M)으로 학습되어 self-attention 기반의 강력한 인코더 성능을 보장해주지만 고해상도 영상에서의 높은 연산량이 큰 문제가 있습니다. 대표적으로 SETR (CVPR2021) 그리고 SegFormer (NIPS2021) 등이 있습니다.
이러한 모델들은 모두 영상 분할 분야에서 높은 성능을 달성하였습니다. 본 논문에서는 이러한 원인으로 다음을 꼽습니다.
1) Strong Backbone Encoder
2) Multi-scale Information Interaction
3) Spatial Attention
4) Low Computational Complexity
그렇다면 이 4가지 요인을 하나로 묶은 새로운 인코더-디코더 구조의 영상 분할 모델을 만들 수 없을까요? 본 논문에서는 이를 통해 새로운 SegNeXt라는 모델을 제안합니다. 이는 대부분 convolution 연산으로만 구성되어 있으며 기존의 InceptionNet 그리고 ResNeXt와 같은 모델들의 multi-branch 구조를 채택하여 영상 분할에 적합한 모델에 설계하였습니다. 이러한 multi-branch 구조를 채택하여 multi-scale convolutional feature들이 spatial attention으로 적절하게 결합되어 상대적으로 낮은 연산량으로도 높은 성능을 달성하게 되었습니다.

SegNeXt
1) Convolutional Encoder

본 논문에서는 기본적으로 self-attention이 없는 ViT 형태의 pyramid structure를 채택하여 인코더를 설계합니다. 이제 인코더에 multi-scale feature를 적용하기 위해 설계된 Multi-Scale Convolutional Attention (MSCA) 모듈을 보도록 하겠습니다. 이는 굉장히 단순한 구조로 되어 있어 쉽게 이해할 수 있을 겁니다. 기본적으로 $1 \times 1$ convolution을 제외한 각 branch들은 depth-wise strip convolution으로 구성되어 local information을 하나로 묶어주고 multi-scale 특징을 효율적으로 추출할 수 있게 되었습니다. 해당 구조는 InceptionNetV4에서 확인할 수 있는 구조입니다. 그러면 원래 $21 \times 21 = 441$개의 파라미터를 사용해야했던 커널이 $21 + 21 = 42$개로 감소하여 약 10%의 파라미터로 모델을 설계할 수 있기 때문에 굉장히 공간 효율적이라고 볼 수 있습니다. 또한, 이전 논문에 따르면 큰 커널 사이즈로 구성된 strip convolution을 이용하면 standard depth-wise convolution을 근사시킬 수 있다고도 하여 본 논문에서는 각 branch의 커널 크기를 각각 7, 11, 21과 같은 큰 값으로 채택하였습니다. 그리고 위 과정으로 수식으로 작성하면 다음과 같습니다.

그림 2의 (a)를 여러 층으로 쌓아 4개의 계층으로 구성된 hierarchical structure로 만들어 spatial resolution을 점점 감소시키면 최종적으로 본 논문에서 제안하는 MSCAN을 만들 수 있습니다. 그리고 각 down-sampling block은 커널 크기 3에 stride 2와 batch normalization이 적용되어 있습니다.
2) Decoder
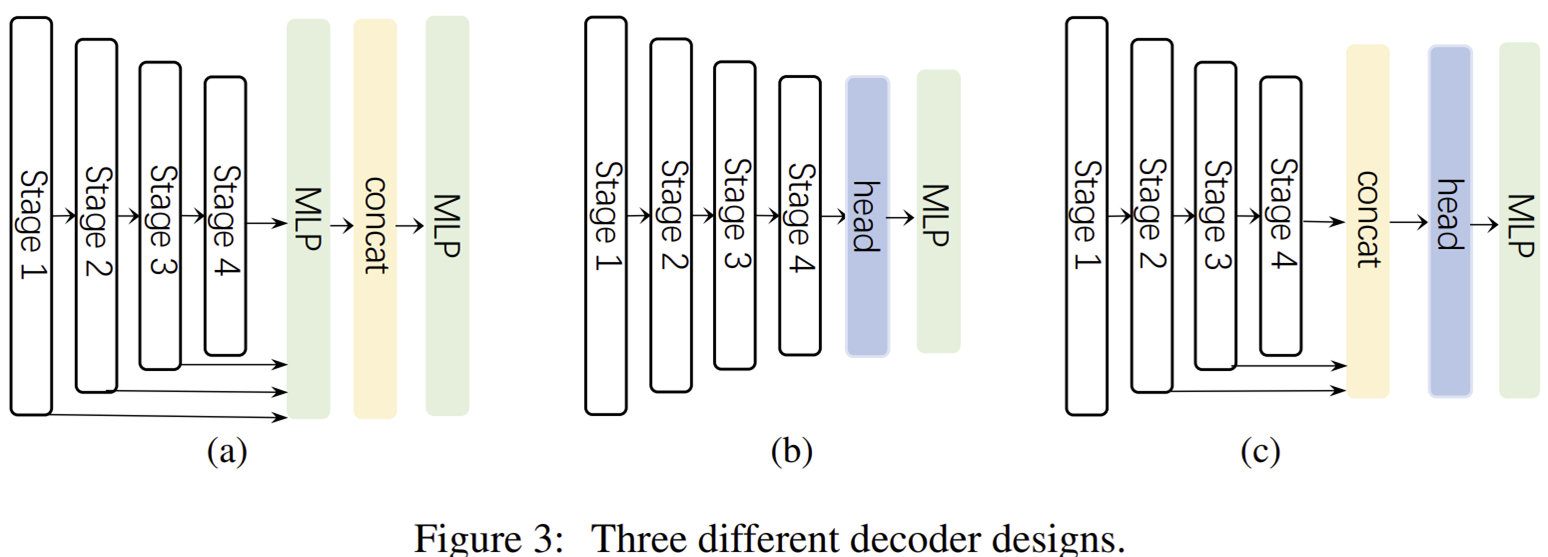
마지막으로 디코더는 그림 3에서 (c)와 같은 형태를 채택하였으며 기존 디코더 구조 중 Hamburger라는 모델의 구조를 활용했다고 합니다. 여기서 Stage 1의 출력은 사용하지 않았는데 이는 너무 low-level information이 포함되어 있으며 높은 해상도를 가지고 있어 효율성과 성능을 감소시킨다고 합니다. 참고로 (a)는 SegFormer 그리고 (b)는 기존의 CNN-based 모델이 채택하는 디코더 구조입니다.
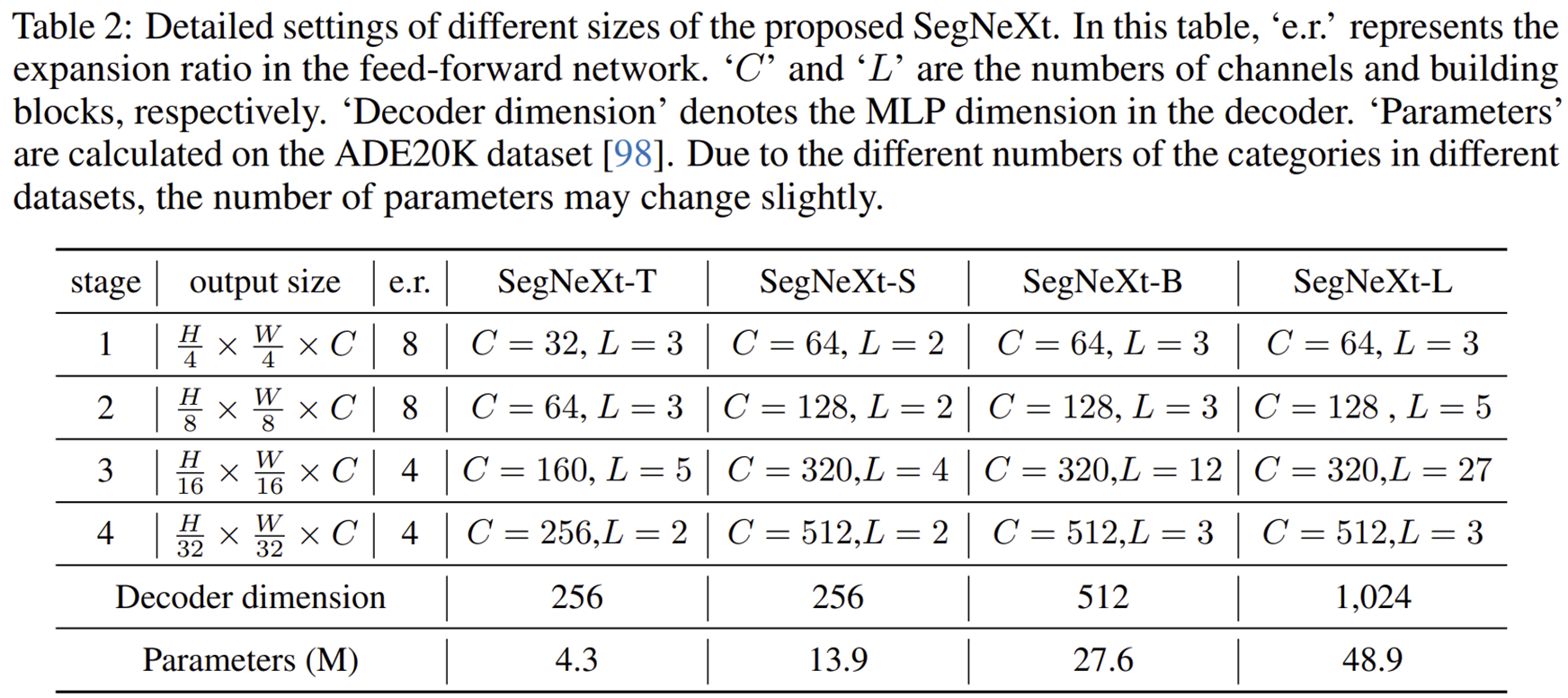
3) Variants of SegNeXt
Experiment Results
1) Quantitative Results
1-1) ImageNet-1K Classification

1-2) iSAID Semantic Segmentation

1-3) ADE20K & CityScapes & COCO-Stuff Semantic Segmentation

1-4) PASCAL-VOC Semantic Segmentation

1-5) CityScapes Semantic Segmentation between Real-Time Models

1-6) PASCAL-Context Semantic Segmentation

2) Qualitative Results

3) Ablation Study
3-1) Different Attention Mechanism

3-2) Design of MSCA

3-3) Different Decoder Structure
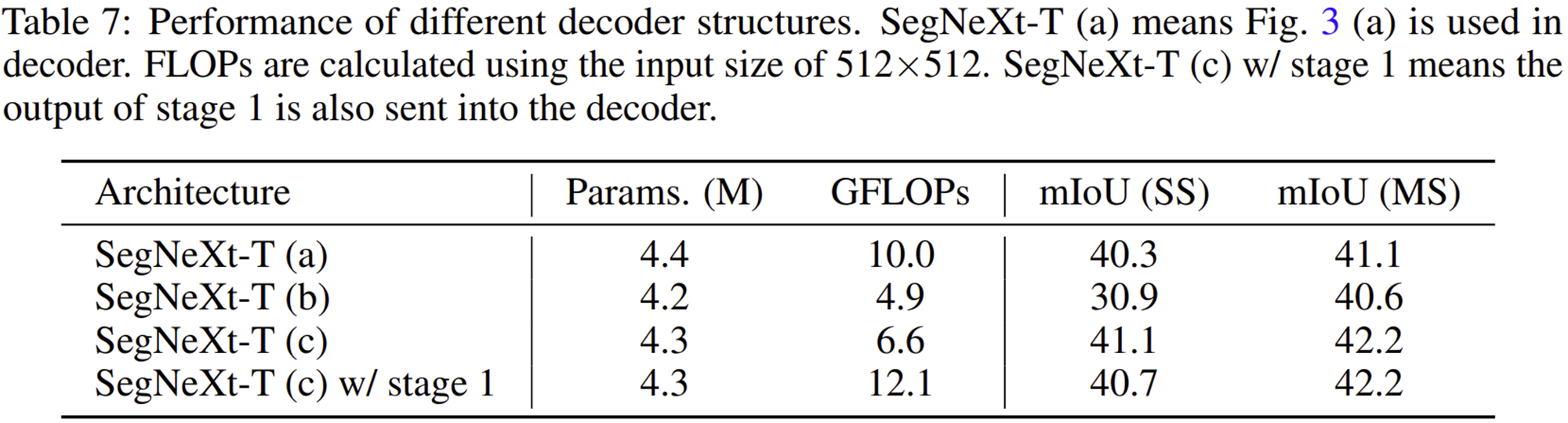
3-4) Importance of MSCA
