
안녕하세요. 지난 포스팅의 넘파이 알고 쓰자 - stack, hstack, vstack, dstack, column_stack에서 concatenate 함수와 유사한 기능을 하는 넘파이 객체들을 합치는 함수들에 대해서 알아보았습니다. 오늘은 넘파이 객체를 쪼개는 함수들에 대해서 알아보도록 하겠습니다.
1. np.split(ary, indices_or_sections, axis=0)
"ary" : 넘파이 객체로 쪼갤 배열입니다.
"indices_or_sections" : 만약 이 인수가 정수형 N이라면 쪼개지는 배열이 N개의 동일한 값을 가집니다. 만약, 나누는 것이 불가능하다면 오류가 발생합니다. 만약, 이 인수가 정렬된 1차원 배열이라면 배열의 요소값을 기준으로 값을 나눕니다.
"axis" : 나눌 방향을 의미합니다.
예를 들어서 9개의 1차원 배열이 있다고 가정하겠습니다. 이때, indices_or_sections=3으로 지정하면 쪼개지는 서브배열들의 원소의 개수는 각각 3개씩 나누어집니다.
x = np.arange(9.0)
np.split(x, 3)
# [array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]만약, 4개씩 나눈다면 조건에 의해서 아래와 같은 ValueError 오류가 날 것입니다.
np.split(x, 4)
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# ~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
# 864 try:
# --> 865 len(indices_or_sections)
# 866 except TypeError:
# TypeError: object of type 'int' has no len()
# During handling of the above exception, another exception occurred:
# ValueError Traceback (most recent call last)
# <ipython-input-5-ff48ec4c4c29> in <module>
# ----> 1 np.split(x, 4)
# 2 # [array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]
# <__array_function__ internals> in split(*args, **kwargs)
# ~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
# 869 if N % sections:
# 870 raise ValueError(
# --> 871 'array split does not result in an equal division')
# 872 return array_split(ary, indices_or_sections, axis)
# 873
# ValueError: array split does not result in an equal division하지만, 항상 동일한 개수로 나누고 싶지 않을 때가 있습니다!! 그럴때는 indices_or_sections를 정렬된 배열로 지정하면 됩니다. 예를 들어서 방금 예시로 든 9개의 배열이 있을 때 indices_or_sections=(2, 3) 또는 indices_or_sections=[2, 3]으로 지정하면 서브배열이 (0, 1), (2), (3, 4, 5, 6, 7, 8)로 쪼개질 것입니다. 이와 같이 유동적으로 쪼개는 방법도 존재합니다. 이렇게 배열로 지정하면 특정개수로 정확하게 나누어지지 않아 발생하는 ValueError가 발생하지 않을 것입니다.
np.split(x, (2, 3))
# [array([0., 1.]), array([2.]), array([3., 4., 5., 6., 7., 8.])]간단히 말해서 indices_or_sections에 배열로 넣을 때는 어떤 인덱스를 기준으로 쪼갤것인지를 생각하시면 됩니다. 이번에는 다른 방식으로 쪼개보도록 하겠습니다.
x = np.arange(8.0)
np.split(x, [3, 5, 6, 10])
# [array([0., 1., 2.]),
# array([3., 4.]),
# array([5.]),
# array([6., 7.]),
# array([], dtype=float64)]이번에는 인덱스를 3, 5, 6, 10을 기준으로 0~7까지의 8개의 원소를 가진 배열을 나누어보도록 하겠습니다. 그러면 얻어지는 서브배열이 각각 (0, 2), (3, 4), (5), (6, 7) 까지인 것을 볼 수 있습니다. 이때, 입력받은 배열의 최대 인덱스인 7부터 10까지는 값이 존재하지 않기 때문에 이 부부은 아무런 값이 존재하지 않는 넘파이 배열이 반환되는 것을 볼 수 있습니다. 아래의 그림을 보시면 쉽게 이해가 되실겁니다.
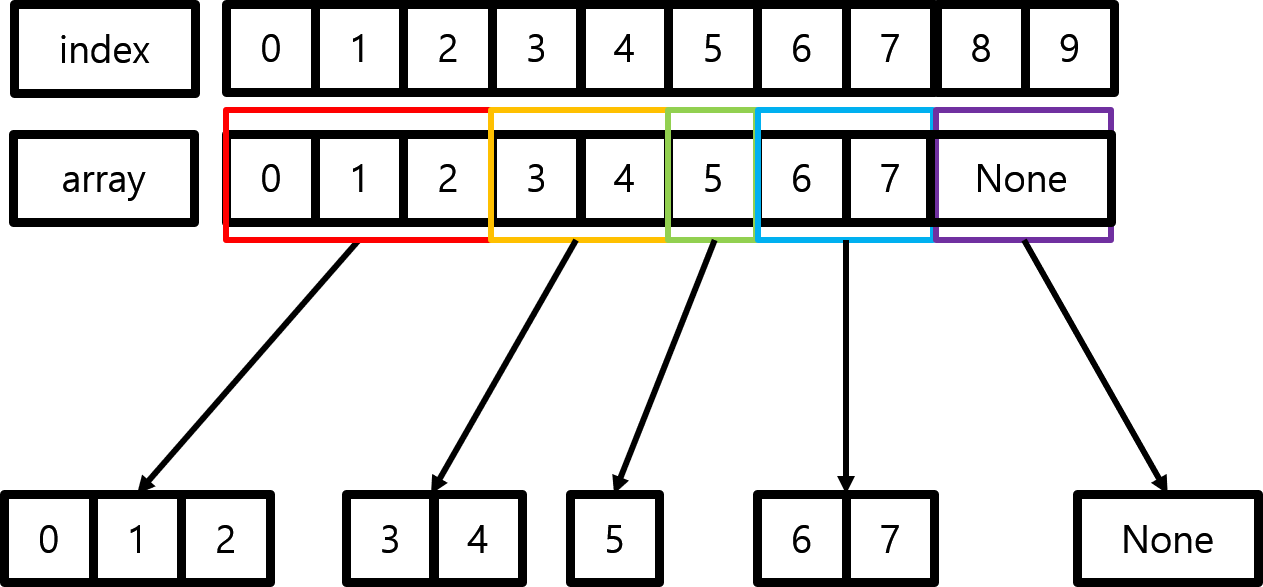
이번에는 행렬을 쪼개보도록 하겠습니다. 방금까지는 axis=0으로 디폴트 값으로 정하였지만 이번에는 axis를 바꾸어보면서 값을 비교해보도록 하겠습니다. 3 $\times$ 3 행렬을 생성하고 axis=0 방향으로 3개씩 쪼개면 당연하지만 1 $\times$ 3의 shape을 가지는 배열이 3개가 생기는 것을 볼 수 있습니다. 또한 axis=1 방향으로 3개씩 쪼갤 수도 있습니다. 그러면 3 $\times$ 1의 shape을 가지는 배열이 3개가 생성됩니다.
x = np.arange(9.0).reshape(3, 3)
np.split(x, 3)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]
np.split(x, 3, axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]또한 행렬도 배열과 동일하게 indices_or_sections를 해당 axis 방향에 따른 shape 값의 약수값을 안넣으면 ValueError가 발생하는 것을 볼 수 있습니다.
np.split(x, 4, axis=1)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
864 try:
--> 865 len(indices_or_sections)
866 except TypeError:
TypeError: object of type 'int' has no len()
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
<ipython-input-17-1e827b4094ee> in <module>
----> 1 np.split(x, 4, axis=1)
<__array_function__ internals> in split(*args, **kwargs)
~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
869 if N % sections:
870 raise ValueError(
--> 871 'array split does not result in an equal division')
872 return array_split(ary, indices_or_sections, axis)
873
ValueError: array split does not result in an equal division이번에는 indices_or_sections에 정렬된 배열을 넣어보도록 하겠습니다.
np.split(x, (1, 4))
# [array([[0., 1., 2.]]),
# array([[3., 4., 5.],
# [6., 7., 8.]]),
# array([], shape=(0, 3), dtype=float64)]
np.split(x, (1, 4), axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1., 2.],
# [4., 5.],
# [7., 8.]]),
# array([], shape=(3, 0), dtype=float64)]
axis=0만 설명해보면 (1, 4)를 나누는 인덱스의 기준으로 받았기 때문에 나누어 지는 값은 각각 (0번째 행), (1번째 행, 2번째 행, 3번째 행)으로 나누어져야합니다. 하지만 axis=0 방향으로 보면 최대 인덱스가 2이기 때문에 (0번째 행), (1번째 행, 2번째 행)까지 나누고 (3번째 행)은 아무것도 없는 값이기 때문에 아무것도 없는 None 넘파이 배열을 반환하게 됩니다.
그런데 한 가지 궁금한 점이 있습니다. indices_or_sections에는 왜 정렬된 배열을 넣어야할까요? 왜냐하면 indices_or_sections이라는 인수는 배열을 쪼개는 기준 인덱스의 배열이라고 설명드렸습니다. 그런데 이 배열이 정렬되어 있지 않다면 어떻게 쪼개질까요? 예시를 보도록 하겠습니다.
x = np.arange(8.0)
np.split(x, [5, 3, 6, 10])
# [array([0., 1., 2., 3., 4.]),
# array([], dtype=float64),
# array([3., 4., 5.]),
# array([6., 7.]),
# array([], dtype=float64)]코드를 보시면 [5, 3, 6, 10]이 정렬이 되지 않은 것을 볼 수 있습니다. 결과를 보면 첫번째 서브배열은 (0~4번 인덱스)를 반환하였습니다. 다음 서브배열은 (5~2번 인덱스)을 반환해야합니다. 그런데 역순이네요? 이러면 슬라이싱에 실패하여 값이 아무것도 없다고 판단하기 때문에 정렬된 인덱스 배열을 넣어줘야 저희가 원하는 서브배열들을 얻을 수 있는 것을 볼 수 있습니다.
2. np.hsplit(ary, indices_or_sections)
이 함수는 split 함수를 axis=1 방향으로 쪼개는 것과 완전히 동일한 함수입니다. 예시만 보고 넘어가도록 하겠습니다.
x = np.arange(9.0).reshape(3, 3)
np.hsplit(x, 3)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]
np.split(x, 3, axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]
3. np.vsplit(ary, indices_or_sections)
이 함수는 split 함수를 axis=0 방향으로 쪼개는 것과 완전히 동일한 함수입니다. 이 역시 예시만 보고 넘어가도록 하겠습니다.
x = np.arange(9.0).reshape(3, 3)
np.vsplit(x, 3)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]
np.split(x, 3, axis=0)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]4. np.dsplit(ary, indices_or_sections)
이 함수는 다른 함수들과는 다르게 3차원 이상의 배열이 반드시 들어가야합니다. 즉, axis=2 방향으로 쪼개는 함수라는 것이죠!
x = np.arange(16.0).reshape(2, 2, 4)
np.dsplit(x, 2)
# [array([[[ 0., 1.],
# [ 4., 5.]],
# [[ 8., 9.],
# [12., 13.]]]),
# array([[[ 2., 3.],
# [ 6., 7.]],
# [[10., 11.],
# [14., 15.]]])]
np.split(x, 2, axis=2)
# [array([[[ 0., 1.],
# [ 4., 5.]],
# [[ 8., 9.],
# [12., 13.]]]),
# array([[[ 2., 3.],
# [ 6., 7.]],
# [[10., 11.],
# [14., 15.]]])]'Programming > Python' 카테고리의 다른 글
| 넘파이 알고 쓰자 - 넘파이의 원소 제거 및 추가(delete, add) (0) | 2020.09.01 |
|---|---|
| 넘파이 알고 쓰자 - 배열 복붙하기(Tiling) (0) | 2020.08.30 |
| 넘파이 알고 쓰자 - stack, hstack, vstack, dstack, column_stack (7) | 2020.08.26 |
| 넘파이 알고 쓰자 - concatenate (1) | 2020.08.24 |
| 넘파이 알고 쓰자 - Random Module (0) | 2020.08.22 |
안녕하세요. 지난 포스팅의 넘파이 알고 쓰자 - stack, hstack, vstack, dstack, column_stack에서 concatenate 함수와 유사한 기능을 하는 넘파이 객체들을 합치는 함수들에 대해서 알아보았습니다. 오늘은 넘파이 객체를 쪼개는 함수들에 대해서 알아보도록 하겠습니다.
1. np.split(ary, indices_or_sections, axis=0)
"ary" : 넘파이 객체로 쪼갤 배열입니다.
"indices_or_sections" : 만약 이 인수가 정수형 N이라면 쪼개지는 배열이 N개의 동일한 값을 가집니다. 만약, 나누는 것이 불가능하다면 오류가 발생합니다. 만약, 이 인수가 정렬된 1차원 배열이라면 배열의 요소값을 기준으로 값을 나눕니다.
"axis" : 나눌 방향을 의미합니다.
예를 들어서 9개의 1차원 배열이 있다고 가정하겠습니다. 이때, indices_or_sections=3으로 지정하면 쪼개지는 서브배열들의 원소의 개수는 각각 3개씩 나누어집니다.
x = np.arange(9.0)
np.split(x, 3)
# [array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]만약, 4개씩 나눈다면 조건에 의해서 아래와 같은 ValueError 오류가 날 것입니다.
np.split(x, 4)
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# ~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
# 864 try:
# --> 865 len(indices_or_sections)
# 866 except TypeError:
# TypeError: object of type 'int' has no len()
# During handling of the above exception, another exception occurred:
# ValueError Traceback (most recent call last)
# <ipython-input-5-ff48ec4c4c29> in <module>
# ----> 1 np.split(x, 4)
# 2 # [array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]
# <__array_function__ internals> in split(*args, **kwargs)
# ~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
# 869 if N % sections:
# 870 raise ValueError(
# --> 871 'array split does not result in an equal division')
# 872 return array_split(ary, indices_or_sections, axis)
# 873
# ValueError: array split does not result in an equal division하지만, 항상 동일한 개수로 나누고 싶지 않을 때가 있습니다!! 그럴때는 indices_or_sections를 정렬된 배열로 지정하면 됩니다. 예를 들어서 방금 예시로 든 9개의 배열이 있을 때 indices_or_sections=(2, 3) 또는 indices_or_sections=[2, 3]으로 지정하면 서브배열이 (0, 1), (2), (3, 4, 5, 6, 7, 8)로 쪼개질 것입니다. 이와 같이 유동적으로 쪼개는 방법도 존재합니다. 이렇게 배열로 지정하면 특정개수로 정확하게 나누어지지 않아 발생하는 ValueError가 발생하지 않을 것입니다.
np.split(x, (2, 3))
# [array([0., 1.]), array([2.]), array([3., 4., 5., 6., 7., 8.])]간단히 말해서 indices_or_sections에 배열로 넣을 때는 어떤 인덱스를 기준으로 쪼갤것인지를 생각하시면 됩니다. 이번에는 다른 방식으로 쪼개보도록 하겠습니다.
x = np.arange(8.0)
np.split(x, [3, 5, 6, 10])
# [array([0., 1., 2.]),
# array([3., 4.]),
# array([5.]),
# array([6., 7.]),
# array([], dtype=float64)]이번에는 인덱스를 3, 5, 6, 10을 기준으로 0~7까지의 8개의 원소를 가진 배열을 나누어보도록 하겠습니다. 그러면 얻어지는 서브배열이 각각 (0, 2), (3, 4), (5), (6, 7) 까지인 것을 볼 수 있습니다. 이때, 입력받은 배열의 최대 인덱스인 7부터 10까지는 값이 존재하지 않기 때문에 이 부부은 아무런 값이 존재하지 않는 넘파이 배열이 반환되는 것을 볼 수 있습니다. 아래의 그림을 보시면 쉽게 이해가 되실겁니다.
이번에는 행렬을 쪼개보도록 하겠습니다. 방금까지는 axis=0으로 디폴트 값으로 정하였지만 이번에는 axis를 바꾸어보면서 값을 비교해보도록 하겠습니다. 3 $\times$ 3 행렬을 생성하고 axis=0 방향으로 3개씩 쪼개면 당연하지만 1 $\times$ 3의 shape을 가지는 배열이 3개가 생기는 것을 볼 수 있습니다. 또한 axis=1 방향으로 3개씩 쪼갤 수도 있습니다. 그러면 3 $\times$ 1의 shape을 가지는 배열이 3개가 생성됩니다.
x = np.arange(9.0).reshape(3, 3)
np.split(x, 3)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]
np.split(x, 3, axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]또한 행렬도 배열과 동일하게 indices_or_sections를 해당 axis 방향에 따른 shape 값의 약수값을 안넣으면 ValueError가 발생하는 것을 볼 수 있습니다.
np.split(x, 4, axis=1)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
864 try:
--> 865 len(indices_or_sections)
866 except TypeError:
TypeError: object of type 'int' has no len()
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
<ipython-input-17-1e827b4094ee> in <module>
----> 1 np.split(x, 4, axis=1)
<__array_function__ internals> in split(*args, **kwargs)
~/anaconda3/lib/python3.7/site-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
869 if N % sections:
870 raise ValueError(
--> 871 'array split does not result in an equal division')
872 return array_split(ary, indices_or_sections, axis)
873
ValueError: array split does not result in an equal division이번에는 indices_or_sections에 정렬된 배열을 넣어보도록 하겠습니다.
np.split(x, (1, 4))
# [array([[0., 1., 2.]]),
# array([[3., 4., 5.],
# [6., 7., 8.]]),
# array([], shape=(0, 3), dtype=float64)]
np.split(x, (1, 4), axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1., 2.],
# [4., 5.],
# [7., 8.]]),
# array([], shape=(3, 0), dtype=float64)]axis=0만 설명해보면 (1, 4)를 나누는 인덱스의 기준으로 받았기 때문에 나누어 지는 값은 각각 (0번째 행), (1번째 행, 2번째 행, 3번째 행)으로 나누어져야합니다. 하지만 axis=0 방향으로 보면 최대 인덱스가 2이기 때문에 (0번째 행), (1번째 행, 2번째 행)까지 나누고 (3번째 행)은 아무것도 없는 값이기 때문에 아무것도 없는 None 넘파이 배열을 반환하게 됩니다.
그런데 한 가지 궁금한 점이 있습니다. indices_or_sections에는 왜 정렬된 배열을 넣어야할까요? 왜냐하면 indices_or_sections이라는 인수는 배열을 쪼개는 기준 인덱스의 배열이라고 설명드렸습니다. 그런데 이 배열이 정렬되어 있지 않다면 어떻게 쪼개질까요? 예시를 보도록 하겠습니다.
x = np.arange(8.0)
np.split(x, [5, 3, 6, 10])
# [array([0., 1., 2., 3., 4.]),
# array([], dtype=float64),
# array([3., 4., 5.]),
# array([6., 7.]),
# array([], dtype=float64)]코드를 보시면 [5, 3, 6, 10]이 정렬이 되지 않은 것을 볼 수 있습니다. 결과를 보면 첫번째 서브배열은 (0~4번 인덱스)를 반환하였습니다. 다음 서브배열은 (5~2번 인덱스)을 반환해야합니다. 그런데 역순이네요? 이러면 슬라이싱에 실패하여 값이 아무것도 없다고 판단하기 때문에 정렬된 인덱스 배열을 넣어줘야 저희가 원하는 서브배열들을 얻을 수 있는 것을 볼 수 있습니다.
2. np.hsplit(ary, indices_or_sections)
이 함수는 split 함수를 axis=1 방향으로 쪼개는 것과 완전히 동일한 함수입니다. 예시만 보고 넘어가도록 하겠습니다.
x = np.arange(9.0).reshape(3, 3)
np.hsplit(x, 3)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]
np.split(x, 3, axis=1)
# [array([[0.],
# [3.],
# [6.]]),
# array([[1.],
# [4.],
# [7.]]),
# array([[2.],
# [5.],
# [8.]])]
3. np.vsplit(ary, indices_or_sections)
이 함수는 split 함수를 axis=0 방향으로 쪼개는 것과 완전히 동일한 함수입니다. 이 역시 예시만 보고 넘어가도록 하겠습니다.
x = np.arange(9.0).reshape(3, 3)
np.vsplit(x, 3)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]
np.split(x, 3, axis=0)
# [array([[0., 1., 2.]]), array([[3., 4., 5.]]), array([[6., 7., 8.]])]4. np.dsplit(ary, indices_or_sections)
이 함수는 다른 함수들과는 다르게 3차원 이상의 배열이 반드시 들어가야합니다. 즉, axis=2 방향으로 쪼개는 함수라는 것이죠!
x = np.arange(16.0).reshape(2, 2, 4)
np.dsplit(x, 2)
# [array([[[ 0., 1.],
# [ 4., 5.]],
# [[ 8., 9.],
# [12., 13.]]]),
# array([[[ 2., 3.],
# [ 6., 7.]],
# [[10., 11.],
# [14., 15.]]])]
np.split(x, 2, axis=2)
# [array([[[ 0., 1.],
# [ 4., 5.]],
# [[ 8., 9.],
# [12., 13.]]]),
# array([[[ 2., 3.],
# [ 6., 7.]],
# [[10., 11.],
# [14., 15.]]])]'Programming > Python' 카테고리의 다른 글
| 넘파이 알고 쓰자 - 넘파이의 원소 제거 및 추가(delete, add) (0) | 2020.09.01 |
|---|---|
| 넘파이 알고 쓰자 - 배열 복붙하기(Tiling) (0) | 2020.08.30 |
| 넘파이 알고 쓰자 - stack, hstack, vstack, dstack, column_stack (7) | 2020.08.26 |
| 넘파이 알고 쓰자 - concatenate (1) | 2020.08.24 |
| 넘파이 알고 쓰자 - Random Module (0) | 2020.08.22 |