
안녕하세요. 지난 포스팅에서는 기초통계학[21].베타 분포(https://everyday-image-processing.tistory.com/41)에 대해서 간단하게 알아보았습니다. 오늘은 베이즈 추론의 5번째 포스팅입니다. 지금까지 추론한 경우를 상기해보시면 이산 사전확률을 가지는 연속 사전확률을 가지는 항상 데이터 자체는 이산 데이터임을 떠올릴 수 있습니다. 이번에는 연속 사전확률과 연속 데이터를 가지는 경우에 베이즈 추론을 하는 방법에 대해서 알아보도록 하겠습니다.
1. 연속 가설과 연속 데이터
본격적으로 시작하기 전에 이산 데이터에서 연속 데이터로 바뀌었으므로 기호를 재정의하도록 하겠습니다. 물론 이전 기호와 동일한 경우도 있습니다.
- 가설 : $\theta$
- 데이터 : $x$
- 사전 확률 : $f(\theta)d\theta$
- 우도 : $f(x|\theta)dx$
- 사후 확률 : $f(\theta|x)d\theta$
다른 점이 보이시나요? 바로 우도 $f(x|\theta)dx$가 바뀌었습니다. 잠깐 우도의 정의에 대해서 생각해보고 넘어가겠습니다. 우도란 가설이 주어졌을 때 데이터가 나올 확률이라고 계속 언급하였습니다. 이때 데이터가 연속이라고 가정했기 때문에 데이터는 기본적으로 확률 밀도함수를 따를 수 밖에 없습니다. 하지만 누누히 언급했다싶이 확률 밀도함수 자체는 확률이 아니라고 하였습니다. 이를 확률로 표현해주기 위해서 구간의 미소(아주 작은) 길이(별로 좋지 않은 표현인 것 같습니다만...)인 $dx$를 곱하였습니다.
그리고 현재 우도에 $dx$를 곱하고 있는 형태입니다. 따라서 앞으로 연속 사전확률에 연속 데이터라고 주어진다면 편의상 이 기호는 생략하도록 하겠습니다. 생략하더라도 곱해져 있는 것을 잊으시면 안됩니다.
이 기호들을 사용해서 베이즈 추론 표를 작성하면 아래와 같습니다.
| 가설 | 사전 확률 | 우도 | 베이즈 분자식 | 사후 확률 |
| $\theta$ | $f(\theta)d\theta$ | $f(x|\theta)$ | $f(x|\theta)f(\theta)d\theta$ | $f(\theta|x)=\frac{f(x|\theta)f(\theta)d\theta}{f(x)}$ |
| total | 1 | $f(x)=\int f(x|\theta)f(\theta) \; d\theta$ | 1 |
이제 예시를 들어보겠습니다. 연속 사전확률을 가지면서 데이터도 연속인 경우는 간단한 예시로 연속 사전확률이 연속 사전확률과 데이터가 모두 정규분포를 따르는 경우가 되겠습니다. 이제 문제를 간단하게 하기위해서 정규분포의 분산은 알고 있다고 가정하겠습니다.
예제1. 데이터 $x = 5$를 분산이 1이고 평균이 $\theta$인 정규분포에서 왔다고 가정하겠습니다. 즉, $x \sim {\sf N}(\theta, 1)$ 입니다. 그리고 $\theta$는 평균이 2이고 분산이 1인 정규분포를 따른다고 가정하겠습니다. 즉 $\theta \sim {\sf N}(1, 2)$ 입니다.
이 상태에서 베이즈 추론을 해보도록 하겠습니다.
먼저 사전확률을 구해야겠죠. 가정에 의해서 사전확률이 평균이 2이고 분산이 1인 정규분포를 따른다고 하였으므로 $f(\theta)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(\theta-2)^{2}}{2}}$입니다.(정규분포 공식을 떠올려보십쇼.)
그 다음에는 우도를 얻습니다. 즉, $f(x=5|\theta)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(5-\theta)^{2}}{2}}$입니다.
그리고 사전확률과 우도를 곱해서 베이즈 분자식을 얻어야합니다.
$$\Rightarrow \frac{1}{\sqrt{2\pi}}e^{-\frac{(\theta-2)^{2}}{2}} \cdot \frac{1}{\sqrt{2\pi}}e^{-\frac{(5-\theta)^{2}}{2}}$$
$$\Rightarrow \frac{1}{2\pi}e^{-(\theta^{2}-7\theta+\frac{29}{2})}$$
$$\Rightarrow \frac{1}{2\pi}e^{-((\theta - \frac{7}{2})^{2} + \frac{9}{4})}$$
$$\Rightarrow \frac{e^{\frac{9}{4}}}{2\pi}e^{-(\theta - \frac{7}{2})^{2}}$$
이때 계수부분은 그냥 $c_{1}$이라고 하겠습니다.
$$\frac{e^{\frac{9}{4}}}{2\pi}e^{-(\theta - \frac{7}{2})^{2}}$$
마지막으로 베이즈 추론표를 완성합니다.
| 가설 | 사전확률 | 우도 | 베이즈 분자식 | 사후확률 |
| $\theta$ | $f(\theta)d\theta$ | $f(x=5|\theta)$ | $f(x=5|\theta)f(\theta)d\theta$ | $\frac{f(x=5|\theta)f(\theta)d\theta}{f(x=5)}$ |
| $\theta$ | $f(\theta)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(\theta-2)^{2}}{2}}$ | $f(x=5|\theta)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(5-\theta)^{2}}{2}}$ | $c_{1}e^{-(\theta - \frac{7}{2})^{2}}$ | $c_{2}e^{-(\theta - \frac{7}{2})^{2}}$ |
| total | 1 | $f(x=5)=\int f(x=5|\theta)f(\theta)\; d\theta$ | 1 |
이때, $f(x=5)=\int f(x=5|\theta)f(\theta)\; d\theta$는 단순 상수이기 때문에 이를 $c_{1}$이랑 나누어서 $c_{2}$가 나오게 됩니다.
이 결과를 보면 사후확률는 평균이 $\frac{7}{2}$이고 분산이 $\frac{1}{2}$인 정규분포를 따르는 것을 알 수 있습니다. 이 변화를 그림으로 그려보면 더 명확할 겁니다.
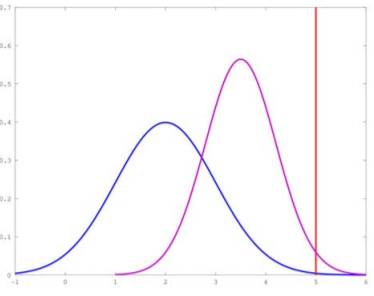
파란색이 사전확률의 분포, 보라색이 사후확률의 분포, 빨간색이 데이터입니다. 사전확률의 분포에 비해서 사후확률의 분포가 데이터에 더 가까워진것을 볼 수 있습니다. 만약 여기에서 데이터가 다시 5가 나온다면 5에 점점 더 가까워질 것입니다.
'수학 > 기초통계학' 카테고리의 다른 글
| 기초통계학[24].공액 사전 확률분포 2 (0) | 2020.04.27 |
|---|---|
| 기초통계학[23].공액 사전 확률분포 1 (0) | 2020.04.22 |
| 기초통계학[21]. 베타 분포(Beta Distribution) (0) | 2020.04.15 |
| 기초통계학[20].베이즈 추론 4 - 연속 사전확률을 가지는 경우에 대하여 (1) | 2020.04.12 |
| 기초통계학[19].베이즈 추론 3 - 오즈(Odds) (0) | 2020.04.09 |