
안녕하세요. 오늘은 굉장히 유명한 논문인 Deep Convolution GAN이라는 논문의 원리를 간단하게 설명하고 코드 구현을 해보도록 하겠습니다. 블로그의 원문은 아래의 링크를 참조해주세요.
https://medium.com/swlh/dcgan-under-100-lines-of-code-fc7fe22c391
DCGAN Under 100 Lines of Code
Although Deep Convolutional GAN has been visited time and again, the ones reading the paper Unsupervised Representation Learning with Deep…
medium.com
먼저, GAN(Generative Adversarial Networks)는 지난 2014년에 이안 굿펠로우라는 분이 제안한 새로운 형태에 학습방법입니다. 현재, 수많은 논문들은 이 학습 방식을 응용하고 있습니다. 실제로도 많이 사용되고 있죠. 기본적으로 GAN을 이용해서 할 수 있는 어플리케이션이 너무 많아보니 일일히 열거하기는 어렵지만 대표적으로 쓰이는 곳은 이미지 생성(image generate), 이미지 대 이미지 변환(image translation), 이미지 고품질화(Super resolution) 등이 있습니다.
1. 기본 개념
GAN의 기본 개념은 위조 지폐범과 경찰의 관계라고 볼 수 있습니다. GAN에는 2가지의 네트워크가 공존합니다. 각각 생성 모델(Generative model;Generator)과 판단 모델(Discriminate model;Discriminator)이라고 불립니다. 생성 모델은 위조 지폐범이고 판단 모델은 경찰입니다. 즉, 생성 모델은 판단 모델이 알아채지 못할 정도로 원래 지폐와 굉장히 유사한 지폐를 만드는 것이 목표입니다. 하지만, 굉장히 유사하더라도 결국에 위조 지폐는 위조 지폐입니다. 판단 모델은 생성 모델이 만든 데이터와 기존의 데이터를 확인하여 이 데이터가 진짜(Real)인지 가짜(Fake)인지 판단합니다.
눈치가 빠르신 분들은 아시겠지만 두 네트워크 사이의 관계는 사이가 그렇게 좋지 못합니다. 서로 한 명은 만들고 한 명은 판단하기 때문에 서로 적대적인 관계(adversarial)를 가지고 있기 때문이죠. 정리하면 아래와 같습니다.
- 생성 모델은 판단 모델이 Real이라고 판단할 정도의 기존의 데이터 셋과 굉장히 유사한 가짜 데이터를 생성한다.
- 판단 모델은 생성 모델이 만든 데이터와 기존 데이터를 Fake와 Real로의 이진 분류(Binary classification)을 잘 해내야한다.
생성 모델을 $G$, 판단 모델을 $D$라고 하겠습니다. 그러면 새롭게 생성된 데이터는 어떤 입력 $z$를 받아서 새로 생성하기 때문에 $G(z)$입니다. 그리고 기존의 데이터 셋으로부터 온 실제 데이터는 $x$라고 하겠습니다. 그러면 위 내용에 의해서 판단 모델이 실제 데이터 $x$를 받으면 1(Real)이라고 판단할 확률을 높혀야합니다. 따라서 $E_{x \sim {p_{data}(x)}}[\log{D(x)}]$가 작아지게 만들어 주어야합니다. 이는 어려운 것이 아니라 실제 데이터는 판단 모델이 실제 데이터라고 판단할 확률을 높히는 것입니다. 그리고 생성 모델이 만든 새로운 데이터 $G(z)$는 0(Fake)이라고 판단할 확률을 높혀야하기 때문에 $E_{z \sim {p_{z}(z)}}[\log{\left(1-D(G(z))\right)}]$가 작아지게 만들어주어야합니다. 이를 식으로 정리하면 아래와 같습니다.
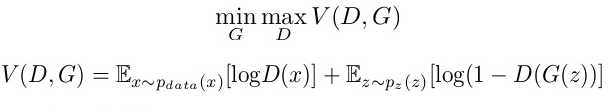
2. DCGAN
하지만 GAN은 기본적으로 학습이 불안정하다는 단점이 있습니다. 학습을 오랫동안 하더라도 의미없는 데이터를 생성하는 생성 모델을 얻을 수도 있기 때문이죠. 이때, DCGAN은 이러한 GAN의 단점을 해결하여 그나마 학습을 안정적으로 할 수 있도록 도와주었습니다. 기본적으로 사용된 기법은 배치 정규화, 적절한 활성화 함수 등이 있습니다. 논문에서 말하는 핵심 사항을 정리하면 아래와 같습니다.
- 이미지는 $\tanh$ 활성화 함수의 범위(-1~1)로 스케일링 된다.
- 모든 가중치는 평균 0, 분산 0.02의 정규 분포로 초기화 된다.
- 사용된 활성화 함수가 LeakyReLU라면 기울기는 0.2로 설정한다.
- Adam Optimizer는 두 네트워크의 최적화에 이용된다.
- 학습률은 2e-4로 시작한다.
- Adam Optimizer의 Moment $\beta_{1}$은 0.5로 고정한다.
아래는 전체 네트워크 구조입니다.

3. 구현(Implementation)
이제 실제로 구현하는 방법에 대해서 알아보겠습니다. 원본 코드는 아래의 깃허브를 참고하시면 됩니다.파이토치를 기본 프레임워크로 잡으니 참고하시길 바랍니다. github.com/himanshu-dutta/dcgan-pytorch
himanshu-dutta/dcgan-pytorch
Code for the tutorial of DCGAN using PyTorch. The article can be found at https://medium.com/swlh/dcgan-under-100-lines-of-code-fc7fe22c391 - himanshu-dutta/dcgan-pytorch
github.com
먼저, 필요한 라이브러리를 import 합니다.
# Import Packages
import torch
import torchvision as tv
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as opt
import numpy as np
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
%matplotlib inline그 다음에 GPU 설정을 위해 아래의 코드를 입력합니다.
if torch.cuda.is_available():
device = torch.device('cuda:0')
print('running on gpu...')
else:
device = torch.device('cpu')
print('running on gpu...')만약, 여러분들의 컴퓨터에 GPU가 있다면 해당 GPU를 이용해서 학습을 할 것이고 없다면 CPU를 이용해서 학습을 진행할 것입니다. 저는 GPU가 존재하기 때문에 사용하도록 하겠습니다. 그 다음으로 위에서 언급한 몇 가지 하이퍼파라미터들 외에도 이미지 사이즈나 epochs와 같은 하이퍼파라미터들도 정의해줍니다.
# set hyperparameters
BATCH_SIZE = 128
LR = 0.002
ZDIM = 100
IMG_SIZE = (28, 28)
EPOCHS = 20
BETA1 = 0.5이제 MNIST 데이터를 로드합니다. 이는 파이토치에서 기본적으로 제공해주는 데이터입니다. MNIST 뿐만 아니라 더 많은 데이터를 제공해주고 있기 때문에 아래의 링크를 통해 필요한 데이터 셋을 확인해보시길 바랍니다. pytorch.org/docs/stable/torchvision/datasets.html
torchvision.datasets — PyTorch 1.6.0 documentation
torchvision.datasets All datasets are subclasses of torch.utils.data.Dataset i.e, they have __getitem__ and __len__ methods implemented. Hence, they can all be passed to a torch.utils.data.DataLoader which can load multiple samples parallelly using torch.m
pytorch.org
# Load data(MNIST)
transforms = tv.transforms.Compose([
tv.transforms.ToTensor(),
RangeNormalize(-1, 1)])
traindata = tv.datasets.MNIST('data', train=True, transform=transforms, download=True)
trainloader = torch.utils.data.DataLoader(traindata, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)이제 로드한 데이터 배치 사이즈만큼 그려보겠습니다.

이것은 Real 데이터로 1이라고 판단할 데이터 셋들입니다. 생성 모델은 이 데이터셋들과 굉장히 유사한 데이터를 만들기 위해서 노력할 것입니다. 그리고 생성 모델과 판단 모델을 정의합니다.
# define Generator
class Gen(nn.Module) :
def __init__(self, ZDIM) :
super(Gen, self).__init__()
self.lin1 = nn.Linear(ZDIM, 256 * 7 * 7)
self.convT1 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1)
self.convT2 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=1, padding=1)
self.convT3 = nn.ConvTranspose2d(64, 1, kernel_size=3, stride=2, padding=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(128)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(1)
def forward(self, x) :
x = self.lin1(x)
x = F.leaky_relu(self.bn1(self.convT1(x.view(-1, 256, 7, 7))), negative_slope=0.01)
x = F.leaky_relu(self.bn2(self.convT2(x)), negative_slope=0.01)
x = F.tanh(self.bn3(self.convT3(x)))
return x# define Discriminator
class Dis(nn.Module) :
def __init__(self, IMG_SIZE) :
super(Dis, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=0)
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.flat = nn.Flatten()
self.lin = nn.Linear(128 * 3 * 3, 1)
def forward(self, x) :
x = x.view(-1,1,28,28)
x = F.leaky_relu(self.bn1(self.conv1(x)), negative_slope = 0.01)
x = F.leaky_relu(self.bn2(self.conv2(x)), negative_slope = 0.01)
x = F.leaky_relu(self.bn3(self.conv3(x)), negative_slope = 0.01)
x = F.sigmoid(self.lin(self.flat(x)))
return x그리고 모델을 인스턴스 한 뒤 optimizer를 정의해줍니다.
# Instantiating the networks
G = Gen(ZDIM).apply(weights_init).to(device)
D = Dis(IMG_SIZE).apply(weights_init).to(device)# Defining solver to do the mini batch stochastic gradient descent one for each network
G_solver = opt.Adam(G.parameters(), lr=LR, betas=(BETA1, 0.999))
D_solver = opt.Adam(D.parameters(), lr=LR, betas=(BETA1, 0.999))이제 두 모델을 동시에 학습을 진행합니다.
# Defining the training for loop
import time
start = time.time()
for epoch in range(EPOCHS):
print("Running epoch {}...".format(epoch))
G_loss_run = 0.0
D_loss_run = 0.0
#steps for discriminator at each epoch is set to 3
for i,data in tqdm(enumerate(trainloader)):
X, _ = data
X = X.to(device)
BATCHSIZE = X.shape[0]
# Definig labels for real (1s) and fake (0s) images
one_labels = torch.ones(BATCHSIZE, 1).to(device)
zero_labels = torch.zeros(BATCHSIZE, 1).to(device)
# Random normal distribution for each image
z = torch.randn(BATCHSIZE, ZDIM).to(device)
# Feed forward in discriminator both
# fake and real images
D_real = D(X)
# fakes = G(z)
D_fake = D(G(z))
# Defining the loss for Discriminator
D_real_loss = F.binary_cross_entropy(D_real, one_labels)
D_fake_loss = F.binary_cross_entropy(D_fake, zero_labels)
D_loss = D_fake_loss + D_real_loss
# backward propagation for discriminator
D_solver.zero_grad()
D_loss.backward()
D_solver.step()
# Feed forward for generator
z = torch.randn(BATCHSIZE, ZDIM).to(device)
D_fake = D(G(z))
# loss function of generator
G_loss = F.binary_cross_entropy(D_fake, one_labels)
# backward propagation for generator
G_solver.zero_grad()
G_loss.backward()
G_solver.step()
G_loss_run += G_loss.item()
D_loss_run += D_loss.item()
# printing loss after each epoch
print('Epoch:{}, G_loss:{}, D_loss:{}'.format(epoch, G_loss_run/(i+1), D_loss_run/(i+1) ))
# Plotting fake images generated after each epoch by generator
samples = G(z).detach()
samples = samples.view(samples.size(0), 1, 28, 28)
imview(samples)
print("Training time: {}".format((time.time()-start)/60))위 코드를 좀 더 자세하게 분석해보도록 하겠습니다.
# Definig labels for real (1s) and fake (0s) images
one_labels = torch.ones(BATCHSIZE, 1).to(device)
zero_labels = torch.zeros(BATCHSIZE, 1).to(device)이 부분은 배치 사이즈만큼 1인 벡터와 0인 벡터를 생성하는 부분입니다. 1은 Real 데이터, 0은 Fake 데이터를 위한 레이블입니다.
# Random normal distribution for each image
z = torch.randn(BATCHSIZE, ZDIM).to(device)기본적으로 GAN에서는 생성 모델에게 입력 벡터를 줄 때 노이즈 벡터를 줍니다. 이때, 노이즈는 정규 분포를 따릅니다. 생성 모델은 이 노이즈 벡터를 입력받아 적절학 학습을 진행할 것입니다.
# Feed forward in discriminator both
# fake and real images
D_real = D(X)
# fakes = G(z)
D_fake = D(G(z))$X$는 Real 데이터이고 $G(z)$는 Fake 데이터임을 기억하시면 이해가 빠르실겁니다. 판단 모델은 실제 데이터와 가짜 데이터를 받고 각 데이터가 실제 데이터인지 가짜 데이터인지를 판단합니다.
# Defining the loss for Discriminator
D_real_loss = F.binary_cross_entropy(D_real, one_labels)
D_fake_loss = F.binary_cross_entropy(D_fake, zero_labels)
D_loss = D_fake_loss + D_real_loss
# backward propagation for discriminator
D_solver.zero_grad()
D_loss.backward()
D_solver.step()이 부분은 단순히 실제인데 가짜로 판단하면 손실이 증가하는 D_real_loss와 가짜인데 실제 데이터로 판단하면 손실이 증가하는 D_fake_loss로 구성되어 있습니다. 판단 모델은 이 두 가지 손실을 하나로 사용하며 학습을 진행합니다. 여기까지는 판단 모델을 위한 Feed forward 였다면 이번에는 생성 모델을 위한 Feed forward를 진행합니다.
# Feed forward for generator
z = torch.randn(BATCHSIZE, ZDIM).to(device)
D_fake = D(G(z))이 부분이 생성 모델을 위한 Feed forward 입니다. 노이즈 벡터를 생성한 뒤 이전에 학습을 한번 진행한 판단 모델을 이용해서 이 데이터가 가짜인 정도를 반환합니다.
# loss function of generator
G_loss = F.binary_cross_entropy(D_fake, one_labels)방금 생성 모델의 목표는 판단 모델이 이 데이터가 진짜라고 판단하는 정도를 높이는 것이라고 하였습니다. 따라서 판단 모델이 가짜인 정도와 one_labels와의 binary_cross_entropy를 생성 모델의 손실로 사용합니다.
# backward propagation for generator
G_solver.zero_grad()
G_loss.backward()
G_solver.step()생성 모델의 손실을 바탕으로 back propagation을 진행합니다. 이제 결과를 보도록 하겠습니다.

위 사진은 첫번째로 생성 모델이 새롭게 만든 데이터입니다. 처음에 보여드린 실제 데이터와 비교하면 차이가 극명하게 존재합니다. 이제 최종적으로 학습된 생성 모델의 결과를 보면 아래와 같습니다.

바로 위의 사진과 비교해보면 굉장히 큰 발전이라고 볼 수 있습니다. 오늘은 이렇게 DCGAN을 간단하게 구현해보았습니다. 다음 포스팅에서는 더 재밌고 흥미로운 응용을 소개해드리도록 하겠습니다.