
안녕하세요. 오늘부터 새로운 주제인 [Forgery Detection & Segmentation]에 대해서 중요한 논문들 위주로 리뷰를 진행해보도록 하겠습니다. 얼굴 위조 (Face Forgery) 탐지의 가장 핵심 데이터셋 중 하나인 FaceForensic++ (FF++)에 대한 간단한 설명을 하도록 하겠습니다. 오늘 설명할 데이터셋인 FF++는 ICCV2019에 게재된 논문에서 참고하였습니다. (제목 참고)

기본적으로 위조는 두 가지로 나뉘게 됩니다. 위 그림에서 왼쪽과 같이 사진에서 없던 객체를 새로 만드는 splicing, 동일한 사진에 존재하는 객체를 여러 개 복사 붙혀넣기하는 copy-move, 그리고 splicing과 반대로 객체를 없애는 removal가 포함된 scene forgery image가 가장 대표적입니다. 이는 어도비 포토샵과 같은 기본적인 편집툴에서 수행될 수 있는 편집 방법들로 foreground segmentation에 속한다고 보시면 될 거 같습니다.
또한, 오른쪽 사진과 같이 사람의 얼굴에 집중하여 표정 및 얼굴 자체를 바꾸는 위조인 face forgery detection이 있습니다. 이는 대부분의 논문들에서 어차피 얼굴에 위조가 되어있다고 가정하기 때문에 segmentation보다는 위조 영상인지 실제 영상인지에 대한 이진 분류 (binary classification)의 형태로 문제를 해결합니다.
본 논문에서는 오른쪽 사진과 같은 face forgery detection에 집중하여 문제를 해결하고자 합니다. 최근 다양한 분야에서 아주 쉽게 사람의 얼굴을 바꾸거가 표정을 바꾸는 등 위조를 수행하는 것이 매우 쉬워지고 있습니다. 이는 실제로 불법성인물 및 정치적인 목적으로 활용되는 등 범죄에 활용될 가능성이 매우 높은 분야이기에 이를 탐지하는 것이 매우 중요하겠죠.

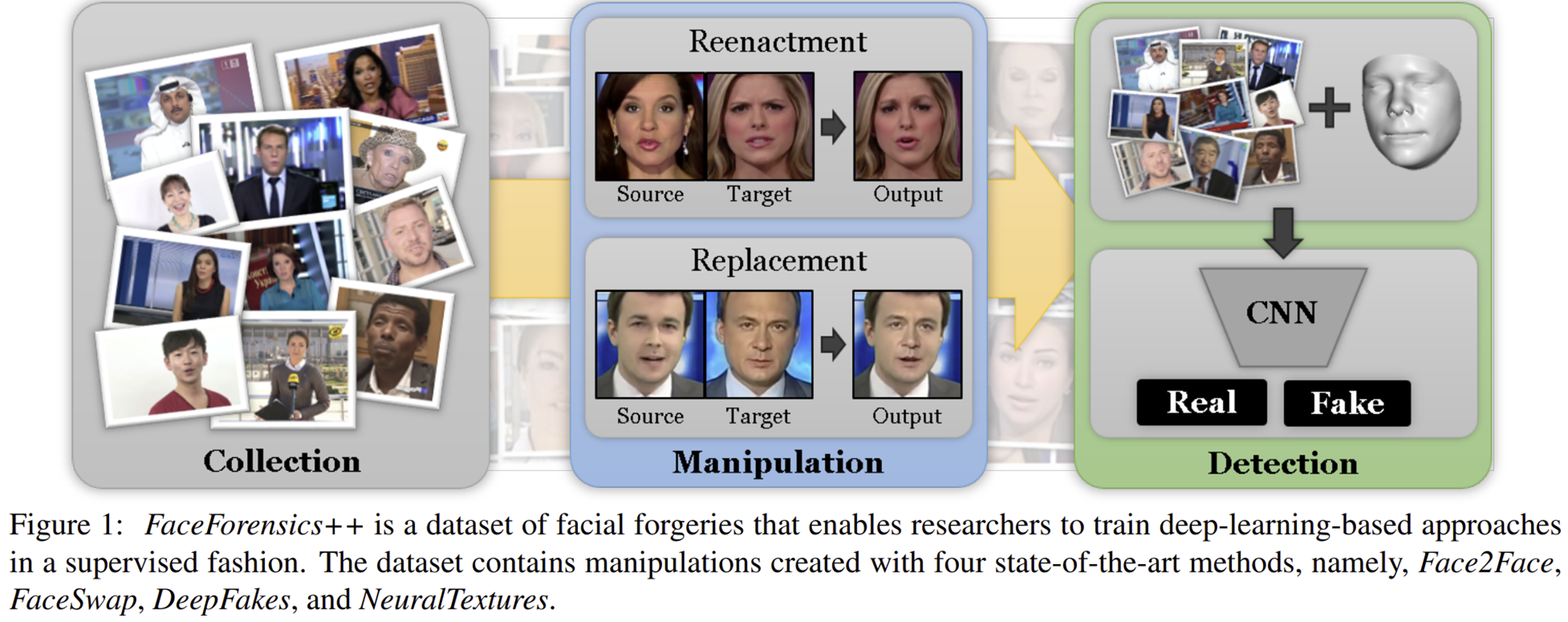
기본적으로 얼굴을 위조하는 방식은 그림 2와 같은 프로세스를 따르게 됩니다. 먼저 얼굴을 인식하여 mesh 데이터를 얻는 face reconstruction을 수행하게 됩니다. 다음으로 identity swap에서는 사람의 얼굴 자체를 바꾸게 됩니다. 이는 대표적으로 DeepFake 및 FaceSwap 같은 방법이 있습니다. 또는 facial reenactment와 같이 얼굴의 표정만 따라서 바꾸게 할 수도 있죠. 이는 대표적으로 Face2Face 및 NeuralTexture와 같은 방법들이 있습니다.
본 논문에서는 이와 같은 위조 방식을 탐지할 수 있는 딥 러닝 기반의 자동화된 프로세스를 제공합니다. 이를 통해, 인간의 인지 능력보다 더 높은 성능을 달성하였습니다. 또한, 제일 중요한 것은 FaceForgery++라는 대규모 데이터베이스를 구축하여 2019년부터 2024년까지 꾸준히 활용되고 있다는 점 입니다. 여기서 사용된 위조 방식은 위에서 언급한 DeepFake, FaceSwap, Face2Face, NeuralTexture를 사용하였습니다.
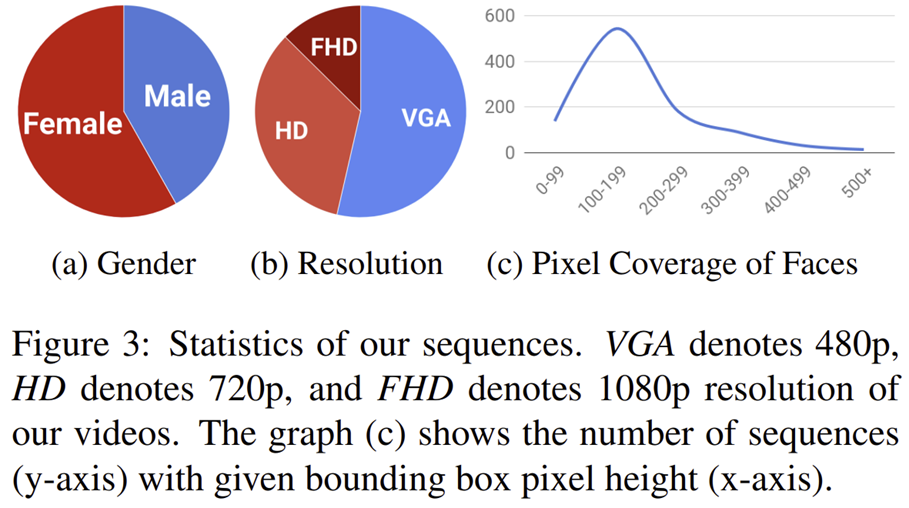
그림 3은 수집된 데이터셋에 대한 전체적인 분포도 입니다. 얼굴 위조 영상을 얻기 위해 본 논문에서는 1,000개의 유튜브 비디오를 수집하였습니다. 이는 대략 509,914개의 영상과 동일하다고 하네요. 그리고 face occlusion되는 경우도 제외시켰다고 하였습니다. 그리고 각 훈련, 검증, 시험 데이터셋은 720개, 140개, 140개로 나누었습니다. 여기서 좀 더 실제상황을 연출시키기 위해 Raw (lossless), High Quality (HQ; C23) , Low Quality (LQ; C40)으로 나누어 추가 데이터셋을 구성하였습니다. 다음으로 해당 실제 얼굴 비디오에DeepFake, FaceSwap, Face2Face, NeuralTexture를 사용하여 실제 : 위조 = 1 : 4 비율을 가지는 데이터셋을 만들었습니다. 따라서 총 비디오는 5,000개로 대략 2M개의 영상을 얻을 수 있죠. 1.3M 개의 데이터셋인 ImageNet보다 훨씬 더 많은 것을 볼 수 있죠.
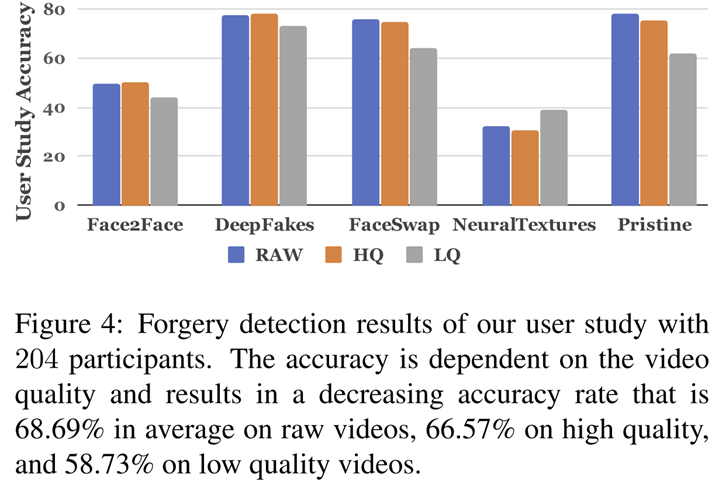
그림 4는 인간이 직접 각 위조 방법 및 실제 영상을 분류했을 때 얻은 성능 평가를 보여주고 있습니다. NeuralTexture를 제외하고는 모두 LQ 영상에 대해서 성능이 많이 떨어지는 것을 볼 수 있죠. 그리고 아무리 높아도 최대 80%의 성능을 얻게 됩니다.
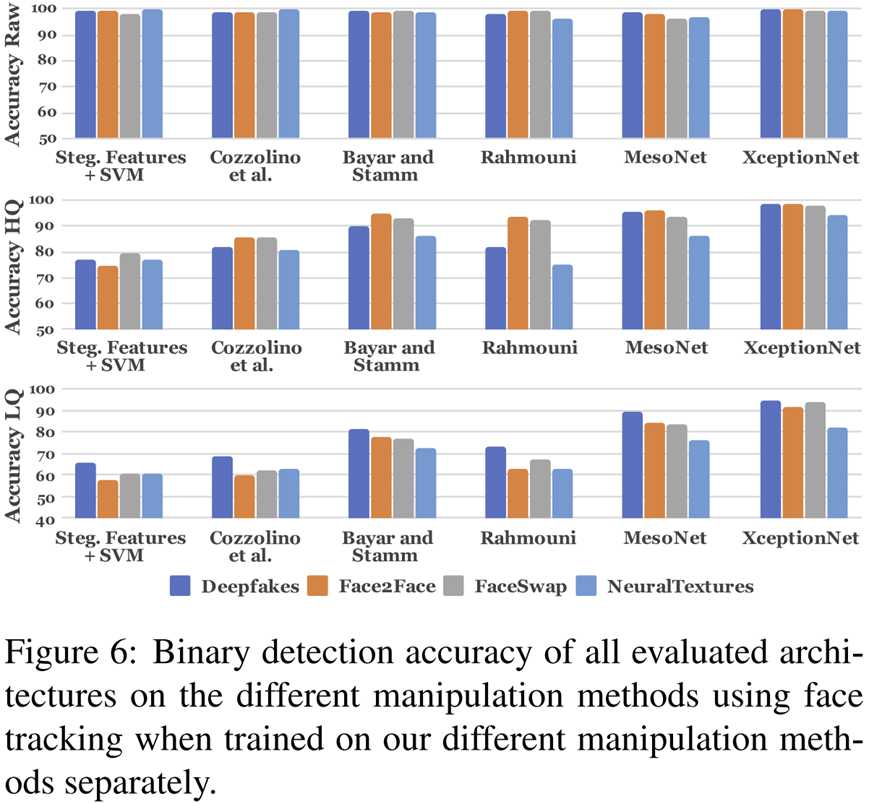
하지만 본 논문에서 사용하는 딥 러닝 기반 방법들을 이용하면 인간의 분류 성능를 훨씬 상회하여 Raw 퀄리티 영상에서는 거의 100%의 정확도를 보여주고 있죠. 이중에서 Xception은 제가 이전에 작성한 포스팅을 참고해주시면 감사하겠습니다.
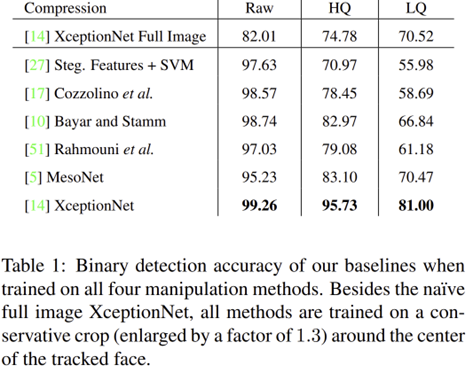
표 1에서 첫번째 행인 XceptionNet Full Image는 영상 전체를 입력했을 때 분류의 성능을 보여주고 있습니다. 기본적으로 "얼굴"을 위조했다는 사실은 저희가 이미 알고 있기 때문에 전체 영상을 사용하지 않고 얼굴만 따로 잘라서 입력하면 성능이 오를 것으로 예상할 수 있죠. 이는 실제로 얼굴만 잘라서 입력했을 때 마지막 행의 XceptionNet과 같이 LQ 기준으로 약 10%의 성능이 더 향상되었습니다. 본 데이터셋을 얻는 방법과 전처리 방법 (얼굴인식 및 cropping) 및 훈련/검증/시험 데이터셋 인덱스는 저자의 깃허브에 자세히 설명되어 있으니 참고바랍니다.
GitHub - ondyari/FaceForensics: Github of the FaceForensics dataset
Github of the FaceForensics dataset. Contribute to ondyari/FaceForensics development by creating an account on GitHub.
github.com