안녕하세요. 지난 포스팅의 [IC2D] Learnable Transferable Architecture for Scalable Image Recognition (CVPR2018)에서는 NAS의 발전된 모델인 NASNet에 대해서 소개시켜드렸습니다. 오늘은 CondenseNet과 마찬가지로 DenseNet의 변형 모델인 PeleeNet에 대해서 소개시켜드리도록 하겠습니다.
Background
지금까지 저희는 MobileNet V1, ShuffleNet, MobileNet V2, NASNet에 대해서 알아보았습니다. 이러한 모델들의 특징은 "효율성 (efficiency)"을 강조한 방법들이죠. 특히, MobileNet과 ShuffleNet은 Depthwise Separable Convolution을 사용하여 약 8 ~ 9배만큼의 속도가 빨라지게 됩니다. 하지만 2018년 당시에는 Group Convolution이 아직 제대로 정립되지 않은 시기라서 Pytorch 및 TensorFlow와 같은 심층 학습 라이브러리에서 효율적으로 사용하기 어려운 문제가 있습니다. 이를 해결하고자 PeleeNet에서는 전통적인 합성곱 신경망을 이용해서 속도를 향상시키는 방법을 제안합니다.
PeleeNet
PeleeNet은 기본적으로 DenseNet을 기반으로 구현되었습니다. 특히, DenseNet의 특징 맵 간의 연결성을 차용하였습니다. 이 중에서 5개의 변형을 주어 PeleeNet으로 구성하는 방법에 대해서 말씀드리겠습니다.
1). Two-Way Dense Layer
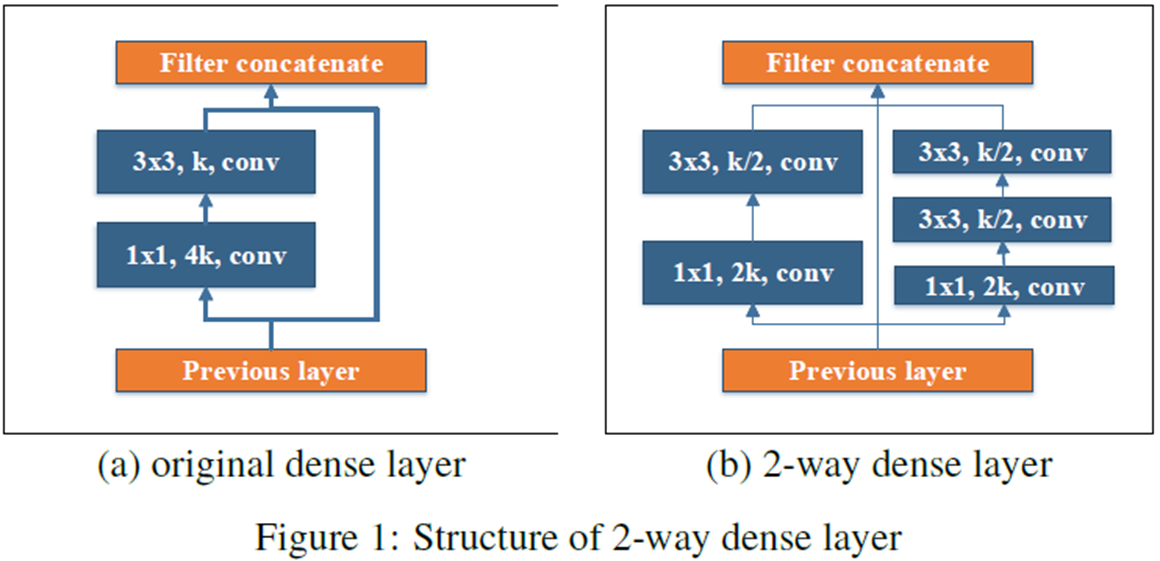
그림1은 기존의 Dense Layer (왼쪽)와 본 논문에서 제안하는 2-Way Dense Layer (오른쪽)의 블록 다이어그램을 보여주고 있습니다. 이 방법은 기존의 GoogLeNet에 영감을 받아서 서로 다른 receptive field를 가지는 multi-path를 두어 multi-scale 정보를 활용할 수 있게 합니다.
2). Stem Block
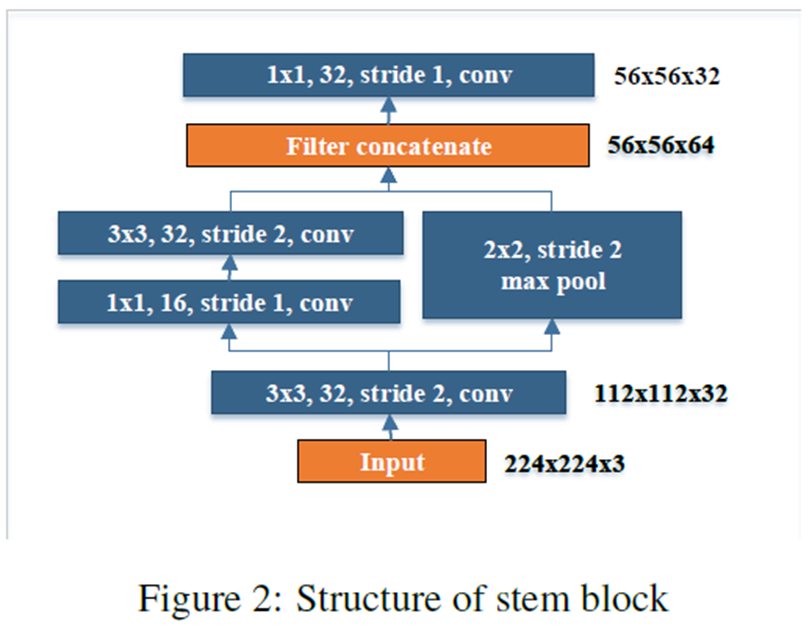
그림2는 본 논문에서 제안하는 Stem Block의 블록 다이어그램을 보여주고 있습니다. 이 방법은 InceptionNet-V4의 Stem Block을 활용하고 있습니다.
3). Dynamic Number of Channels in Bottleneck Layer
기본적으로 DenseNet은 growth rate가 4로 고정되어 있습니다. 하지만, PeleeNet에서는 블록에 따라 growth rate를 다르게 설정하여 28.5%의 계산 효율성을 증가시킵니다.
4). Transition Layer without Compression
기존의 DenseNet은 Compression Factor를 도입하여 한 군데에 모인 특징 맵들을 어느정도 압축해줍니다. 하지만, Pelee에서는 이 부분을 빼고 Transition Layer에서 입력 채널의 개수가 출력 채널의 개수와 동일하게 세팅하였습니다.
5). Composition Function
DenseNet에서는 PreAct ResNet의 구조를 차용하여 BN - ReLU - Conv의 순서로 연산을 수행합니다. PeleeNet에서는 inference 과정에서 BN과 Conv 연산을 동시에 적용하기 위해 여기에서는 PostAct 구조를 사용하여 Conv - BN - ReLU의 순서로 연산을 수행하였습니다. 이러한 변형으로 감소하는 성능을 보완하기 위해 $1 \times 1$ 크기의 합성곱을 추가로 적용하였습니다.
PeleeNet Architecture
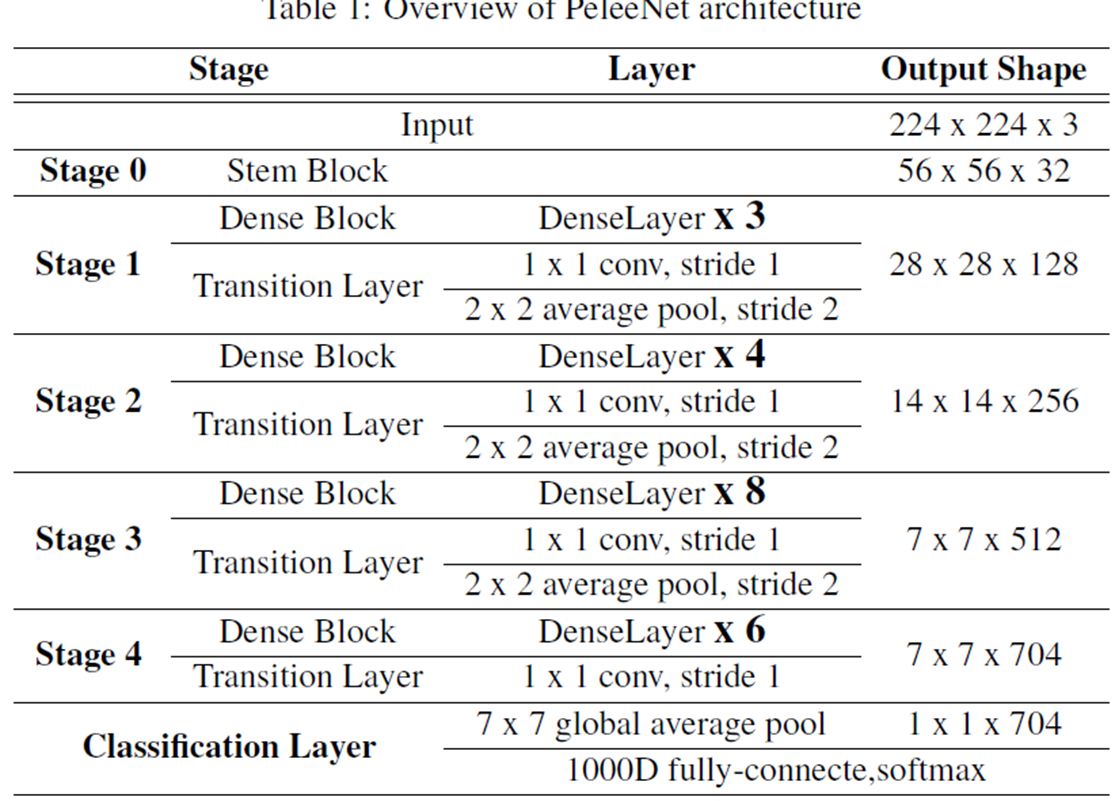
Experiment Results
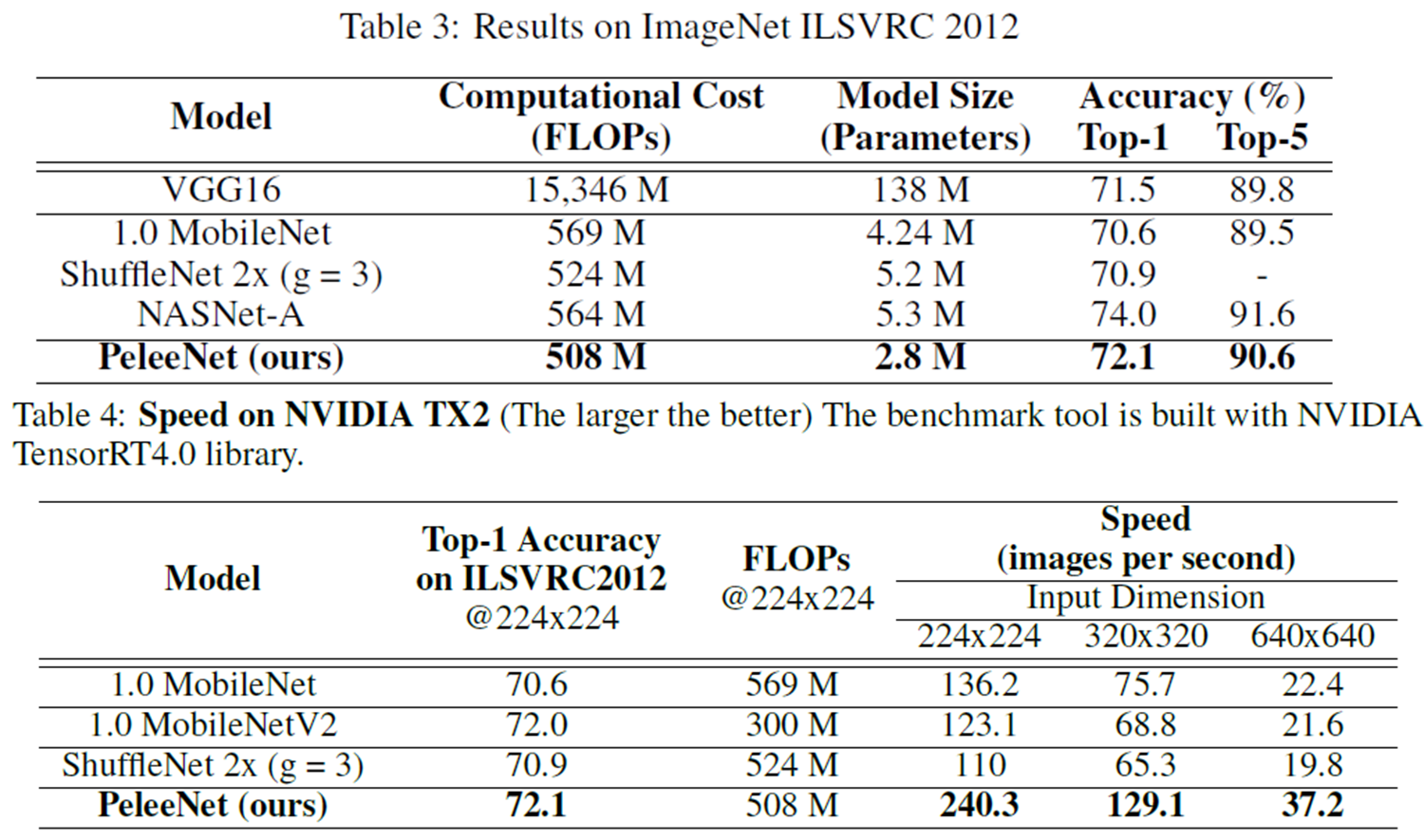
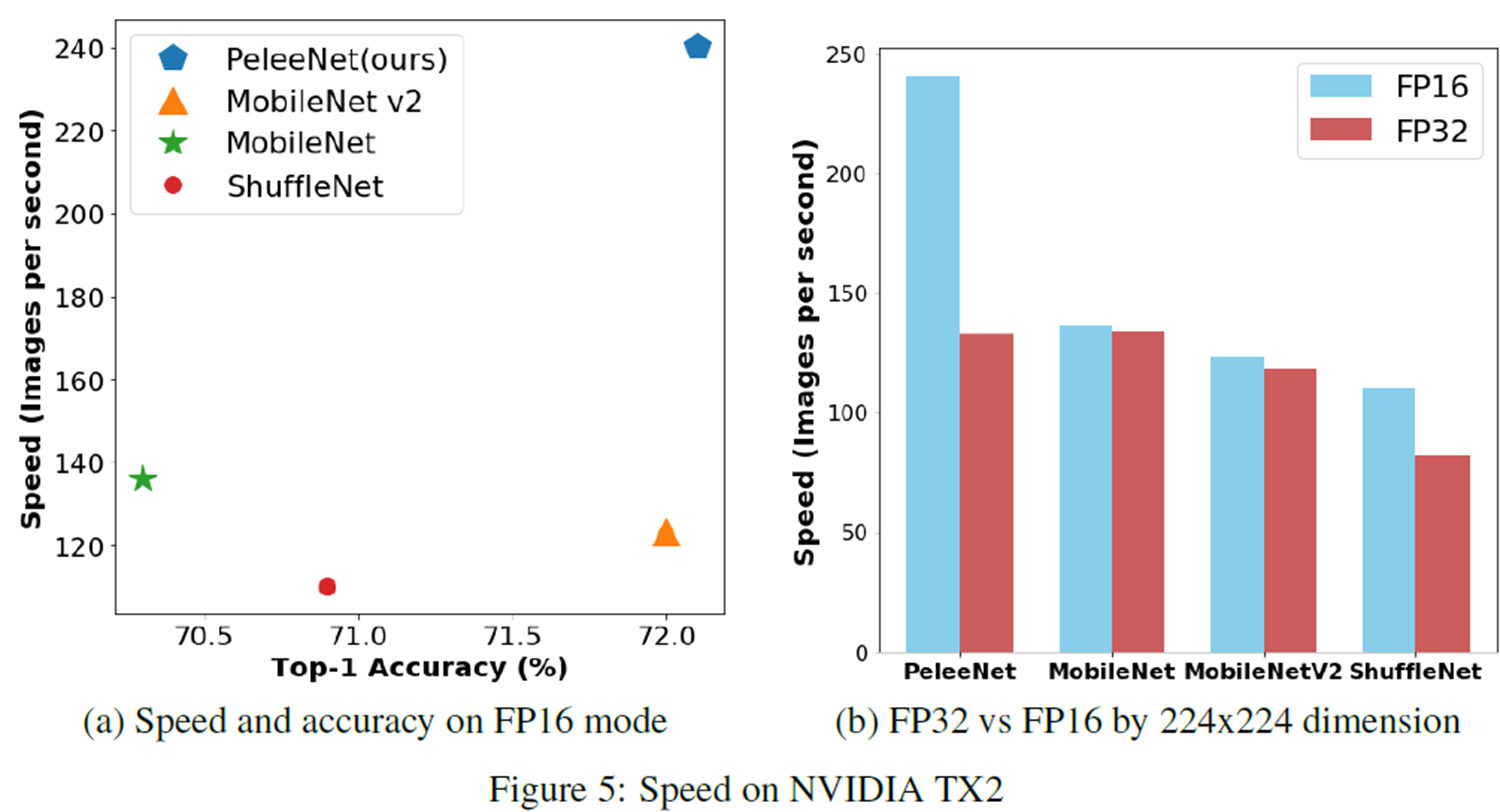
1). ImageNet Classification Results