안녕하세요. 지난 포스팅의 [Forgery Detection & Segmentation] FaceForensic++: Learning to Detect Manipulated Facial Images (ICCV2019)에서는 Face Forgery Detection에 특화된 데이터셋인 FaceForensic++ (FF++)에 대한 설명을 진행하였습니다. 오늘은 FF++를 활용하여 Face Forgery Detection을 수행하는 $F^{3}$-Net에 대해서 소개하도록 하겠습니다.
Background
이전 포스팅에서도 설명드렸지만 기본적으로 컴퓨터 비전 기반 얼굴 인식 알고리즘이 크게 성공했기 때문에 얼굴을 변조하는 방법 역시 덩달아 발전하는 계기가 마련되었습니다. 이로 인해 얼굴을 변조하는 방법이 매우 쉬워지고 이를 악용하는 사람들이 발생하여 범죄 및 정치적 혼란을 초래할 가능성이 높아졌죠. 따라서, 이러한 악의적으로 조작된 영상을 조기에 탐지하는 것이 향후 중요한 연구주제가 될 것 입니다.
물론 이전에도 조작된 영상을 탐지하기 위해 Local Pattern Analysis, Noise Variance Evaluation, Steganalysis Features 등과 같은 hand-crafted feature를 활용하기도 하였습니다. 하지만, 이러한 방법들은 더 정교해지는 조작 영상에 대응이 불가능하고 저해상도 영상에서도 낮은 정확도를 보이게 되었습니다. 따라서, 이러한 일반화 성능을 향상시키기 위해 Convolution Neural Network (CNN)을 활용하게 됨으로써 feature space에서 위조된 흔적을 추출하는 것이 가능해졌습니다.
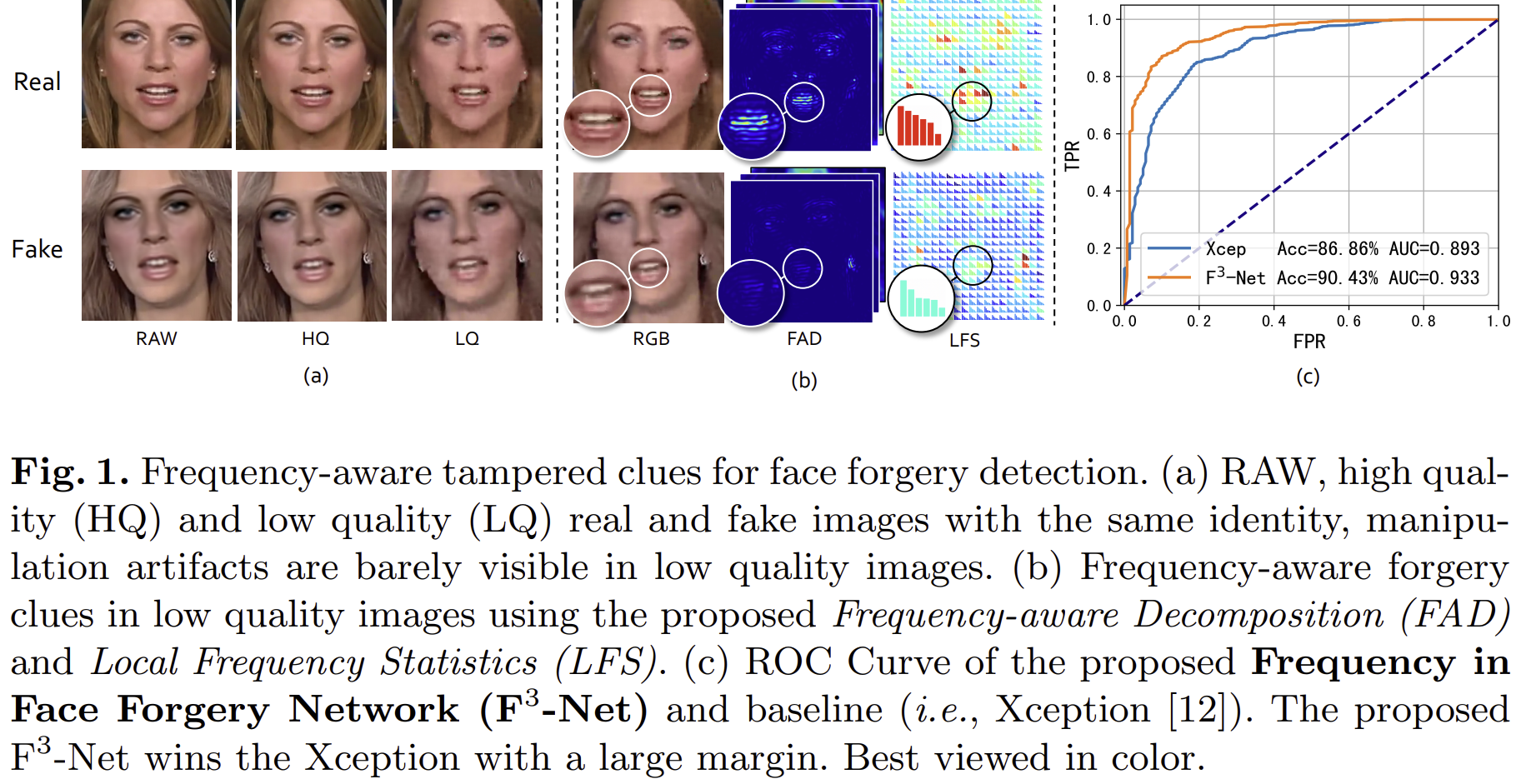
본 논문에서는 실제 영상과 위조 영상을 visual quality (raw, HQ, LQ)별 차이와 주파수 도메인으로 변환했을 때 발생하는 차이점을 설명합니다.
1) 위조된 영상의 퀄리티가 낮아질 수록 높은 퀄리티의 영상에 비해 위조된 부분을 쉽게 판단할 수 없습니다. 이는 이미 이전 논문인 FF++에서 언급된 문제였죠. 실제로 User case에서도 LQ에서의 성능이 가장 낮고 Raw에서 성능이 가장 높았던 것을 기억하실 겁니다. 그림 1 (a)가 그 모습을 보여주고 있습니다.
2) 이제 실제 영상과 위조 영상을 주파수 도메인으로 변환해서 분석해보도록 하죠. 여기서는 기본적으로 모두 이산 코사인 변환 (Discrete Cosine Transform; DCT)를 사용하여 본 논문에서 제안된 두 가지 모듈인 FAD와 LFS를 기반으로 설명합니다. 비록 영상 도메인에서는 LQ 영상일 수록 위조 흔적을 찾기 어려웠지만 주파수 도메인에서는 그 경향이 뚜렷하게 나타나는 것을 볼 수 있습니다. 본 논문에서는 이와 같이 실제 영상과 위조 영상 사이에서 발생하는 주파수 도메인에서의 이상한 주파수 분포를 기반으로 모델을 설계하게 됩니다.
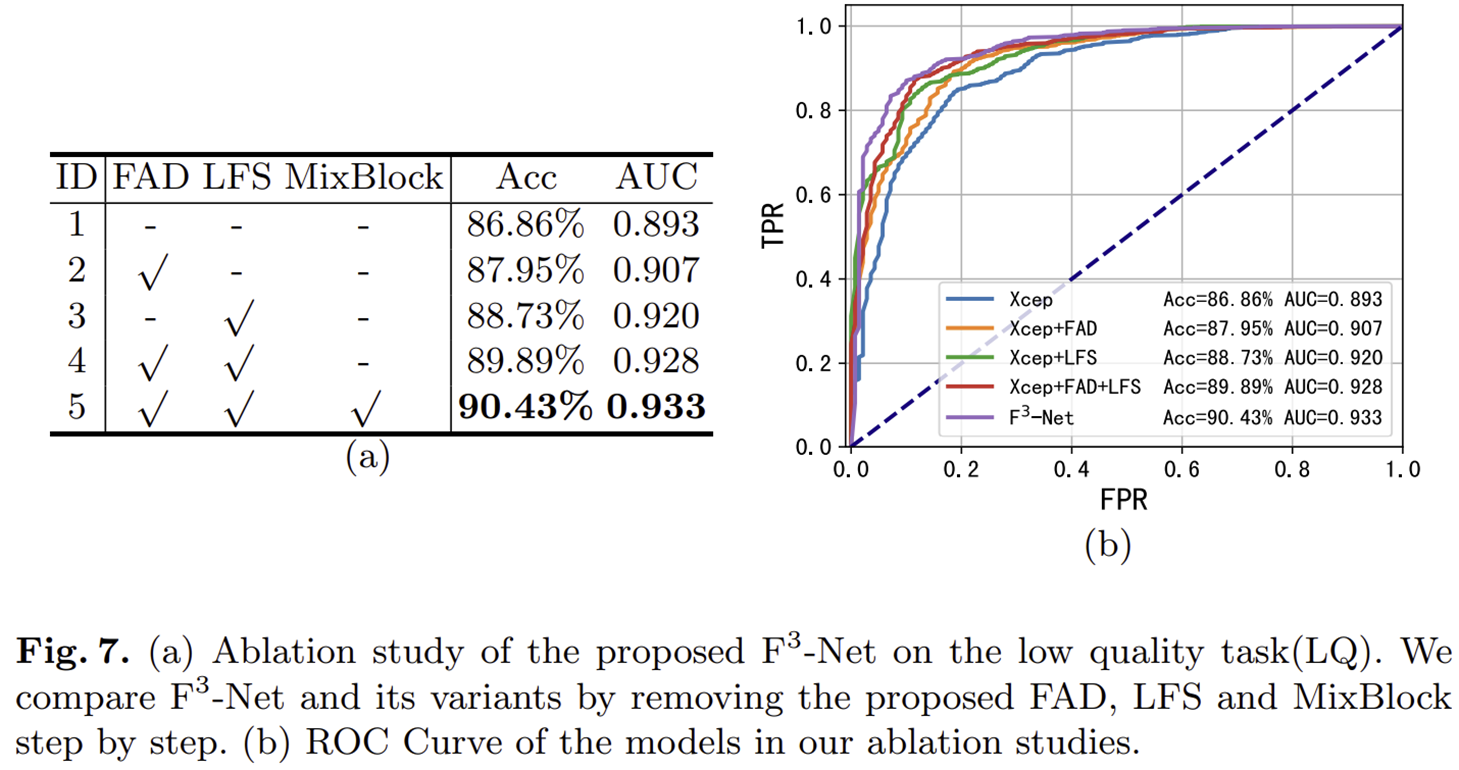
3) 그림 1 (c)에서는 본 논문에서 제안하는 모델인 $F^{3}$-Net을 적용했을 때 XCeption과의 성능 비교를 ROC curve를 이용해서 보여주고 있습니다. 결과적으로 정확도와 AUC가 큰 폭으로 향상된 것을 볼 수 있습니다.
Proposed Method
1) Overall Framework

그림 2는 본 논문에서 제안하는 $F^{3}$-Net의 전체적인 구조 입니다. 기본적으로 FAD와 LFS라고 불리는 두 개의 stream이 병렬적으로 구성된 뒤 CNN을 통해 추출된 특징을 MixBlock까지 통과시켜 최종 real/fake를 예측하게 됩니다.
2) FAD: Frequency-Aware Decomposition
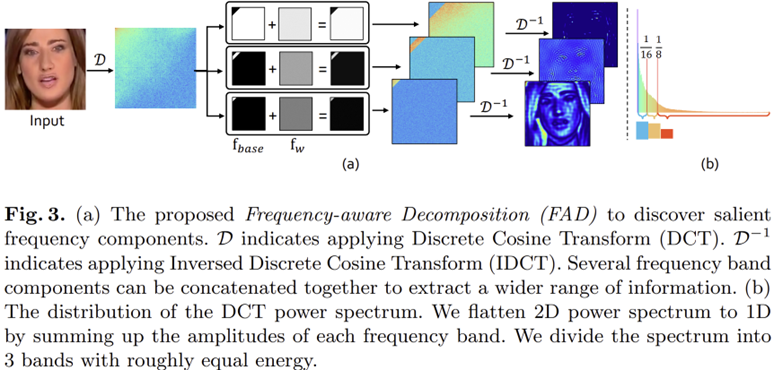
그림 3은 본 논문의 첫번째 모듈은 Frequency-Aware Decomposition (FAD)의 전체적으로 알고리즘입니다. 전체적인 방식은 매우 간단합니다. 입력 영상이 주어졌을 때 이를 DCT를 이용해 주파수 공간으로 변환합니다. 이때, DCT의 특성 상 대부분의 에너지는 저주파에 몰려 왼쪽 상단에 존재하게 됩니다. 이러한 점을 해결하기 위해 그림 3의 (b)와 같이 저주파/중간 주파수/고주파로 나눌 때 각 영역이 동일한 양의 에너지를 가질 수 있도록 영상 별로 adaptive하게 영역을 나누어줍니다. 이때 나누는 마스크는 기본적으로 이진 마스크로 $\mathbf{f}_{\text{base}}$로 정의되며 여기에 추가적으로 손실함수의 gradient에 영향을 받는 learnable mask인 $\mathbf{f}_{w}$도 더해주어 각 주파수 간 중요도도 얻을 수 있게 만들어줍니다. 이를 수식화하여 정리하면 다음과 같이 $i = 1, 2, \dots, N$에 대해서 출력 영상 $\mathbf{y}_{i}$를 얻을 수 있습니다.
$$\mathbf{y}_{i} = \mathcal{D}^{-1} \{ \mathcal{D} \{ \mathbf{x} \} \odot [\mathbf{f}^{i}_{\text{base}} + \sigma (\mathbf{f}^{i}_{w})] \}$$
여기서 $\mathcal{D} \{ \cdot \}$과 $\mathcal{D}^{-1} \{ \cdot \}$은 각각 DCT와 inverse DCT를 의미합니다. 그리고 $\sigma (\cdot)$은 learnable mask $\mathbf{f}_{w}$의 range를 $[-1, +1]$로 맞추어주는 Tanh 함수입니다.
3) LFS: Local Frequency Statistic
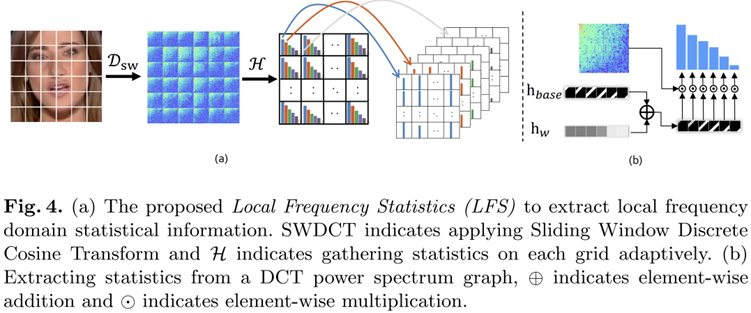
FAD는 영상에 대한 전체적인 주파수 경향성을 이해할 수 있지만 아쉽게도 주파수 정보를 직접적으로 활용하지 못한다는 문제점이 있습니다. 본 논문에서는 이러한 문제를 해결하기 위해 추가적으로 그림 4와 같은 LFS라는 방법을 추가적으로 제안합니다. 그림 2 기준으로는 아래에 있습니다.
방식은 매우 간단합니다. 먼저 지역적인 주파수 경향성을 파악하기 위해 Sliding Window 방식으로 DCT를 수행하여 각 패치 간 주파수를 추출합니다. 이를 $\mathcal{D}_{\text{sw}} \{ \cdot \}$이라고 부르죠. 다음으로는 각 패치별 주파수의 통계량을 추출합니다. 이를 위해 FAD와 유사하게 주파수를 다시 등간격으로 쪼개고 각 주파수별 전체 에너지량을 히스토그램화 하여 정리하게 됩니다. 이를 $\mathcal{H} (\cdot)$로 표현됩니다. 각 패치 별로 쪼개진 주파수의 개수가 $M$개라고 할 때 총 $M$개의 주파수 통계량을 각각 하나의 채널에 묶어 표현하여 multi-channel feature map으로 구성해줍니다. 이 과정이 LFS이죠. 이때. 그림 4의 (b)는 다음과 같이 수식으로 표현됩니다.
$$\mathcal{q}_{i} = \log_{10} || \mathcal{D}(\mathcal{p}) \odot [ \mathbf{h}^{i}_{\text{base}} + \sigma (\mathbf{h}^{i}_{w}) ] ||_{1} $$
여기서 $\log_{10} ( \cdot )$은 FAD에서 설명드렸다싶이 주파수 밴드별로 몰린 주파수의 에너지량이 너무 상이하기 때문에 이를 어느정도 밸런스를 맞추어주기 위해서 적용하였습니다.
4) Two-Stream Collaborative Learning Framework
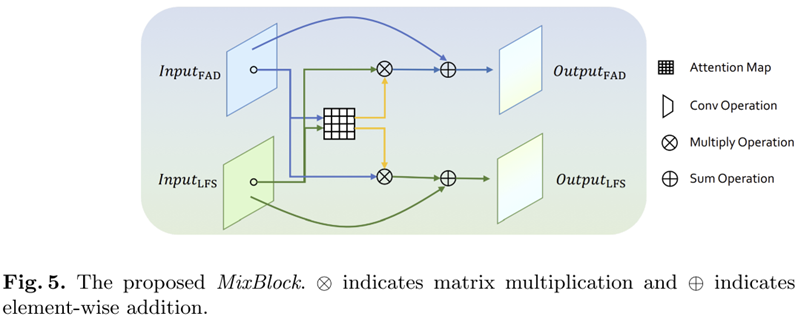
마지막으로 FAD와 LFS 단계에서 추출한 두 특징을 서로 cross-attention을 수행하기 위해 MixBlock인 그림 5를 제안합니다. 본 논문에서는 ImageNet에 사전학습된 총 12개의 블록으로 구성된 Xception 모델을 backbone 모델로 사용하였습니다. 실험적으로 7번과 12번 블록에서 MixBlock을 사용했을 때 성능이 가장 높게 나왔다고 하네요. 손실함수는 이진 분류를 위한 cross-entropy loss를 사용하였으며 end-to-end 방식으로 학습을 진행하였다고 합니다.
Experimental Settings
1) Dataset
본 논문에서 사용한 데이터셋은 FF++ 입니다. 이전 포스팅에서 설명드렸다싶이 총 1,000개의 비디오가 존재하며 720 : 140 : 140 의 훈련 : 검증 : 시험의 비율로 나누었습니다. 이때 사용한 위조 방식들은 DeepFake, FaceSwap, Face2Face, NeuralTextures을 사용하였습니다. 따라서, 총 데이터셋은 5,000개의 비디오입니다. 각 비디오는 모두 300 ~ 700개의 프레임으로 구성되었으므로 본 논문에서 학습할 때는 각 비디오 별로 270개의 프레임을 무작위로 선택하여 학습을 진행하였습니다. FF++에서 설명한 것과 마찬가지로 얼굴부분만 크롭한 뒤 $299 \times 299$ 크기로 resize하여 학습을 진행하였습니다.
2) Implementation Details
본 논문에서는 ImageNet에 사전학습된 Xception을 사용하였으며 새롭게 추가된 블록들은 모두 무작위로 초기화되었습니다. SGD (momentum 0.9 & learning rate 0.002)를 통해 학습되었으며 learning rate scheduler로 cosine learning rate scheduler를 사용하였습니다. 128개의 배치 사이즈로 총 150k번의 iteration으로 학습을 진행하였다고 하네요.
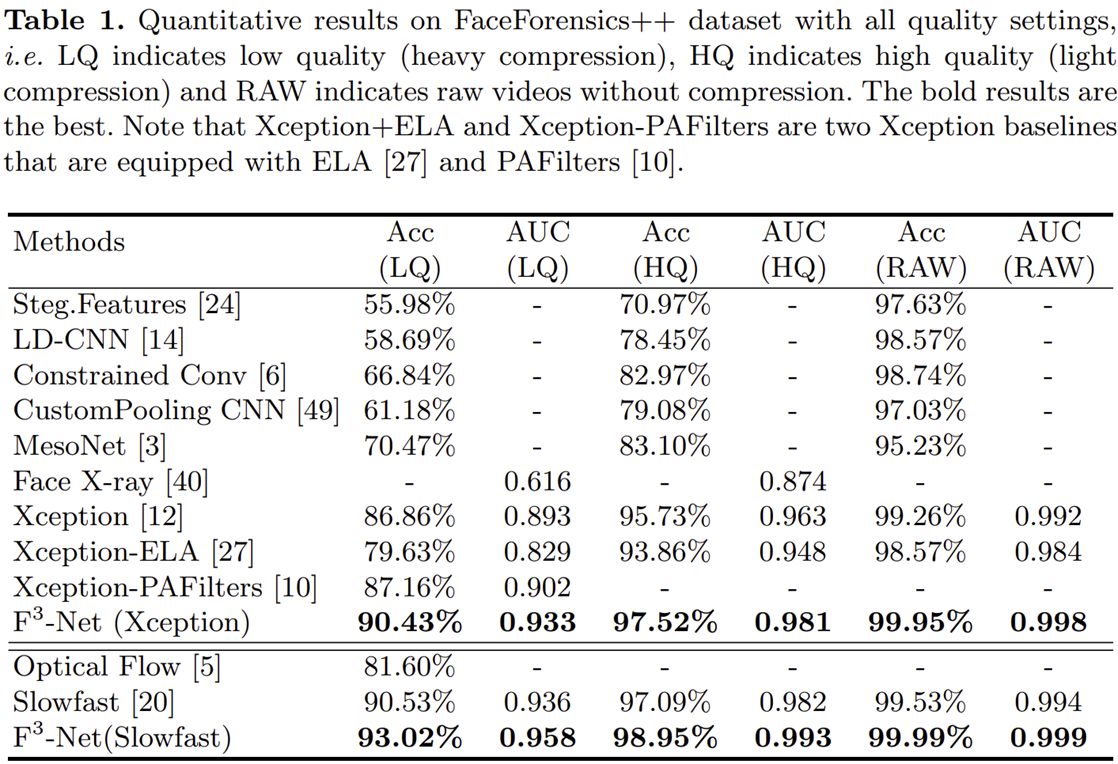
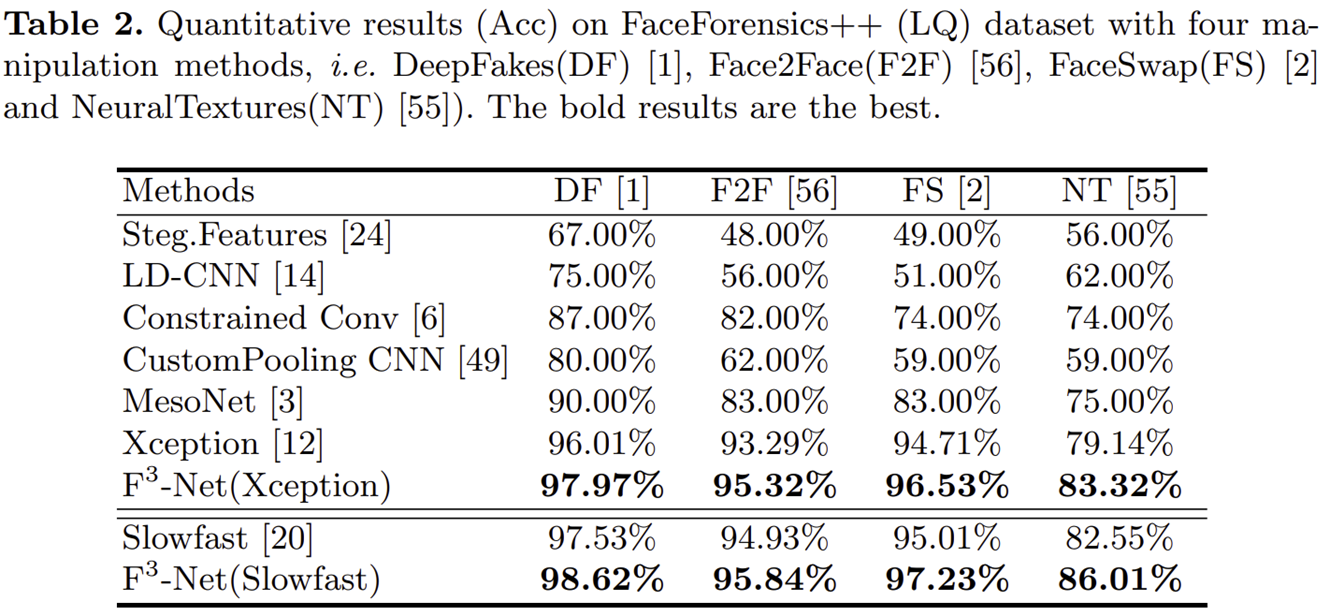
3) Comparing with Previous Works
4) Ablation Study